图应用开发
语法介绍
语法编写规范
语法示例
CREATE GRAPH [ IF NOT EXISTS ] <name>
[ PARTITION_NUM = <integer> ]
[ COMMENT = <string> ]
[ CHARSET = {UTF8 | UTF8MB4 | GBK | GB2312 | GB18030} ];
详细说明
大写单词: 关键字。例如:CREATE,GRAPH。< >:语法片段或子句。例如:<name>,<integer>。[ ]:方括号内的内容是可选的。例如:[IF NOT EXISTS]表示该片段可以省略。[ ]...:方括号后跟省略号表示该片段可以出现零次或多次。|:选择符,表示需要从提供的选项中选择一个。例如:{UTF8 | UTF8MB4 | GBK | GB2312 | GB18030}表示需要从这几种字符集中选择一个。
语法介绍
数据类型
ArcGraph 图数据库中支持的属性数据类型如下。
| 英文 | 中文 | 说明 |
|---|---|---|
| Byte | 字节类型 | 用于表示二进制数据或存储小的整数值,包括 BYTE。 |
| Integer | 整数 | 用于存储整数数据,包括 INT32、INT64 和 BIGINT。 |
| Float | 单精度浮点数 | 用于存储小数数据,包括 FLOAT。它遵循 IEEE-754 浮点数标准,提供约 7 位十进制有效数字的精度。 |
| Double | 双精度浮点数 | 用于存储非常大或非常小的浮点数值的数据类型,包括 DOUBLE。它遵循 IEEE-754 浮点数标准,提供约 16 位十进制有效数字的精度。 |
| Boolean | 布尔值 | 用于存储布尔值(True/False),包括 BOOL 或 BOOLEAN。 |
| Timestamp | 时间戳 | 用于存储日期和时间数据,包括 TIMESTAMP。 |
| Date | 日期 | 用于存储日期数据,包括 DATE。 |
| Time | 时间 | 用于存储时间数据,包括 TIME。 |
| DateTime | 日期时间 | 用于存储日期和时间数据,包括 DATETIME。 |
| JSON | - | 用于存储结构化的复杂数据,包括 JSON。 说明: 当对该数据类型的属性创建索引时,应使用 ->> 操作符明确指定 JSON 路径,例如 idx_person(name->>'$.last_name')。 |
| String | 字符串 | 用于存储文本数据,包括 String。 |
| UUID | 通用唯一标识符 | 是一个 128 位长的标识符,通常用于在分布式系统中唯一标识实体,包括 UUID。 说明: 不支持对该数据类型的属性创建索引。 |
| Array | 数组数据类型 | 数组数据类型是一种用于存储和操作一组有序元素的数据结构。在图数据库中,数组数据类型可以作为点或边的属性,以存储相同类型的多个值或其他需要按顺序存储的数据。语法定义如下:
不支持对该数据类型的属性创建索引。 |
| BigDecimal | 高精度小数类型 | 用于存储和处理高精度的小数数值,遵循 BIGDECIMAL(prec,scale) 规范。其中,prec 表示总位数精度,取值范围是[10, 50];scale 表示小数部分的刻度,取值范围是[0, 30]。默认精度设置为 BIGDECIMAL(35, 18)。说明: - 允许用户自定义精度范围,当数值超出指定的范围时系统会截断多余部分并以 0 填充,对于超出范围的第一位,系统将根据四舍五入原则进行处理,确保数值在指定精度内以精确格式展示。 - 该类型支持从 String 到 BigDecimal 的隐式类型转换,便于在插入语句中直接使用字符串表示小数,如 INSERT (:sample1 {id: 1, val: '124567890.098765438978967987'});。-不支持对该数据类型的属性创建索引。 -仅 ArcGraph >= v2.1.1 版本支持此类型。 |
| ST_GEOMETRY | 地理空间类型 | 用于存储地理空间数据的数据类型。 说明: - 仅 ArcGraph >= v2.1.2 版本支持此类型。 - ST_GEOMETRY 数据类型上仅支持创建空间数据索引( SPATIAL INDEX)。 |
ArcGraph 图数据库中支持的非属性数据类型如下。
| 英文 | 中文 | 说明 |
|---|---|---|
| List | 列表数据类型 | 用于存储一组有序的元素,元素可以是任意数据类型。在 ArcGraph 图数据库中,列表数据类型由“[]”符号和多个元素组成,各个元素间使用英文逗号(,)分隔。请注意,列表数据类型不可以作为点或边的属性。 |
模式
ArcGraph 图数据库对 Cypher 查询语言中的模式(Patterns)提供了广泛的支持,以下将介绍 ArcGraph 图数据库中常用的几种模式。
| 分类 | 说明 |
|---|---|
| Nodes | 表示图数据库中的点,在 ArcGraph 图数据库中用 Vertex(点)表示。 |
| Related nodes | 表示多个点以及它们之间的关系。如 (a)-[]->(b)。 |
| Specifiying properties | 表示在点或边上使用属性以进行精确匹配或查询。 |
| Relationships | 表示图数据库中各点间的关联关系,在 ArcGraph 图数据库中用 Edge(边)表示。 |
| Variable-length patterns | 表示允许使用可变长度的模式来匹配具有特定长度的路径。 |
| Path variable | 表示允许将匹配到的整个路径作为一个整体进行操作或返回。 |
-
描述点(Vertex)
表达方式 说明 ()匿名的点 (John)指定变量名的点 (:person)指定点类型的点 (John:person)指定变量名和点类型的点 (John:person {name: "John"})有变量名、点类型和属性值的点 (John:person {name: "John", age: 30})有变量名、点类型和联合属性值的点 -
描述边(Edge)
使用
一对短横线(即“--”)表示一个无方向边,有方向的边则在其中一端加上一个箭头(即“<--”或“-->”)。方括号表达式“[…]”可用于添加详情,表达式中可以包含变量、属性、类型等信息。边的常见表达方式如下:表达方式 说明 --无向边 -->正向边 <--反向边 -[r]->指定变量名的正向边 -[:like]->指定边类型的正向边 -[r:like]->带有变量名和边类型的正向边 -[r:like {name: "喜欢"}]->带有变量名、边类型、属性值的边
在 ArcGraph 图数据库中,使用类 Cypher 代码将两个简单的模式(Pattern)连接在一起,示例如下:
(:person) -[:like]-> (:person)
子句
ArcGraph 图数据库支持 Cypher 查询语言中的多种子句(Clauses),这些子句为数据查询提供了强大的功能。以下将介绍 ArcGraph 图数据库中常用的几种子句,关于子句的详细�介绍请参见 子句 章节。
| 子句 | 说明 |
|---|---|
MATCH | 用于根据指定的模式(pattern)查询图。详情请参见 基本查询 章节。 |
OPTIONAL MATCH | 与 MATCH 子句类似,但不同之处在于,当查询结果为空时,该子句会对缺失部分返回 null 值。 |
RETURN | 用于指定查询结果的返回格式。详情请参见 RETURN 章节。 |
WITH | 用于在查询过程中将中间结果传递给后续的查询子句,即通过 WITH 子句,将一个查询的输出直接作为下一个查询的输入。详情请参见 WITH 章节。 |
UNWIND | 用于将列表元素展开为独立的记录序列。详情请参见 UNWIND 章节。 |
WHERE | 用于指定过滤条件,可以与 MATCH、OPTIONAL MATCH 或 WITH 子句组合使用。详情请参见 WHERE 章节。 |
ORDER BY | 用于对(中间)结果进行排序,可以与 RETURN 或 WITH 子句组合使用。详情请参见 ORDER BY 章节。 |
SKIP | 用于跳过查询结果中的前 n 个记录。详情请参见 SKIP 章节。 |
LIMIT | 用于限制查询结果返回的个数。详情请参见 LIMIT 章节。 |
CREATE | 用于在图数据库中创建点、边等。 |
DELETE | 用于删除指定的点、边等。 |
SET | 用于修改已存在的点、边的属性值或类型。 |
CALL[...YIELD] | 用于调用图数据库内置过程。 |
UNION | 用于合并多个查询的结果。详情请参见 UNION 章节。 |
表达式
ArcGraph 图数据库支持 Cypher 查询语言中的多种表达式(Expressions),以下将介绍 ArcGraph 图数据库中常用的几种表达式,关于表达式的详细介绍请参见 表达式 章节。
| 表达式 | 说明 |
|---|---|
| 常量 | 常量表示固定的数值或文本。例如,数字 42、字符��串 "hello"、布尔值 true 或 false 等。 |
| 变量 | 变量是一种用于指代图数据库中点、边及其属性值的标识符。例如,n:person 中,n 是一个变量,它指代了一个 person 类型。 |
| 属性 | 属性是对象的一部分,用于描述对象的特性,例如,一个 Person 对象可能有一个 name 属性。 |
| 函数调用 | 函数调用是执行特定函数并向其传递必要参数以执行特定任务的过程。例如,sum(2, 3) 是一个函数调用,其中 sum 是一个函数,2 和 3 是参数。 |
| 聚合函数 | 聚合函数是用于对一组值做聚合运算的函数。例如,SUM()、AVG()、MAX()、MIN() 和 COUNT() 。 |
| 计算表达式 | 计算表达式由数据和运算符组成,用于执行计算并返回结果,例如,2 + 3 * 4 是一个计算表达式。 |
| 谓词表达式 | 谓词表达式返回一个布尔值(true 或 false),通常用于条件判断。例如,x > 10 是一个谓词表达式。 |
操作符
ArcGraph 图数据库支持 Cypher 查询语言中的多种操作符,以满足用户对于数据查询、计算、比较和逻辑判断的需求。以下将介绍 ArcGraph 图数据库中常用的几种操作符。
| 操作符 | 描述 |
|---|---|
| 通用操作符 | 用于执行基本的查询操作,如 DISTINCT(用于返回唯一不同的值)、.(用于属性访问)。 |
| 数学运算操作符 | 用于在 Cypher 查询中执行基本的数学运算,如 + (加法)、-(减法)、*(乘法)、/(除法)和 %(取模)。 |
| 比较运算操作符 | 用于在 Cypher 查询中比较两个值,如 =(等于)、<>(不等于)、!=(不等于)、<(小于)、>(大于)、<=(小于等于)和 >=(大于等于)。 |
| 字符串比较操作符 | 用于处理字符串类型的比较操作,如 STARTS WITH(用于检查字符串是否以指定子串开始)、ENDS WITH(用于检查字符串是否以指定子串结束)或 CONTAINS(用于检查字符串是否包含指定子串)。 |
| 布尔运算操作符 | 用于在 Cypher 查询中执行逻辑运算,如 AND(逻辑与)、OR(逻辑或)和 NOT(逻辑非)。 |
| 字符串操作符 | 主要用于处理字符串类型的值,如 +(用于字符串连接操作)和 IN(用于检查一个值是否存在于一个字符串列表中)。 |
内置函数
ArcGraph 图数据库支持丰富的内置函数,这些函数为用户提供了强大的数据处理能力。以下将介绍 ArcGraph 图数据库中常用的几种内置函数,关于内置函数的详细介绍请参见 内置函数 章节。
| 函数类型 | 说明 |
|---|---|
| 字符串函数 | 对字符串进行操作的函数,如 concat()、concat_ws() 等。详情请参见 字符串函数 章节。 |
| 数学函数 | 包括常见的数学运算,如 abs()、cos() 等。详情请参见 数学函数 章节。 |
| 日期时间函数 | 提供关于时间和日期处理的函数,如 timestamp()、date() 等,详情请参见 日期时间函数 章节。 |
| 工具函数 | 提供一些通用函数,如 randomUUID() 等,详情请参见 工具函数 章节。 |
| 聚合函数 | 用于对一组值进行计算,并返回单个值作为结果的函数,如 avg()、sum() 等,详情请参见 聚合函数 章节。 |
| Graph 函数 | 用于图数据处理的函数,如 id()、pk() 等,详情请参见 Graph 函数 章节。 |
| 转换函数 | 用户数据类型之间相互转换的函数,如 toBoolean()、toFloat() 等,详情请参见 转换函数 章节。 |
| 对数函数 | 用于对数计算的函数,如 log()、log10() 等,详情请参见 对数函数 章节。 |
| Partial 函数 | 用于数据脱敏的函数,详情请参见 Partial 函数 章节。 |
| 路径函数 | 用于查询和分析路径的函数,如 startNode()、endNode() 等,详情请参见 路径函数 章节。 |
| 列表与数组函数 | 用于对列表和数组进行操作的函数,如 size()、head() 等,详情请参见 列表/数组函数 章节。 |
| 条件表达式函数 | 主要用于根据条件判断返回不同的结果,详情请参见 条件表达式函数 章节。 |
字符集和排序规则
字符集和排序规则是数据库中字符数据处理的两个重要概念。了解字符集和排序规则对于正确处理数据库中的字符数据至关重要。
- 字符集是计算机系统中用于编码字符的集合,不同的字符集可能包含不同的字符和符号,并且使用不同的编码规则。在图数据库中字符集用于存储和表示文本数据的一组字符编码规则。ArcGraph 系统默认编码方式为 UTF8mb4。
- 排序规则是字符集中用于比较每个字符的一套规则,它决定了字符在数据库查询中的比较和排序行为。每种字符集可对应一到多个排序规则,每种排序规则对应一种字符集。在涉及字符串比较或排序的操作时,系统会调用对应指定的排序规则算法来确保正确的处理结果。
支持类型
ArcGraph 支持的字符集及排序规则如下:
字符集
| 类型 | 说明 |
|---|---|
| UTF-8 | UTF-8(Unicode Transformation Format-8 bits)是 UNICODE 的变长编码方式,用于表示 Unicode 字符集中的字符。UTF-8 以 8 位字节为单元对 Unicode 字符集进行编码,不使用大尾序和小尾序形式,每个使用 UTF-8 存储的字符,除了第一��个字节外,其余字节的前两个比特都是以"10"开始,使文字处理器能快速找出每个字符的开始位置。为了与 ASCII 码兼容,UTF-8 使用可变长度字节来存储 Unicode,用 1~4 个字节表示一个 Unicode 字符编码,可以表示 Unicode 的所有字符。 |
| GBK/GB18030 | GB18030(全称为:国家标准GB18030-2005《信息技术中文编码字符集》)是中华人民共和国当前最新的内码字集,兼容 GB2312 和 GBK,支持 Unicode 的全部汉字,收录 70244 个汉字。采用多字节编码,支持少数民族文字和日韩汉字,最多可定义 161 万个字符。其字节结构包括单字节、双字节和四字节。 |
排序规则
| 排序规则 | 排序结果 | 对应字符集 |
|---|---|---|
| gb18030_bin | gb18030 二进制编码排序 | gb18030 |
| gb18030_chinese_ci | 按拼音排序 | gb18030 |
| gbk_bin | gbk 二进制编码排序 | gbk |
| gbk_chinese_ci | 按拼音排序 | gbk |
| utf8_bin | utf8 二进制编码排序 | utf8 |
| utf8_pinyin | utf8编码拼音排序 | utf8 |
设置字符集/排序规则
ArcGraph 仅支持在图中设置字符集和对应的排序规则,且设置后不支持修改。
语法详情请参见 创建图 章节。
说明:
- 设置的字符集和排序规则需一一对应,例如字符集设置为
GBK,则排序规则不可设置为UTF8_BIN。对应情况请参见 支持类型 章节中的“排序规则”表。 - 设置的字符集和排序规则大小写不敏感。
示例
创建图 graph 并设置字符集为 GBK,排序规则为 GBK_BIN,命令如下:
CREATE GRAPH IF NOT EXISTS graph
CHARSET = GBK
COLLATION = GBK_BIN
COMMENT = '新图';
DDL 与 Online DDL
在大多数数据库系统中,执行 DDL 操作(如添加表结构、修改列属性等)时,为了维护数据的一致性和完整性,系统通常会暂时禁止或限制并发的 DML 操作(如数据的增、删、改、查)。对于包含大量数据的表而言,这种 DDL 操作可能会导致 DML 操作长时间被阻塞,从而影响业务流畅性和客户体验。为了解决这一问题,ArcGraph 图数据库自 v2.1.2 版本起支持 Online DDL(即在线数据定义语言)操作,有效降低了 DDL 操作对 DML 操作的影响。
Online DDL
Online DDL 操作通过对 DDL 执行流程的深入优化和改进,实现了在操作执行期间几乎不阻塞或仅在极短时间内阻塞 DML 操作,从而保障了 ArcGraph 图数据库的高可用性和业务的连续无中断运行。
优势与特点
- 提高可用性
在调整图数据结构时,Online DDL 允许 ArcGraph 图数据库持续处理查询和更新请求,从而大幅减少了因 DDL 操作导致的系统停机时间,确保了业务的连续运行。 - 支持复杂操作
Online DDL 操作(如添加索引、修改属性列等)可以在不影响业务正常运行的前提下,在后台静默执行,极大地增强了数据库维护的灵活性与效率。 - 优化用户体验
用户在 ArcGraph 图数据库维护期间,仍能正常使用应用程序,提高了用户体验。
支持的操作
- 清空/删除图:自 ArcGraph 图数据库 v2.1.2 版本起,将
TRUNCATE GRAPH和DROP GRAPH命令由 DDL 操作升级为 Online DDL 操作,详情请参见 删除图 章节。 - 删除点/边类型:自 ArcGraph 图数据库 v2.1.2 版本起,将
Drop Vertex和Drop Edge命令由 DDL 操作升级为 Online DDL 操作,详情请参见 删除点类型/删除边类型 章节。 - 删除索引:自 ArcGraph 图数据库 v2.1.2 版本起,将
Drop Index命令由 DDL 操作升级为 Online DDL 操作,详情请参见 删除索引 章节。 - 创建索引:自 ArcGraph 图数据库 v2.1.2 版本起,支持通过 Online DDL 操作执行
Create Index命令创建索引,详情请参见 创建索引 章节。 - 修改点/边类型:自 ArcGraph 图数据库 v2.1.2 版本起,支持通过 Online DDL 操作修改除属性名称外的其他点/边类型属性,详情请参见 修改点类型/修改边类型 章节。
Schema GC 机制
在 Online DDL 执行过程中,ArcGraph 图数据库采用 Schema GC(Schema Garbage Collection)机制,尽可能的减少 DDL 语句对锁等系统资源的占用。该机制不仅实时清除内存中冗余的缓存数据,实现高效的逻辑删除,还针对磁盘上的物理数据实施延迟清理策略,选择合适时机再进行处理,从而确保数据管理的灵活性与系统资源的优化利用。
Schema GC 通过版本控制来确保数据的一致性和可追踪性。每当执行受 Schema GC 支持的操作时,系统都会相应的增加 Schema 的版本号,并记录操作时间和状态变化。在查询操作中,系统会根据当前的 Schema 版本和状态,对存储在键值存储(KV)中的数据进行实时转换,合并内存中的最新数据后返回至 ArcGraph 图数据库的客户端,以确保查询结果的准确性和时效性。
Schema GC 执行策略
在执行 Schema GC 操作时,系统遵循以下检查策略:
- 检查图是否被删除。
- 检查图中点和边类型的 Schema 版本数量。
- 检查图中��是否存在被删除的索引。
- 检查图中边类型上是否存在被删除的关联点类型。
- 检查被删除的点和边类型个数。
支持的操作
Schema GC 支持的操作与 Online DDL相同,详情请参见 支持的操作 章节。
Schema GC 参数介绍
Schema GC 的行为可以通过相关参数进行配置,以下是这些参数及其默认值的详细说明:
| 参数 | 说明 | 默认值 | 单位 |
|---|---|---|---|
meta_schema_gc_interval | 设置 ArcGraph 图数据库定期检查是否需要执行 Schema GC 操作的周期。 | 43200 (即 12 小时) | 秒 |
meta_schema_grace_period | 设置图及其内部所有 Schema 修改后等待执行 Schema GC 操作的阈值。 | 3600 (即 1 小时) | 秒 |
meta_schema_version_gc_limit | 设置图内点/边类型 Schema 版本的最大阈值。超过该阈值时,系统将对该图进行 Schema GC 操作,即将存储在键值存储(KV)上的数据变更到最新的版本。 | 6 | 个 |
meta_dropped_schema_gc_limit | 设置图中被删除的点/边类型或关联点类型的最大阈值。超过该阈值时,系统将对该图进行 Schema GC 操作,即将存储在键值存储(KV)上的脏数据删除。 | 3 | 个 |
查看与修改配置
- 查看配置
使用SHOW CONFIGS LIKE '%schema%';命令查看 Schema GC 相关配置,详情请参见 SHOW CONFIGS 章节。 - 修改配置
使用ALTER CONFIG命令修改 Schema GC 相关配置,详情请参见 更改系统配置项 章节。
示例 1
查看 Schema GC 相关配置。命令如下:
SHOW CONFIGS LIKE '%schema%';
返回结果示例如下:
+-------------------------------+-------+--------------+-----------+----------------------------------------------------+
| config_name | value | modify_level | server_id | description |
+===============================+=======+==============+===========+====================================================+
| meta_dropped_schema_gc_limit | 3 | DYNAMIC | 1 | meta dropped schema GC policy |
+-------------------------------+-------+--------------+-----------+----------------------------------------------------+
| meta_schema_gc_interval | 43200 | DYNAMIC | 1 | meta schema GC interval |
+-------------------------------+-------+--------------+-----------+----------------------------------------------------+
| meta_schema_grace_period | 3600 | DYNAMIC | 1 | meta schema grace period before applying gc policy |
+-------------------------------+-------+--------------+-----------+----------------------------------------------------+
| meta_schema_version_gc_limit | 6 | DYNAMIC | 1 | meta schema data version GC policy |
+-------------------------------+-------+--------------+-----------+----------------------------------------------------+
示例 2
修改 Schema GC 参数 meta_schema_gc_interval 配置。命令如下:
ALTER CONFIG meta_schema_gc_interval = 40000;
图
图是由点、边组成的图结构,它由一系列的点、边、索引 Schema 信息以及对应的数据组成。支持对图进行分区管理。
前提条件
在开始操作前,请确保当前登录用户拥有执行此操作所需权限的角色。有关权限的详细说明,详情请参见 权限 章节。
创建图
使用 CREATE GRAPH 命令创建图。
语法
create_graph ::= CREATE GRAPH [ IF NOT EXISTS ] <graph_name>
[( PARTITION_NUM = < integer> )]
[ COMMENT = < string > ]
[ CHARSET = {UTF8 | GBK | GB18030} ]
[ COLLATION = {UTF8_BIN | UTF8_PINYIN | GB18030_BIN | GB18030_CHINESE_CI | GBK_BIN | GBK_CHINESE_CI} ];
详细说明
| 参数 | 说明 |
|---|---|
[IF NOT EXISTS] | (可选)在创建图时,用于检测指定的图是否已存在于当前 ArcGraph 图数据库中。若不存在则创建图,若已存在,则不进行任何操作。仅通过图名称进行检测,若省略,则不检测。 |
<graph_name> | 设置图名称。在同一个 ArcGraph 集群中,图名称必须是唯一的且命名时应遵循特定的规则和要求,命名规则详情请参见 命名规则 章节。 |
PARTITION_NUM | (可选)在创建图时可以指定的分区数量。单机版建议不要设置此参数。如果确实需要设置,请设置为 partition_num=1,此时指定的 HASH 策略将失效。 |
COMMENT | (可选)为了方便用户区分不同的图,可以用 COMMENT 字段增加有意义的信息。 |
CHARSET | (可选)指定该图的字符集,默认为 UTF8。设置后不支持修改,请谨慎操作。字符集详情请参见 字符集和排序规则 章节。 |
COLLATION | (可选)指定该图的字符集排序规则,默认为 UTF8_BIN。设置后不支持修改,请谨慎操作。字符集排序规则详情请参见 字符集和排序规则 章节。 |
示例
创建一个名为“new1"的图,命令如下:
CREATE GRAPH IF NOT EXISTS new1
CHARSET = utf8
COMMENT = '新图';
切换/使用图
使用 USE GRAPH 命令,从当前位置,切换到指定图中。
语法
use_graph ::= USE [GRAPH] <graph_name>;
详细说明
| 参数 | 说明 |
|---|---|
[GRAPH] | (可选)关键字,用于明确指定将要操作的类型是图。 |
<graph_name> | 图名称,用于指定将要操作的图的名称。 |
示例
在当前图中切换到“new1”图中,命令如下:
USE GRAPH new1;
修改图名称
使用 RENAME GRAPH 命令,对一个图进行重命名操作。
语法
rename_graph ::= RENAME GRAPH <graph_name1> TO <graph_name2>;
详细说明
| 参数 | 说明 |
|---|---|
<graph_name1> | 当前图名称,用于指定将要操作的图的名称。 |
<graph_name2> | 修改后的图名称,请确保修改后的名称在当前 ArcGraph 集群中,是唯一的且符合命名规则,命名规则详情请参见 命名规则 章节。 |
示例
在当前图中将图名称由“new1”改为“new2”,命令如下:
RENAME GRAPH new1 to new2;
查看图详情
使用 DESC GRAPH 命令查看指定图的详细信息。若需了解更多与图相关的查看操作,请参见 SHOW GRAPHS 章节。
语法
desc_graph ::= DESC GRAPH <graph_name> [ALL|FULL];
详细说明
| 参数 | 说明 |
|---|---|
<graph_name> | 图名称,用于指定将要操作的图的名称。 |
[ALL|FULL] | (可选)用于展示指定图的所有信息或详细信息,若省略,则只展示图的基本信息。 - ALL:用于展示指定图的所有信息,包括该图的详细信息以及该图所包含的点类型和边类型的信息。- FULL:用于展示指定图的详细信息,包括图 ID、创建时间戳等。请注意,仅 ArcGraph >= v2.1.1 版本支持此参数。 |
示例 1
查看图“new1”的基本信息,命令如下:
DESC GRAPH new1;
返回结果示例如下:
+------+---------------+-------------+---------+----------+--------+---------+
| name | partition_num | replica_num | charset | collate | status | comment |
+======+===============+=============+=========+==========+========+=========+
| new1 | 1 | 1 | utf8 | utf8_bin | Normal | 新图 |
+------+---------------+-------------+---------+----------+--------+---------+
示例 2
查看图“new1”的详细信息,命令如下:
DESC GRAPH new1 FULL;
返回结果示例如下:
+---------------------------------+
| graph |
+=================================+
| GraphMsg { |
| graph_id: 1026, |
| graph_name: "new1", |
| charset_name: "utf8", |
| collate_name: "utf8_bin", |
| comment: "新图", |
| create_time: 1711360120473, |
| partition_number: 1, |
| replica_number: 1, |
| status: "Normal", |
| version: 0, |
| } |
+---------------------------------+
示例 3
查看图“new1_test”的所有信息,包括其包含的点类型、边类型信息。命令如下:
DESC GRAPH new1_test ALL;
返回结果示例如下:
+---------------------------------+--------------------------------------+--------------------------------------+
| graph | vertex | edge |
+=================================+======================================+======================================+
| GraphMsg { | VertexSchemaMsg { | EdgeSchemaMsg { |
| graph_id: 1028, | graph_id: 1028, | graph_id: 1028, |
| graph_name: "new1_test", | vertex_type_id: 1, | edge_type_id: 1, |
| charset_name: "utf8", | vertex_type_name: "person", | edge_type_name: "like", |
| collate_name: "utf8_bin", | schema_version: 0, | schema_version: 0, |
| comment: "新图", | data_version: 0, | data_version: 0, |
| create_time: 1718613130383, | status: "Normal", | status: "Normal", |
| partition_number: 1, | key_type: "int64", | properties: [ |
| replica_number: 1, | key_length: 8, | PropertyMsg { |
| status: "Normal", | properties: [ | property_id: 5, |
| version: 0, | PropertyMsg { | property_name: "name", |
| } | property_id: 1, | property_type: "string", |
| | property_name: "_oid", | type_length: 0, |
| | property_type: "uint64", | nullable: false, |
| | type_length: 8, | primary_key: false, |
| | nullable: false, | default_value: Some( |
| | primary_key: false, | ValueMsg { |
| | default_value: Some( | object: None, |
| | ValueMsg { | }, |
| | object: None, | ), |
| | }, | index_num: 0, |
| | ), | order: 0, |
| | index_num: 0, | comment: "喜欢", |
| | order: 0, | is_unique: false, |
| | comment: "", | is_full_text: false, |
| | is_unique: true, | v_index_type: None, |
| | is_full_text: false, | is_oid: false, |
| | v_index_type: None, | }, |
| | is_oid: true, | PropertyMsg { |
| | }, | property_id: 6, |
| | PropertyMsg { | property_name: "since", |
| | property_id: 2, | property_type: "int64", |
| | property_name: "id", | type_length: 8, |
| | property_type: "int64", | nullable: true, |
| | type_length: 8, | primary_key: false, |
| | nullable: false, | default_value: Some( |
| | primary_key: true, | ValueMsg { |
| | default_value: Some( | object: Some( |
| | ValueMsg { | ValueI64( |
| | object: None, | 2020, |
| | }, | ), |
| | ), | ), |
| | index_num: 0, | }, |
| | order: 0, | ), |
| | comment: "", | index_num: 0, |
| | is_unique: true, | order: 0, |
| | is_full_text: false, | comment: "开始时间", |
| | v_index_type: None, | is_unique: false, |
| | is_oid: false, | is_full_text: false, |
| | }, | v_index_type: None, |
| | PropertyMsg { | is_oid: false, |
| | property_id: 3, | }, |
| | property_name: "name", | ], |
| | property_type: "string", | vertex_type_pair: [ |
| | type_length: 0, | VertexTypePairMsg { |
| | nullable: true, | from_id: 1, |
| | primary_key: false, | to_id: 1, |
| | default_value: Some( | status: "Normal", |
| | ValueMsg { | from_name: Some( |
| | object: None, | "person", |
| | }, | ), |
| | ), | to_name: Some( |
| | index_num: 0, | "person", |
| | order: 0, | ), |
| | comment: "姓名", | }, |
| | is_unique: false, | ], |
| | is_full_text: false, | partition_schema: Some( |
| | v_index_type: None, | PartitionSchemaMsg { |
| | is_oid: false, | method: "hash", |
| | }, | column: "_TYPE", |
| | PropertyMsg { | }, |
| | property_id: 4, | ), |
| | property_name: "age", | temporal: false, |
| | property_type: "int32", | comment: "测试Edge", |
| | type_length: 4, | indexes: [], |
| | nullable: false, | } |
| | primary_key: false, | |
| | default_value: Some( | |
| | ValueMsg { | |
| | object: Some( | |
| | ValueI32( | |
| | 16, | |
| | ), | |
| | ), | |
| | }, | |
| | ), | |
| | index_num: 0, | |
| | order: 0, | |
| | comment: "年龄", | |
| | is_unique: false, | |
| | is_full_text: false, | |
| | v_index_type: None, | |
| | is_oid: false, | |
| | }, | |
| | ], | |
| | partition_schema: Some( | |
| | PartitionSchemaMsg { | |
| | method: "hash", | |
| | column: "_TYPE", | |
| | }, | |
| | ), | |
| | temporal: false, | |
| | comment: "测试Vertex", | |
| | indexes: [], | |
| | } | |
+---------------------------------+--------------------------------------+--------------------------------------+
删除图
ArcGraph 支持通过下列方式删�除图及图中数据,请根据实际情况选择。数据一旦删除,无法恢复,请谨慎操作。
- 自 ArcGraph v2.1.2 版本起,该功能由 DDL 操作升级为 Online DDL 操作。
- 自 ArcGraph v2.1.2 版本起,执行
TRUNCATE GRAPH/DROP GRAPH命令成功后,数据将立即从 ArcGraph 图数据库中逻辑删除且不可见,但存储于磁盘上的物理数据需等 Schema GC 任务执行后才会被彻底删除。 - 自 ArcGraph v2.1.2 版本起,通过执行
SHOW FULL GRAPHS;命令可查看已删除但未回收的图。这些图的 ID 不变,但名字会被定义为_{name}_{timestamp}格式,如_new1_1724929262231783。
清空图
使用 TRUNCATE GRAPH 命令清空图数据,即仅删除图中的点边数据,保留图中点类型和边类型。该操作将彻底清除图中的所有点数据和边数据,请谨慎执行。
语法
TRUNCATE GRAPH [IF EXISTS] <graph_name>;
详细说明
| 参数 | 说明 |
|---|---|
<graph_name> | 图名称,用于指定将要操作的图的名称。 |
[IF EXISTS] | (可选)在清空图时,用于检测指定的图是否存在于当前 ArcGraph 图数据库中,若存在则清空图,若不存在则显示成功但不进行任何操作。仅通过图名��称进行检测,若省略,则不检测。 说明: 仅 ArcGraph >= v2.1.2 版本支持此参数。 |
示例 1
删除名为“new2”的图中的所有点数据和边数据,命令如下:
TRUNCATE GRAPH new2;
示例 2
当 ArcGraph >= v2.1.2 版本时,检查并清空名为“new2”的图。命令如下:
TRUNCATE GRAPH IF EXISTS new2;
删除所有数据
使用 DROP GRAPH 命令删除整个图,包括图中点类型、边类型、点数据、边数据等所有数据。这是一种破坏性操作,请谨慎执行。
语法
DROP GRAPH [IF EXISTS] <graph_name> [FORCE];
详细说明
| 参数 | 说明 |
|---|---|
[IF EXISTS] | (可选)在删除图时,用于检测指定的图是否存在于当前 ArcGraph 图数据库中,若存在则删除图,若不存在则显示成功但不进行任何操作。仅通过图名称进行检测,若省略,则不检测。 |
<graph_name> | 图名称,用于指定将要操作的图的名称。 |
[FORCE] | (可选)使用 FORCE 命令可强制删除图。若省略则可能会因为图的当前状态导致删除失败。 |
普通删除
示例
删除名为“new2”的图。
DROP GRAPH IF EXISTS new2;
强制删除
若图因当前状态无法正常删除时,可使用 FORCE 命令强制删除。
示例
强制删除名为“new2”的图,命令如下:
DROP GRAPH IF EXISTS new2 FORCE;
点类型
在 ArcGraph 图数据库中,点类型是用来定义一组拥有相同特征的点的模型,点类型的相关操作需要在图中进行。
前提条件
在开始操作前,请确保当前登录用户拥有执行此操作所需权限的角色。有关权限的详细说明,详情请参见 权限 章节。
创建点类型
使用 CREATE VERTEX 命令创建点类型,创建点类型时可同时创建相关索引。
语法
create_vertex ::= CREATE VERTEX [IF NOT EXISTS] <vertex_name>
( <vertex_body> [, <vertex_body>]... )
[PARTITION BY HASH ( _TYPE | _ID)]
[ COMMENT = < string > ];
vertex_body ::= <property_def>
| <embedded_index>;
property_def ::= { <primary_key> | <normal_property> };
primary_key ::= PRIMARY KEY <property_name> { STRING ( <integer> ) | INT64 } [MASKED [WITH ( FUNCTION = PARTIAL (<integer>, <string>, <integer>))]] [COMMENT <string>];
normal_property ::= <property_name> <property_type> [<nullable>] [MASKED [WITH ( FUNCTION = PARTIAL (<integer>, <string>, <integer>))]] [DEFAULT default_value] [COMMENT <string>];
property_type ::= { INT32 | INT64 | BOOLEAN ... };
nullable ::= [NOT] NULL;
embedded_index ::= [SPATIAL] INDEX <index_name> ( <index_property> [, <index_property>]... ) [UNIQUE];
index_property ::= <property_name> [->> json_path];
详细说明
| 参数 | 说明 |
|---|---|
[IF NOT EXISTS] | (可选)在创建点类型时,用于检测当前图中是否已存在该点类型。若不存在则创建点类型,若已存在,则不进行任何操作。仅通过点类型名称进行检测,不检测具体属性,若省略,则不检测。 |
<vertex_name> | 设置点类型名称。在同一个图中,点类型名称必须是唯一的且命名时应遵循特定的规则和要求,命名规则详情请参见 命名规则 章节。 |
<vertex_body> | 用于定义点类型的属性(<property_def>)和索引(<embedded_index>)信息,支持同时设置多个属性或索引,可用英文逗号(“,”)分隔。 |
<property_def> | 用于定义点类型的属性,支持定义主键属性(<primary_key>)和普通属性(<normal_property>)。 |
<primary_key> | 用于定义点类型的主键属性,每个点类型只能设置一个主键属性,该属性用于唯一标识该点类型。通过 pk() 函数可查询点的主键值,详情请参见 pk() 章节。支持设置以下数据类型:
|
<normal_property> | 用于定义点类型的普通属性,支持同时设置多个并用英文逗号(“,”)分隔。 |
<property_name> | 设置普通属性的名称。同一个点类型下属性名称必须是唯一的且命名时应遵循特定的规则和要求,命名规则详情请参见 命名规则 章节。 |
<property_type> | 定义属性的数据类型,支持 INT32、INT64 等多种数据类型,详情请参见 数据类型 章节。 |
<nullable> | (可选)表示指定属性是否可以为空。 - NOT NULL:表示该属性值不可为空。- NULL:表示该属性值可以为空,默认为 NULL。 |
<embedded_index> | 用于定义点类型的索引,以提高查询性能和数据检索速度。支持设置多种索引类型,详情请参见 索引 章节。 |
[SPATIAL] | (可选)表示该索引类型为空间数据索引,详情请参见 索引 章节。 说明: 仅 ArcGraph >= v2.1.3 版本支持。 |
<index_name> | 设置索引的名称。同一个点类型下索引名称必须是唯一的且命名时应遵循特定的规则和要求,命名规则详情请参见 命名规则 章节。 |
<index_property> | 定义被索引的属性,支持同时对多个属性进行索引并用英文逗号(“,”)分隔。 说明: - 若属性的数据类型为 Array、UUID 或 BigDecimal 类型,则不支持在该属性上创建索引。 - 若属性的数据类型为 JSON 类型,则在该属性上创建索引时应使用 ->> 操作符明确指定 JSON 路径,例如 idx_person(name->>'$.last_name')。 |
[UNIQUE] | (可选)表示该索引要求索引的属性值必须是唯一的。 |
[->> json_path] | (可选)是一种在 JSON 对象结构中定位和提取数据的查询语言。通过使用路径表达式,可以帮助我们轻松地在嵌套的 JSON 数据结构中定位和提取指定的数据,详情请参见 JSON 简介 章节。 |
[PARTITION BY HASH ( _TYPE|_ID)] | (可选)表明该点类型采用的分区方式,包括 HASH(_TYPE) 和 HASH(_ID)。如果想利用分布式查询提�升查询效率,建议采用 HASH(_ID)分区方式;如果点数量较少(<1百万),建议采用 HASH(_TYPE)分区方式。单机版建议不要设置此参数。如果确实需要设置,请设置为 partition_num=1,此时指定的 HASH 策略将失效。 |
COMMENT | (可选)为了方便用户区分不同的点类型,可以用 COMMENT 字段增加有意义的信息。 |
MASKED | (可选)表示查询时显示该字段值是否对某些用户进行隐藏部分值,如身份证号会隐藏中间几位个数。 |
[DEFAULT default_value] | (可选)用于定义属性的默认值,即当 INSERT 语句没有为列提供值情况下,该属性的值。 |
示例 1
在当前图中创建“person”点类型,命令如下:
CREATE VERTEX IF NOT EXISTS person
(
PRIMARY KEY id INT(64),
name STRING COMMENT '姓名',
age INT(32) NOT NULL DEFAULT '16' COMMENT '年龄',
INDEX name_index(name) UNIQUE
)
COMMENT = '测试Vertex';
示例 2
在当前图中创建包含 ARRAY 属性的“PersonArray”点类型,命令如下:
CREATE VERTEX IF NOT EXISTS PersonArray
(
PRIMARY KEY id INT(64),
name STRING COMMENT '姓名',
hobbies ARRAY(STRING) COMMENT '兴趣爱好列表'
)
COMMENT = '测试Vertex';
示例 3
当 ArcGraph >= v2.1.3 版本时,在当前图中创建包含空间数据索引的点类型,命令如下:
CREATE VERTEX location (
PRIMARY KEY id INT(64),
position ST_GEOMETRY(0),
SPATIAL INDEX spatial_index_vertex(position)
)
COMMENT = '测试Vertex';
修改点类型
使用 ALTER VERTEX 命令修改当前图中的点类型,ArcGraph 图数据库版本不同支持的修改功能略有不同,请以实际情况为准。
修改点类型名称
修改点类型的名称,修改后的新名称不能是当前图中已存在的点类型名称,命名规则详情请参见 命名规则 章节。
语法
rename_vertex ::= ALTER VERTEX <vertex_name> RENAME TO <vertex_name>;
示例
在当前图中将点类型名称“person”修改为“women”,命令如下:
ALTER VERTEX person RENAME TO women;
管理点类型属性
在当前图中使用 ALTER VERTEX 命令管理点类型中的属性。
增加属性
为点类型增加属性,可以丰富点类型的数据模型,使其更好地满足业务需求。
语法
alter_vertex_properties ::= ALTER VERTEX <vertex_name> <add_property_body>
add_property_body ::= ADD [COLUMN] <property_name> <property_type> [NULL | NOT NULL] [DEFAULT default_value] [COMMENT < string >]
[, ADD [COLUMN] <property_name> <property_type> [NULL | NOT NULL] [DEFAULT default_value] [COMMENT < string >]]...;
详细说明
| 参数 | 说明 |
|---|---|
<vertex_name> | 用于指定将要增加属性的点类型的名称。需要指定正确的点类型名称,以确保属性被添加到正确的对象上。 |
[COLUMN] | (可选)用于指明将要添加的是一个列(属性)。 |
<property_name> | 用于为新属性设置名称。同一个点类型下属性名称必须是唯一的且命名时应遵循特定的规则和要求,命名规则详情请参见 命名规则 章节。 |
<property_type> | 定义属性的数据类型,支持 INT32、INT64 等多种数据类型,详情请参见 数据类型 章节。 |
[NULL|NOT NULL] | (可选)表示指定属性是否可以为空。 - NULL:表示该属性值可以为空,默认为 NULL。- NOT NULL:表示该属性值不可为空,需为该属性设置默认值。 |
[DEFAULT default_value] | (可选)用于定义属性的默认值,即当 INSERT 语句没有为列提供值情况下,该属性的值。 |
[COMMENT < string >] | (可选)用于为新属性提供对应的描述或注释。 |
- 自 ArcGraph v2.1.1 版本起支持此功能。
- 自 ArcGraph v2.1.2 版本起,该功能由 DDL 操作升级为 Online DDL 操作。
示例 1
在当前图中为“person”点类型增加“firstName”属性,命令如下:
ALTER VERTEX person ADD firstName string;
示例 2
在当前图中为“person”点类型增加“new_firstName”属性并为该属性添加对应描述,命令如下:
ALTER VERTEX person ADD new_firstName string COMMENT "new firstName";
示例 3
在当前图中为“person”点类型增加“native_place”属性并为该属性添加对应描述和默认值,命令如下:
ALTER VERTEX person ADD native_place string NOT NULL DEFAULT "beijing" COMMENT "native_place";
修改属性名称
修改点类型中属性的名称。
语法
rename_vertex_property ::= ALTER VERTEX <vertex_name> <rename_property_body>
rename_property_body ::= RENAME PROPERTY <property_name> TO <property_name>
[, RENAME PROPERTY <property_name> TO <property_name>]...;
详细说明
- 修改后的属性名称不能为当前点类型中已存在的属性名称。
- 该语句只能全部成功或者全部失败,不会存在改成功一半的情况。
- 若修改的属性存在关联的索引,则会自动同步修改索引信息中的属性名称。
示例
在当前图中将“person”点类型的“name”和“age”属性名称分别修改为“first”和“degree”,命令如下:
ALTER VERTEX person RENAME PROPERTY name TO first, RENAME PROPERTY age TO degree;
修改属性特性
自 ArcGraph v2.1.2 版本起,支持通过 Online DDL 操作修改点类型中属性的数据类型、空/非空约束及注释等特性。
- 若属性上已创建索引,则该属性不支持此操作。
- 若将属性设置为非空(
NOT NULL)属性,则必须同时指定默认值。
语法
alter_vertex_properties ::= ALTER VERTEX <vertex_name>
MODIFY [COLUMN] <property_name> <property_type> [NULL | NOT NULL] [DEFAULT default_value] [COMMENT < string >];
支持转换的数据类型
| 原数据类型 | 可转换类型 |
|---|---|
Int32 | String、Int64、BigInt |
Int64、BigInt、Boolean 、Double、Float、Timestamp、Date、Time 、DateTime 、Json、Array | String |
示例 1
在当前图中将“person”点类型的“degree”属性数据类型由“INT(32)”修改为“String”类型。命令如下:
ALTER VERTEX person
MODIFY COLUMN degree String;
示例 2
在当前图中将“person”点类型的“new_firstName”属性由允许为空值修改为必须非空,并设置默认值为“default name”。命令如下:
ALTER VERTEX person
MODIFY COLUMN new_firstName String NOT NULL DEFAULT 'default name';
示例 3
在当前图中将“person”点类型的“new_firstName”属性的注释由“new firstName”修改为“new firstName test”。命令如下:
ALTER VERTEX person
MODIFY COLUMN new_firstName String COMMENT "new firstName test";
删除属性
自 ArcGraph v2.1.2 版本起,支持通过 Online DDL 操作删除点类型中的属性。请注意,若属性上已创建索引,则该属性不支持此操作。
语法
alter_vertex_properties ::= ALTER VERTEX <vertex_name> DROP [COLUMN] <property_name>;
示例
在当前图中删除“person”点类型中的“degree”属性,命令如下:
ALTER VERTEX person
DROP COLUMN degree;
修改点类型注释
自 ArcGraph v2.1.2 版本起,支持通过 Online DDL 操作修改点类型的注释属性(即 COMMENT)。
语法
alter_vertex_comment ::= ALTER VERTEX <vertex_name> COMMENT = <string>;
示例
在当前图中将“person”点类型的注释修改为“person1”,命令如下:
ALTER VERTEX person
COMMENT = 'person1';
查看点类型详情
使用 DESC VERTEX 命令查看指定点类型的详细信息。若需了解更多与点类型相关的查看操作,请参见 SHOW VERTEXES 章节。
语法
desc_vertex ::= DESC VERTEX <vertex_name> [FULL];
详细说明
| 参数 | 说明 |
|---|---|
<vertex_name> | 点类型名称,用于指定将要操作的点类型的名称。 |
[FULL] | (可选)用于展示指定点类型的详细信息。若省略,则只展示该点类型的基本信息。 说明: 仅 ArcGraph >= v2.1.1 版本支持此参数。 |
示例 1
在当前图中查看“person”点类型的基本信息,命令如下:
DESC VERTEX person;
返回结果示例如下:
+------+--------+------+---------+---------+-------+
| name | type | null | key | default | extra |
+======+========+======+=========+=========+=======+
| _oid | uint64 | NO | OID | | |
+------+--------+------+---------+---------+-------+
| id | int64 | NO | PRIMARY | | |
+------+--------+------+---------+---------+-------+
| name | string | YES | INDEX | | |
+------+--------+------+---------+---------+-------+
| age | int32 | NO | | 16 | |
+------+--------+------+---------+---------+-------+
示例 2
在当前图中查看“person”点类型的详细信息,命令如下:
DESC VERTEX person FULL;
返回结果示例如下:
+--------------------------------------------+
| vertex |
+============================================+
| VertexSchemaMsg { |
| graph_id: 1028, |
| vertex_type_id: 1, |
| vertex_type_name: "person", |
| schema_version: 0, |
| data_version: 0, |
| status: "Normal", |
| key_type: "int64", |
| key_length: 8, |
| properties: [ |
| PropertyMsg { |
| property_id: 1, |
| property_name: "_oid", |
| property_type: "uint64", |
| type_length: 8, |
| nullable: false, |
| primary_key: false, |
| default_value: Some( |
| ValueMsg { |
| object: None, |
| }, |
| ), |
| index_num: 0, |
| order: 0, |
| comment: "", |
| is_unique: true, |
| is_full_text: false, |
| v_index_type: None, |
| is_oid: true, |
| }, |
| PropertyMsg { |
| property_id: 2, |
| property_name: "id", |
| property_type: "int64", |
| type_length: 8, |
| nullable: false, |
| primary_key: true, |
| default_value: Some( |
| ValueMsg { |
| object: None, |
| }, |
| ), |
| index_num: 1, |
| order: 0, |
| comment: "", |
| is_unique: true, |
| is_full_text: false, |
| v_index_type: None, |
| is_oid: false, |
| }, |
| PropertyMsg { |
| property_id: 3, |
| property_name: "name", |
| property_type: "string", |
| type_length: 0, |
| nullable: true, |
| primary_key: false, |
| default_value: Some( |
| ValueMsg { |
| object: None, |
| }, |
| ), |
| index_num: 1, |
| order: 0, |
| comment: "姓名", |
| is_unique: false, |
| is_full_text: false, |
| v_index_type: None, |
| is_oid: false, |
| }, |
| PropertyMsg { |
| property_id: 4, |
| property_name: "age", |
| property_type: "int32", |
| type_length: 4, |
| nullable: false, |
| primary_key: false, |
| default_value: Some( |
| ValueMsg { |
| object: Some( |
| ValueI32( |
| 16, |
| ), |
| ), |
| }, |
| ), |
| index_num: 0, |
| order: 0, |
| comment: "年龄", |
| is_unique: false, |
| is_full_text: false, |
| v_index_type: None, |
| is_oid: false, |
| }, |
| ], |
| partition_schema: Some( |
| PartitionSchemaMsg { |
| method: "hash", |
| column: "_TYPE", |
| }, |
| ), |
| temporal: false, |
| comment: "测试Vertex", |
| indexes: [ |
| IndexSchemaMsg { |
| index_id: 2, |
| index_name: "name_index", |
| index_type: "Vertex", |
| graph_id: 1028, |
| properties: [ |
| IndexPropertyMsg { |
| property_id: 3, |
| property_name: "name", |
| property_path: None, |
| unique: true, |
| }, |
| ], |
| status: "Ready", |
| type_id: 1, |
| unique: true, |
| version: 0, |
| is_fulltext: false, |
| v_index_type: None, |
| is_primary_key: false, |
| }, |
| IndexSchemaMsg { |
| index_id: 1, |
| index_name: "person_pk_index", |
| index_type: "Vertex", |
| graph_id: 1028, |
| properties: [ |
| IndexPropertyMsg { |
| property_id: 2, |
| property_name: "id", |
| property_path: None, |
| unique: true, |
| }, |
| ], |
| status: "Ready", |
| type_id: 1, |
| unique: true, |
| version: 0, |
| is_fulltext: false, |
| v_index_type: None, |
| is_primary_key: true, |
| }, |
| ], |
| } |
+--------------------------------------------+
删除点类型
删除点类型时,会将该点类型中的点数据删除,同时如果带 CASCADE 选项,则会删除边类型中涉及的该点类型的 Vertex Pairs,如果不带 CASCADE 选项,如果该点类型存在于其它边类型中,则不允许删除;请谨慎操作。
语法
drop_vertex ::= DROP VERTEX [IF EXISTS] <vertex_name> [CASCADE] [FORCE];
详细说明
| 参数 | 说明 |
|---|---|
[IF EXISTS] | (可选)在删除点类型时,用于检测指定的点类型是否存在于当前图中,若存在则删除点类型,若不存在则显示成功但不进行任何操作。仅通过点类型名称进行检测,若省略,则不检测。 |
<vertex_name> | 点类型名称,用于指定将要操作的点类型的名称。 |
[CASCADE] | (可选)使用 CASCADE 命令可删除存在关联关系的点类型。 |
[FORCE] | (可选)使用 FORCE 命令可强制删除点类型。若省略则可能会因为点类型的当前状态导致删除失败。 |
- 自 ArcGraph v2.1.2 版本起,该功能由 DDL 操作升级为 Online DDL 操作。
- 自 ArcGraph v2.1.2 版本起,执行
DROP VERTEX命令成功后,数据将立即从 ArcGraph 图数据库中逻辑删除且不可见,但存储于磁盘上的物理数据需等 Schema GC 任务执行后才�会被彻底删除。 - 自 ArcGraph v2.1.2 版本起,通过执行
SHOW FULL VERTEXES;命令可以查看已删除但未回收的点类型。这些点类型的 ID 不变,但名字会被定义为_{name}_{timestamp}格式,如_person_1724922449757360。
删除独立的点类型
若点类型无与之关联的边类型,可使用 DROP VERTEX 命令删除独立的点类型。
示例
在当前图中删除名为“person”的点类型,命令如下:
DROP VERTEX IF EXISTS person;
删除存在关联关系的点类型
若点类型有与之关联的边类型,可使用 CASCADE 命令删除点类型。
示例
在当前图中删除名为“person”的点类型,命令如下:
DROP VERTEX IF EXISTS person CASCADE;
强制删除点类型
若点类型因当前状态无法正常删除时,可使用 FORCE 命令强制删除点类型。
示例
在当前图中强制删除名为“person”的点类型,命令如下:
DROP VERTEX IF EXISTS person FORCE;
边类型
在 ArcGraph 图数据库中,边类型是用来定义一组拥有相同特征的边的模型,需要在图中进行边类型的相关操作。
前提条件
在开始操作前,请确保当前登录用户拥有执行此操作所需权限的角色。有关权限的详细说明,详情请参见 权限 章节。
创建边类型
使用 CREATE EDGE 为数据库创建边类型,创建边类型时可同时创建相关索引。
语法
create_edge ::= CREATE [TEMPORAL] EDGE [IF NOT EXISTS] <edge_name>
( <edge_body> [, <edge_body>]... )
[ COMMENT = < string > ];
edge_body ::= <edge_end_point>
| <normal_property>
| <embedded_index>;
edge_end_point ::= FROM vertex_name TO vertex_name;
详细说明
部分参数说明如下,其他参数说明请参考 创建点类型 章节。
| 参数 | 说明 |
|---|---|
[TEMPORAL] | (可选)表示该边类型是时态边类型。时态边类型通常用于表示随时间变化的关系,详情请参见 时态图 章节。 |
<edge_name> | 设置边类型名称。在同一个图中,边类型名称必须是唯一的且命名时应遵循特定的规则和要求,命名规则详情请参见 命名规则 章节。 |
<edge_body> | 用于定义边类型的关联点类型(<edge_end_point>,即起点类型和终点类型)、属性(<normal_property> )和索引(<embedded_index>)信息,支持同时设置多个关联点类型、属性或索引,可用英文逗号(“,”)分隔。 |
<edge_end_point> | 用于定义该边类型的关联点类型,两者可以为同一个点类型。 |
说明:
ArcGraph 2.1 版本创建边类型时不支持 primary key,若设置,则客户端会显示 InvalidStatement 错误。
示例 1
在当前图中创建一个命名为“like”的边类型,命令如下:
CREATE EDGE like (
name string NOT NULL COMMENT '喜欢',
since INT(64) default '2020' COMMENT '开始时间',
FROM person TO person,
INDEX index_a(name)
)
COMMENT = '测试Edge';
示例 2
在当前图中创建包含 ARRAY 属性的“FRIEND_OF”边类型,命令如下:
CREATE EDGE FRIEND_OF (
commonHobbies ARRAY(STRING) COMMENT '共同爱好列表',
FROM PersonArray TO PersonArray
)
COMMENT = '测试Edge';
修改边类型
使用 ALTER EDGE 命令修改当前图中的边类型,ArcGraph 图数据库版本不同支持的修改功能略有不同,请以实际情况为准。
修改边类型名称
修改边类型的名称,修改后的新名称不能是当前图中已存在的边类型名称,命名规则详情请参见 命名规则 章节。
语法
rename_edge ::= ALTER EDGE <edge_name> RENAME TO <edge_name>;
示例
在当前图中将边类型名称“like”修改为“knows”,命令如下:
ALTER EDGE like RENAME TO knows;
管理边类型属性
在当前图中使用 ALTER EDGE 命令管理边类型中的属性。
增加属性
为边类型增加属性,可以丰富边类型的数据模型,使其更好地满足业务需求。
语法
alter_edge_properties ::= ALTER EDGE <edge_name> <add_property_body>
add_property_body ::= ADD [COLUMN] <property_name> <property_type> [NULL | NOT NULL] [DEFAULT default_value] [COMMENT < string >]
[, ADD [COLUMN] <property_name> <property_type> [NULL | NOT NULL] [DEFAULT default_value] [COMMENT < string >]]...;
详细说明
| 参数 | 说明 |
|---|---|
<edge_name> | 用于指定将要增加属性的边类型的名称。需要指定正确的边类型名称,以确保属性被添加到正确的对象上。 |
[COLUMN] | (可选)用于指明将要添加的是一个列(�属性)。 |
<property_name> | 用于为新属性设置名称。同一个边类型下属性名称必须是唯一的且命名时应遵循特定的规则和要求,命名规则详情请参见 命名规则 章节。 |
<property_type> | 定义属性的数据类型,支持 INT32、INT64 等多种数据类型,详情请参见 数据类型 章节。 |
[NULL | NOT NULL] | (可选)表示指定属性是否可以为空。 - NULL:表示该属性值可以为空,默认为 NULL。- NOT NULL:表示该属性值不可为空,需为该属性设置默认值。 |
[DEFAULT default_value] | (可选)用于定义属性的默认值,即当 INSERT 语句没有为列提供值情况下,该属性的值。 |
[COMMENT < string >] | (可选)用于为新属性提供对应的描述或注释。 |
- 自 ArcGraph v2.1.1 版本起支持此功能。
- 自 ArcGraph v2.1.2 版本起,该功能由 DDL 操作升级为 Online DDL 操作。
示例 1
在当前图中为“knows”边类型增加“createDate”属性,命令如下:
ALTER EDGE knows ADD createDate String;
示例 2
在当前图中为“knows”边类型增加“new_createDate”属性并为该属性添加对应描述,命令如下:
ALTER EDGE knows ADD new_createDate String COMMENT "new createDate";
示例 3
在当前图中为“knows”边类型增加“native_place”属性并为该属性添加对应描述和默认值,命令如下:
ALTER EDGE knows ADD native_place String NOT NULL DEFAULT "beijing" COMMENT "native_place";
修改属性名称
修改边类型中属性的名称。
语法
rename_edge_property ::= ALTER EDGE <edge_name> <rename_property_body>
rename_property_body ::= RENAME PROPERTY <property_name> TO <property_name>
[, RENAME PROPERTY <property_name> TO <property_name>]...;
详细说明
- 修改后的属性名称不能为当前边类型中已存在的属性名称。
- 该语句只能全部成功或者全部失败,不会存在改成功一半的情况。
- 若修改的属性存在关联的索引,则会自动同步修改索引信息中的属性名称。
示例
在当前图中将“knows”边类型的“location”和“time”属性名称分别修改为“site”和“date”,命令如下:
ALTER EDGE knows RENAME PROPERTY location TO site, RENAME PROPERTY time TO date;
修改属性特性
自 ArcGraph v2.1.2 版本起,支持通过 Online DDL 操作修改边类型中属性的数据类型、空/非空约束及注释等特性。支持转换的数据类型请参见 修改点类型属性特性 章节。
- 若属性上已创建索引,则该属性不支持此操作。
- 若将属性设置为非空(
NOT NULL)属性,则必须同��时指定默认值。
语法
alter_edge_properties ::= ALTER EDGE <edge_name>
MODIFY [COLUMN] <property_name> <property_type> [NULL | NOT NULL] [DEFAULT default_value] [COMMENT < string >];
示例 1
在当前图中将“knows”边类型的“since”属性数据类型由“INT(64)”修改为“String”类型。命令如下:
ALTER EDGE knows
MODIFY since String;
示例 2
在当前图中将“knows”边类型的“new_createDate”属性由允许为空值更改为必须非空,并设置默认值为“default new_createDate”。命令如下:
ALTER EDGE knows
MODIFY COLUMN new_createDate String NOT NULL DEFAULT 'default new_createDate';
示例 3
在当前图中将“knows”边类型的“new_createDate”属性的注释由“new createDate”修改为“new createDate test”。命令如下:
ALTER EDGE knows
MODIFY COLUMN new_createDate string COMMENT "new createDate test";
删除属性
自 ArcGraph v2.1.2 版本起,支持通过 Online DDL 操作删除边类型中属性。请注意,若属性上已创建索引,则该属性不支持此操作。
语法
alter_edge_properties ::=ALTER EDGE <edge_name> DROP [COLUMN] <property_name>;
示例
在当前图中删除“knows”边类型的“since”属性,命令如下:
ALTER EDGE knows
DROP since;
修改注释
自 ArcGraph v2.1.2 版本起,支持通过 Online DDL 操作修改边类型中属性的注释(即 COMMENT)。
语法
alter_edge_comment ::= ALTER EDGE <edge_name> COMMENT = <string>;
示例
在当前图中修改“knows”边类型注释,命令如下:
ALTER EDGE knows
COMMENT = '测试Edge1';
增加/删除关联点类型
自 ArcGraph v2.1.2 版本起,支持通过 Online DDL 操作增加/删除边类型关联的点类型。
语法
alter_edge_endpoint ::= {ADD | DROP} FROM <vertex_name> TO <vertex_name>;
示例 1
在当前图中增加“like”边类型的关联点类型“person”和“person”,命令如下:
ALTER EDGE like
ADD FROM person TO person;
示例 2
在当前图中删除“like”边类型的关联点类型“person”和“person”,命令如下:
ALTER EDGE like
DROP FROM person TO person;
查看边类型详情
使用 DESC EDGE 命令查看指定边类型的详细信息。若需了解更多与边类型相关的查看操作,请参见 SHOW EDGES 章节。
语法
desc_edge ::= DESC EDGE <edge_name> [FULL];
详细说明
| 参数 | 说明 |
|---|---|
<edge_name> | 边类型名称,用于指定将要操作的边类型的名称。 |
[FULL] | (可选)用于展示指定边类型的详细信息。若省略,则只展示该边类型的基本信息。 说明: 仅 ArcGraph >= v2.1.1 版本支持此参数。 |
示例 1
在当前图中查看“like”边类型的基本信息,命令如下:
DESC EDGE like;
返回结果示例如下:
+-------+--------+------+-------+---------+-------+
| name | type | null | key | default | extra |
+=======+========+======+=======+=========+=======+
| name | string | NO | INDEX | | |
+-------+--------+------+-------+---------+-------+
| since | int64 | YES | | 2020 | |
+-------+--------+------+-------+---------+-------+
示例 2
在当前图中查看“like”边类型的详细信息,命令如下:
DESC EDGE like FULL;
返回结果示例如下:
+--------------------------------------------+
| edge |
+============================================+
| EdgeSchemaMsg { |
| graph_id: 1028, |
| edge_type_id: 1, |
| edge_type_name: "like", |
| schema_version: 0, |
| data_version: 0, |
| status: "Normal", |
| properties: [ |
| PropertyMsg { |
| property_id: 5, |
| property_name: "name", |
| property_type: "string", |
| type_length: 0, |
| nullable: false, |
| primary_key: false, |
| default_value: Some( |
| ValueMsg { |
| object: None, |
| }, |
| ), |
| index_num: 1, |
| order: 0, |
| comment: "喜欢", |
| is_unique: false, |
| is_full_text: false, |
| v_index_type: None, |
| is_oid: false, |
| }, |
| PropertyMsg { |
| property_id: 6, |
| property_name: "since", |
| property_type: "int64", |
| type_length: 8, |
| nullable: true, |
| primary_key: false, |
| default_value: Some( |
| ValueMsg { |
| object: Some( |
| ValueI64( |
| 2020, |
| ), |
| ), |
| }, |
| ), |
| index_num: 0, |
| order: 0, |
| comment: "开始时间", |
| is_unique: false, |
| is_full_text: false, |
| v_index_type: None, |
| is_oid: false, |
| }, |
| ], |
| vertex_type_pair: [ |
| VertexTypePairMsg { |
| from_id: 1, |
| to_id: 1, |
| status: "Normal", |
| from_name: Some( |
| "person", |
| ), |
| to_name: Some( |
| "person", |
| ), |
| }, |
| ], |
| partition_schema: Some( |
| PartitionSchemaMsg { |
| method: "hash", |
| column: "_TYPE", |
| }, |
| ), |
| temporal: false, |
| comment: "测试Edge", |
| indexes: [ |
| IndexSchemaMsg { |
| index_id: 3, |
| index_name: "index_a", |
| index_type: "Edge", |
| graph_id: 1028, |
| properties: [ |
| IndexPropertyMsg { |
| property_id: 5, |
| property_name: "name", |
| property_path: None, |
| unique: false, |
| }, |
| ], |
| status: "Ready", |
| type_id: 1, |
| unique: false, |
| version: 0, |
| is_fulltext: false, |
| v_index_type: None, |
| is_primary_key: false, |
| }, |
| ], |
| } |
+--------------------------------------------+
删除边类型
使用 DROP EDGE 命令删除边类型。删除边类型时,会将边类型中的边数据同步删除,请谨慎操作。
语法
drop_edge ::= DROP EDGE [IF EXISTS] <edge_name> [FORCE];
详细说明
| 参数 | 说明 |
|---|---|
[IF EXISTS] | (可选)在删除边类型时,用于检测指定的边类型是否存在于当前图中,若存在则删除边类型,若不存在则显示成功但不进行任何操作。仅通过边类型名称进行检测,若省略,则不检测。 |
<edge_name> | 边类型名称,用于指定将要操作的边类型的名称。 |
[FORCE] | (可选)使用 FORCE 命令可强制删除边类型。若省略则可能会因为边类型的当前状态导致删除失败。 |
- 自 ArcGraph v2.1.2 版本起,该功能由 DDL 操作升级为 Online DDL 操作。
- 自 ArcGraph v2.1.2 版本起,执行
DROP EDGE命令成功后,数据将立即从 ArcGraph 图数据库中逻辑删除且不可见,但存储于磁盘上的物理数据需等 Schema GC 任务执行后才会被彻底删除。 - 自 ArcGraph v2.1.2 版本起,通过执行
SHOW FULL EDGES;命令可以查看已删除但未回收的边类型。这些边类型的 ID 不变,但名字会被定义为_{name}_{timestamp}格式,如_like_1724929319723310。
普通删除
示例
在当前图中删除“like”的边类型,命令如下:
DROP EDGE IF EXISTS like;
强制删除边类型
若边类型因当前状态无法正常删除时,可使用 FORCE 命令强制删除。
示例
强制删除“like”的边类型,命令如下:
DROP EDGE IF EXISTS like FORCE;
索引
索引是数据库中用于提高数据检索性能的一种数据结构。它类似于书籍的目录,可以加快数据库查询操作的速度。
索引的作用是通过创建一个快速访问路径,减少数据库查询时需要扫描的数据量。它可以根据指定的列或字段值创建,并将其存储在特定的数据结构中,以便快速定位和访问数据。
索引的主要类型如下。
| 类型 | 说明 |
|---|---|
| 普通索引 | 最基本的索引,它没有任何限制。 |
| 主键索引 | 是一种特殊的唯一索引,一个表只能有一个主键,不允许有空值。 |
| 组合索引 | 指多个字段上创建的索引,只有在查询条件中使用了创建索引时的第一个字段,索引才会被使用。 |
| 空间数据索引 | 为提升 ST_GEOMETRY (地理空间类型)数据查询效率,ArcGraph 自 v2.1.3 版起,提供纯内存的空间数据索引(SPATIAL INDEX)。目前,此索引仅支持在单列非空的 ST_GEOMETRY 数据类型属性上创建,且须处于 Ready 状态才可使用。说明: ArcGraph 服务器重启后,索引默认状态为 New,需重新构建索引( REBUILD INDEX)。 |
创建索引
ArcGraph 图数据库支持同步创建(创建点/边类型时同步创建索引)和直接创建两种索引创建方式。关于同步创建索引的操作,请参见创建点类型/创建边类型章节;本章节将主要介绍直接创建索引的步骤,语法详细说明请参见创建点类型章节。
语法
create_index ::= CREATE {VERTEX|EDGE} [SPATIAL] INDEX [IF NOT EXISTS] <index_name>
ON <schema_name> (<index_property> [, <index_property>]...)
[COMMENT <string>];
index_property ::= <property_name> [->> json_path];
- 自 ArcGraph v2.1.2 版本起,支持通过 Online DDL 操作执行
Create index创建索引。 - 自 ArcGraph v2.1.2 版本起,执行
Create index命令后, ArcGraph 图数据库服务器的后台会生成一个异步创建索引的任务(通常称为Job),待任务完成后该索引自动转为Ready状态,表明它已准备好被查询使用。通过SHOW JOBS命令查看任务的执行情况,详情请参见 SHOW JOBS 章节。 - 自 ArcGraph v2.1.2 版本起,执行
SHOW FULL {VERTEX|EDGE} INDEXES;命令可以查看索引的详细信息,包括对应的创建任务job_id,若job_id为空,则表示该索引已创建完成,请参见 SHOW INDEXES 章节。 - 自 ArcGraph v2.1.3 版本起,支持执行
SPATIAL INDEX创建空间数据索引。
示例 1
在当前图中为“person”点类型的“name”属性创建索引,命令如下:
CREATE VERTEX INDEX idx_person ON person(name) COMMENT 'person first name index';
返回结果示例如下:
+-----------------------------------------------------------------------------------------+
| Asynchronously creating vertex type index idx_person and job id is 10101966083883663148 |
+=========================================================================================+
+-----------------------------------------------------------------------------------------+
示例 2
在当前图中为“like”边类型的“since”属性创建索引。命令如下:
CREATE EDGE INDEX idx_like ON like(since) COMMENT 'like first since index';
返回结果示例如下:
+-------------------------------------------------------------------------------------+
| Asynchronously creating edge type index idx_like and job id is 14363432717764659822 |
+=====================================================================================+
+-------------------------------------------------------------------------------------+
示例 3
当 ArcGraph >= v2.1.3 版本时,在当前图中为“location”点类型的“position”属性创建空间数据索引。命令如下:
CREATE VERTEX SPATIAL INDEX spatial_index_vertex ON location(position);
返回结果示例如下:
+--------------------------------------------------------------------------------+
| Asynchronously creating vertex type index spatial_index_vertex and job id is 0 |
+================================================================================+
+--------------------------------------------------------------------------------+
示例 4
当 ArcGraph >= v2.1.3 版本时,在当前图中为“Route”边类型的“path”属性创建空间数据索引。命令如下:
CREATE EDGE SPATIAL INDEX spatial_index_edge ON Route(path);
返回结果示例如下:
+----------------------------------------------------------------------------+
| Asynchronously creating edge type index spatial_index_edge and job id is 0 |
+============================================================================+
+----------------------------------------------------------------------------+
重建索引
自 ArcGraph v2.1.3 版本起,支持重建索引操作,目前仅支持重建空间数据索引(SPATIAL INDEX)。
仅允许对处于 New 和 Ready 状态的索引执行重建索引操作。重建后索引状态将变为 Ready。
语法
rebuild_index ::= REBUILD {VERTEX|EDGE} SPATIAL INDEX <schema_name>;
示例
REBUILD VERTEX SPATIAL INDEX spatial_index_vertex;
返回结果示例如下:
+-------------------------------------------------------------------------------------------------------+
| Asynchronously rebuild Vertex type index ["spatial_index_vertex"] and job id is [6442634530639022404] |
+=======================================================================================================+
+-------------------------------------------------------------------------------------------------------+
查看索引详情
在当前图中使用 DESC INDEX 命令查看指定索引的详细信息。若需了解更多与索引相关的查看操作,请参见 SHOW INDEXES 章节。
语法
desc_index ::= DESC {VERTEX|EDGE} INDEX <schema_name> [FULL];
详细说明
| 参数 | 说明 |
|---|---|
<schema_name> | 索引名称,用于指定将要操作的索引的名称。 |
[FULL] | (可选)用于展示指定索引的详细信息。若省略,则只展示该索引的基本信息。 说明: 仅 ArcGraph >= v2.1.1 版本支持此参数。 |
示例 1
在当前图中查看点类型中“name_index”索引的基本信息,命令如下:
DESC VERTEX INDEX name_index;
返回结果示例如下:
+------+------+--------+--------+------+---------+
| name | path | type | unique | null | default |
+======+======+========+========+======+=========+
| name | | string | YES | YES | |
+------+------+--------+--------+------+---------+
示例 2
在当前图中查看点类型中“name_index”索引的详细信息,命令如下:
DESC VERTEX INDEX name_index FULL;
返回结果示例如下:
+------------------------------------+
| index |
+====================================+
| IndexSchemaMsg { |
| index_id: 3, |
| index_name: "name_index", |
| index_type: "Vertex", |
| graph_id: 1026, |
| properties: [ |
| IndexPropertyMsg { |
| property_id: 3, |
| property_name: "name", |
| property_path: None, |
| unique: true, |
| }, |
| ], |
| status: "Ready", |
| type_id: 1, |
| unique: true, |
| version: 0, |
| is_fulltext: false, |
| v_index_type: None, |
| is_primary_key: false, |
| } |
+------------------------------------+
示例 3
在当前图中查看边类型中“index_a”索引的基本信息,命令如下:
DESC EDGE INDEX index_a;
返回结果示例如下:
+------+------+--------+--------+------+---------+
| name | path | type | unique | null | default |
+======+======+========+========+======+=========+
| name | | string | NO | NO | |
+------+------+--------+--------+------+---------+
删除索引
在当前图中删除索引,可使用 FORCE 命令强制删除索引。
语法
drop_index ::= DROP {VERTEX|EDGE} INDEX [IF EXISTS] <index_name> [FORCE];
- 自 ArcGraph v2.1.2 版本起,该功能由 DDL 操作升级为 Online DDL 操作。
- 自 ArcGraph v2.1.2 版本起,执行删除索引命令成功后,数据将立即从 ArcGraph 图数据库中逻辑删除且不可见,但存储于磁盘上的物理数据需等 Schema GC 任务执行后才会被彻底删除。
- 自 ArcGraph v2.1.2 版本起,通过执行
SHOW FULL {VERTEX|EDGE} INDEXES;命令可以查看已删除但未回收的索引。这些索引的 ID 不变,但名字会被定义为_{name}_{timestamp}格式,如_idx_person_1724931030554177。
示例 1
DROP VERTEX INDEX idx_person;
示例 2
DROP EDGE INDEX idx_like;
示例 3
DROP VERTEX INDEX idx_person FORCE;
DML(增 | 删 | 改)
DML 是一种用于操作数据库中数据的语言。在 ArcGraph 图数据库中使用 DML 对点数据、边数据进行新增、修改、删除等操作。
前提条件
- 已创建并使用图
- 已创建点类型
- 已创建与点类型相关联的边类型
新增数据
语法
insert ::= INSERT <insert_value> [, <insert_value>]... ;
insert_value ::= <vertex_value>|<edge_value>;
vertex_value ::= (:<vertex_type> <properties>);
properties ::= '{' <property_name> : <expression> [ ',' <property_name> : <expression> ]... '}' ;
edge_value ::= <vertex_value>-'[':<edge_type> [<properties> |<_ts> ]']'-><vertex_value>;
详细说明
| 参数 | 说明 |
|---|---|
<insert_value> | 表示将要插入的点或边的值。 |
<vertex_value> | 表示将要插入的点的值。 |
<edge_value> | 表示将要插入的边的值。 |
<vertex_type> | 表示将要操作的点类型。 |
<properties> | 表示将要插入的点的属性及其对应的值。 |
<property_name> | 表示属性名称。同一个点类型下属性名称必须是唯一的且命名时应遵循特定的规则和要求,命名规则详情请参见 命名规则 章节。 |
<expression> | 表示属性的数据值,详情请参见 表达式 章节。 |
<edge_type> | 表示将要操作的边类型。 |
<_ts> | 一种特殊属性,用于表示时间戳。当边中包含此属性时,我们称之为时态边,因为它与时间紧密相关。 |
新增点数据
使用 INSERT 命令,为点类型中新增点数据。若同时新增多个点数据,可用“,”隔开点数据进行新增。
示例 1
在当前图中,为“person”点类型中插入“John”点数据,命令如下:
INSERT (:person {id:1, name:'John', age:30});
示例 2
在当前图中,同时为“person”点类型中插入“Mary”和“Jerry”点数据,命令如下:
INSERT (:person {id:2, name:'Mary', age:25}), (:person {id:3, name:'Jerry', age:22});
示例 3
在当前图中,为“PersonArray”点类型中插入包含 ARRAY 属性的点数据,命令如下:
INSERT (:PersonArray {id:1, name:'Tom', hobbies:['Reading', 'Swimming', 'Cycling']});
详细说明
INSERT插入子句不可在MATCH查询子句之后。INSERT插入子句插入点数据时,必须包含具体点类型以及点数据的主键信息。
新增边数据
使用 INSERT 命令,可以新增边数据,包括时态边数据。新增时态边数据详情请参见 新增时态边数据 章节。
示例 1
在当前图中,为“like”边类型中插入边数据,命令如下:
INSERT (a:person {id:1})-[:like {name:'喜欢'}]->(b:person {id:2});
示例 2
在当前图中,为“like”边类型中插入多个边数据,用“,”隔开,命令如下:
INSERT (:person {id:1})-[:like {name:'喜欢'}]->(:movie {id:1}),(:person {id:2})-[:like {name:'喜�欢'}]->(:movie {id:1});
示例 3
在当前图中,为“FRIEND_OF”边类型中插入包含 ARRAY 属性的边数据。命令如下:
INSERT (:PersonArray {id:1})-[:FRIEND_OF {commonHobbies:['Reading','Cycling']}]->(:PersonArray {id:2});
详细说明
INSERT插入子句不可在MATCH查询子句之后。- 每一个
INSERT插入子句,至多允许一个边类型。 INSERT子句插入边数据时,连接的点必须包含具体点类型以及点数据的主键信息。_ts作为一个特殊属性放在边类型中,它作为保留字不允许被用作普通属性名称。
修改数据
语法
update_set ::= MATCH <pattern_part>
[WHERE <expression>]
SET <set_item> [, <set_item>];
set_item = <schema_name> . <property_name> = <expression>;
详细说明
| 参数 | 说明 |
|---|---|
<pattern_part> | 定义一种描述点或边的模式,可以是一个或多个。 |
[WHERE <expression>] | (可选)定义一种过滤条件,用于过滤匹配的点或边。 |
<set_item> | 定义将要修改的变量名称和属性名称。 |
<schema_name> | 表示 SET 语句前查询出的点或边的变量名称。 |
<property_name> | 表示将要修改的属性名称。 |
<expression> | 表示属性的数据值,详情请参见 表达式 章节。 |
修改点数据
使用 SET 命令修改点属性。
示例 1
在当前图中,修改“John”点的名称为“Michael”,命令如下:
MATCH (n:person)
WHERE n.name = 'John'
SET n.name = 'Michael';
示例 2
在当前图中,同时修改“person”点类型下“Michael”点数据的多个属性,命令如下:
MATCH (n:person {id:1, name:'Michael', age:30})
SET n.name = 'John1', n.age = 28;
示例 3
在当前图中,将“person”点类型下所有点数据的多个属性值同时修改为相同的属性值,命令如下:
MATCH (n:person)
SET n.name = 'John1', n.age = '30';
详细说明
SET语句前必须有query语句。SET语句中只对propertyName=value中定义的属性值进行修改,其他属性保持不变。- 不能直接通过传入一个 map 形式的数据来修改点的属性值。在对点进行操作时,需要逐个修改每个属性的值,而不能一次性修改整个点的属性。
- 不支持修改主键
id。
修改边数据
使用 SET 命令修改边属性。
示例
在当前图中,修改边属性,命令如下:
MATCH (n:person {name:'John'})-[r:like]->(m)
SET r.name = 'xihuan1';
详细说明
SET语句前必须有query语句。SET语句中只对propertyName=value中定义的属性值进行修改,其他属性保持不变。- 不能直接通过传入一个 map 形式的数据来修改边对象的属性值。在对边对象进行操作时,需要逐个修改每个属性的值,而不能一次性修改整个边对象的属性。
- 不支持修改主键
id和_ts值。
删除数据
语法
delete ::= MATCH <pattern_part>
[WHERE <expression>] [{DETACH|NODETACH}]
DELETE {<vertex_name>|<edge_name>};
详细说明
| 参数 | 说明 |
|---|---|
<pattern_part> | 定义一种描述点或边的模式,可以是一个或多个。 |
[WHERE <expression>] | (可选)定义一种过滤条件,用于过滤匹配的点或边。 |
[{DETACH|NODETACH}] | (可选)表示同时删除点和与之相关联的边。 |
<vertex_name> | 表示将要删除的点变量名称。 |
<edge_name> | 表示将要删除的边变量名称。 |
删除独立的点
使用 DELETE 删除独立的点,若该点有与之相关联的边,则提示操作错误,此时,需要同时删除点和与之相关联的边。
示例
在当前图中,删除“John”点,命令如下:
MATCH (n:person {name:'John'})
DELETE n;
同时删除点及其关联边
DELETE 子句的默认模式是 NODETACH 模式。在这种模式下,删除点时,若该点有与之相关联的边,则删除操作失败。所以需要搭配 DETACH 子句使用,才可以同时删除点和与之相关联的边。
示例
在当前图中,删除“John”点和与之相关联的边,命令如下:
MATCH (p:person {id:1, name:'John'})
DETACH DELETE p;
同时删除点类型及其关联边
使用 DETACH DELETE 删除指定点类型及其包含的所有点和与点相关联的边。
示例
在当前图中,删除“person”点类型中的所有点和与点相关联的边,命令如下:
MATCH (p:person)
DETACH DELETE p;
基本查询
DQL 是一种用于查询数据库中数据的语言。在 ArcGraph 图数据库中,用户通过使用 DQL 语言可以从数据库中检索所需的数据,并根据特定的条件和要求进行过滤、排序和聚合。这使得用户可以轻松地获取所需的数据,并进行进一步的分析和处理。
语法
<query> ::= <match> <return> ;
match ::=
MATCH <pattern_part>
[WHERE <expression>]
return ::=
RETURN [DISTINCT] <projection_list>
[<order>]
[SKIP <integer>] [LIMIT <integer>]
pattern_part ::= { <variable> = <pattern_element> | <pattern_element> }
pattern_element ::= <node_pattern> [ <pattern_element_chain> ]...
pattern_element_chain ::= <relationship_pattern> <node_pattern>
relationship_pattern ::=
{
<- <relationship_detail> ->
| <- <relationship_detail> -
| - <relationship_detail> ->
| - <relationship_detail> -
}
relationship_detail ::= '[' [<variable>] [<relationship_types>][<range_literal>] [<properties>] ']'
relationship_types ::= : <rel_type_name> [ '|' <rel_type_name> ]...
range_literal ::= * [<integer>] ['..' [<integer>]]
node_pattern ::= ([<variable>] [<node_labels>] [<properties>])
node_labels ::= : <label_name> [ '|' <label_name> ]...
properties ::= '{' <property_name> : <expression> [ ',' <property_name> : <expression> ]... '}'
projection_list ::= *
| <projection_item> [',' <projection_item>]...
projection_item ::=
{ <expression> AS <variable> | <expression> }
order ::= ORDER BY <sort_item> [ ',' <sort_item> ]...
sort_item ::= <expression> [ {ASCENDING | ASC | DESCENDING | DESC} ]
查询点
查询所有的点
查询当前图中所有的点。
示例
在当前图中查询所有的点。命令如下:
MATCH (n) RETURN n;
返回结果示例如下:
+-----------------------------------------------------------------------------------------+
| n |
+=========================================================================================+
| vid: [_oid: 36998642535497729, label: person], properties: [36998642535497729, 2, Mary] |
+-----------------------------------------------------------------------------------------+
| vid: [_oid: 36998642535497728, label: person], properties: [36998642535497728, 1, John] |
+-----------------------------------------------------------------------------------------+
| vid: [_oid: 73027439569141762, label: book], properties: [73027439569141762, 1, book1] |
+-----------------------------------------------------------------------------------------+
查询指定点类型的点
-
查询单个点类型的点
查询当前图中某一个点类型的所有点。
示例 1
在当前图中查询“person”点类型中的所有点。命令如下:MATCH (m:person) RETURN m;返回结果示例如下:
+-----------------------------------------------------------------------------------------+
| m |
+=========================================================================================+
| vid: [_oid: 36998642535497729, label: person], properties: [36998642535497729, 2, Mary] |
+-----------------------------------------------------------------------------------------+
| vid: [_oid: 36998642535497728, label: person], properties: [36998642535497728, 1, John] |
+-----------------------------------------------------------------------------------------+示例 2
在当前图中查询“person”点类型中的id为“1”的点,命令如下:MATCH (m:person{id:1}) RETURN m;返回结果示例如下:
+-----------------------------------------------------------------------------------------+
| m |
+=========================================================================================+
| vid: [_oid: 36998642535497728, label: person], properties: [36998642535497728, 1, John] |
+-----------------------------------------------------------------------------------------+ -
查询多个点类型的点
查询当前图中多个点类型的所有点,可以用“|”(“或”符号)将不同点类型连接在一起,各点类型间为“或”的关系。
示例 1
在当前图中查询“person”和“book”点类型中的所有点。命令如下:MATCH (m:person|book)
RETURN m;返回结果示例如下:
+-----------------------------------------------------------------------------------------+
| m |
+=========================================================================================+
| vid: [_oid: 73027439569141762, label: book], properties: [73027439569141762, 1, book1] |
+-----------------------------------------------------------------------------------------+
| vid: [_oid: 36998642535497728, label: person], properties: [36998642535497728, 1, John] |
+-----------------------------------------------------------------------------------------+
| vid: [_oid: 36998642535497729, label: person], properties: [36998642535497729, 2, Mary] |
+-----------------------------------------------------------------------------------------+
查询与指定点相关联的点
查询当前图中,1 跳范围内与指定点相关联的所有点。ArcGraph 图数据库中,在不考虑边的类型和方向的情况下,通常使用 -- 符号表示与之相关。
示例 1
在当前图中查询 1 跳范围内与“John”相关的所有点。命令如下:
MATCH (a: person {name: 'John'})--(m)
RETURN m;
返回结果示例如下:
+-----------------------------------------------------------------------------------------+
| m |
+=========================================================================================+
| vid: [_oid: 36998642535497729, label: person], properties: [36998642535497729, 2, Mary] |
+-----------------------------------------------------------------------------------------+
| vid: [_oid: 36998642535497729, label: person], properties: [36998642535497729, 2, Mary] |
+-----------------------------------------------------------------------------------------+
示例 2
在当前图中查询 1 跳范围内与“John”相关的“person”点类型中的所有点。命令如下:
MATCH (n:person { name: 'John' })--(m:person)
RETURN m;
返回结果示例如下:
+-----------------------------------------------------------------------------------------+
| m |
+=========================================================================================+
| vid: [_oid: 36998642535497729, label: person], properties: [36998642535497729, 2, Mary] |
+-----------------------------------------------------------------------------------------+
| vid: [_oid: 36998642535497729, label: person], properties: [36998642535497729, 2, Mary] |
+-----------------------------------------------------------------------------------------+
查询有向边相关联的点
在当前图中,当需要查询 1 跳范围内通过有向边连接的点时,可以用 -->(即正向边)或 <--(即反向边)表示。
-
查询通过正向边/反向边相关的所有点
示例 1
在当前图中查询 1 跳范围内通过正向边相关的所有点。命令如下:MATCH (n)-->(m)
RETURN m;返回结果示例如下:
+-----------------------------------------------------------------------------------------+
| m |
+=========================================================================================+
| vid: [_oid: 36998642535497728, label: person], properties: [36998642535497728, 1, John] |
+-----------------------------------------------------------------------------------------+
| vid: [_oid: 36998642535497729, label: person], properties: [36998642535497729, 2, Mary] |
+-----------------------------------------------------------------------------------------+示例 2
在当前图中查询 1 跳范围内通过反向边相关的所有点。命令如下:MATCH (n)<--(m)
RETURN m;返回结果示例如下:
+-----------------------------------------------------------------------------------------+
| m |
+=========================================================================================+
| vid: [_oid: 36998642535497729, label: person], properties: [36998642535497729, 2, Mary] |
+-----------------------------------------------------------------------------------------+
| vid: [_oid: 36998642535497728, label: person], properties: [36998642535497728, 1, John] |
+-----------------------------------------------------------------------------------------+ -
查询与指定点通过正向边/反向边相关的所有点
示例 1
在当前图中查询 1 跳范围内与指定点“John”通过正向边相关的所有点。命令如下:MATCH (n:person { name: 'John' })-->(m)
RETURN m;返回结果示例如下:
+-----------------------------------------------------------------------------------------+
| m |
+=========================================================================================+
| vid: [_oid: 36998642535497729, label: person], properties: [36998642535497729, 2, Mary] |
+-----------------------------------------------------------------------------------------+示例 2
在当前图中查询 1 跳范围内与指定点“John”通过反向边相关的所有点。命令如下:MATCH (n:person { name: 'John' })<--(m)
RETURN m;返回结果示例如下:
+-----------------------------------------------------------------------------------------+
| m |
+=========================================================================================+
| vid: [_oid: 36998642535497729, label: person], properties: [36998642535497729, 2, Mary] |
+-----------------------------------------------------------------------------------------+
查询与指定边类型相关联的所有点
-
查询单个边类型相关联的所有点
查询当前图中某一个边类型关联的所有点。
示例 1
在当前图中查询与“Mary”具有“like”关联关系的所有点。命令如下:MATCH (n)-[:like]->(m:person {name: 'Mary'})
RETURN n;返回结果示例如下:
+-----------------------------------------------------------------------------------------+
| n |
+=========================================================================================+
| vid: [_oid: 36998642535497728, label: person], properties: [36998642535497728, 1, John] |
+-----------------------------------------------------------------------------------------+示例 2
在当前图中查询具有“like”关联关系的所有点,命令如下:MATCH (n)-[:like]->(m)
RETURN n;返回结果示例如下:
+-----------------------------------------------------------------------------------------+
| n |
+=========================================================================================+
| vid: [_oid: 36998642535497729, label: person], properties: [36998642535497729, 2, Mary] |
+-----------------------------------------------------------------------------------------+
| vid: [_oid: 36998642535497728, label: person], properties: [36998642535497728, 1, John] |
+-----------------------------------------------------------------------------------------+ -
查询多个边类型相关联的所有点
查询当前图中多个边类型关联的所有点,可以用“|”(“或”符号)将不同边类型连接在一起,各边类型间为“或”的关系。
示例
在当前图中查询具有“like”或“know”关联关系的所有点。命令如下:MATCH (n)-[:like|know]->(m:person {name: 'Mary'})
RETURN n;返回结果示例如下:
+-----------------------------------------------------------------------------------------+
| n |
+=========================================================================================+
| vid: [_oid: 36998642535497728, label: person], properties: [36998642535497728, 1, John] |
+-----------------------------------------------------------------------------------------+
查询边
查询所有的边
查询当前图中 1 跳范围内所有的边。
示例
在当前图中查询 1 跳范围内所有的边。命令如下:
MATCH (n)-[r]->(m)
RETURN r;
返回结果示例如下:
+-----------------------------------------------------------------------------------------------------------------------------------------------------+
| r |
+=====================================================================================================================================================+
| eid: [src: [_oid: 36990974638948352, label: person], dest: [_oid: 36990974643142657, label: person], label: like, _ts: 0], properties: [喜欢, 2020] |
+-----------------------------------------------------------------------------------------------------------------------------------------------------+
查询指定点之间的边
查询 1 跳范围内与指定点相关联的所有边。
示例
在当前图中查询 1 跳范围内“John”与“Mary”之间所有的边。命令如下:
MATCH (n:person { name: 'John' })-[r]->(m:person { name: 'Mary' })
RETURN r;
返回结果示例如下:
+-----------------------------------------------------------------------------------------------------------------------------------------------------+
| r |
+=====================================================================================================================================================+
| eid: [src: [_oid: 36990974638948352, label: person], dest: [_oid: 36990974643142657, label: person], label: like, _ts: 0], properties: [喜欢, 2020] |
+-----------------------------------------------------------------------------------------------------------------------------------------------------+
查询边类型属性
在当前图中,查询两个点之间边的类型以及属性。
示例 1
在当前图中查询“John”与“Mary”之间所有边的边类型。命令如下:
MATCH (n:person { name: 'John' })-[r]->(m:person { name: 'Mary' })
RETURN type(r);
返回结果示例如下:
+---------+
| type(r) |
+=========+
| like |
+---------+
示例 2
在当前图中查询“John”与“Mary”之间所有边的属性“name”。命令如下:
MATCH (n:person { name: 'John' })-[r]->(m:person { name: 'Mary' })
RETURN r.name;
返回结果示例如下:
+--------+
| r.name |
+========+
| 喜欢 |
+--------+
查询多重边
在 ArcGraph 图数据库中,通过 () -[]- () 边模式,可以将多个边连接在一起。
示例
在当前图中查询名为“John”的人正在学习的书籍,以及这些书籍的作者。命令如下:
MATCH (n:person { name: 'John' })-[:learning]->(p:book)<-[:author]-(m:person)
RETURN p.name, m.name;
返回结果示例如下:
+--------+--------+
| p.name | m.name |
+========+========+
| book1 | Mary |
+--------+--------+
查询可变长度边
当两点间的边、路径长度、点的度数等可变时,使用 -[:TYPE*minHops..maxHops]→ 语句可查找满足条件的点。-[:TYPE*minHops..maxHops]→ 语句的详细说明如下:
-[:TYPE*minHops..maxHops]→语句中,minHops和maxHops表示路径中边的数量(跳数)的边界值。minHops表示路径中至少要经过的边数。默认情况下,其取值范围为大于等于 0 的整数,可根据实际情况设置该参数值,当省略该参数时则使用默认值 1;当设置为 0 时,则表示可以包括起点本身(即没有边的路径)。maxHops表示路径中最多可以经过的边数,默认情况下,其取值范围为 1~8 ��的整数。可根据实际情况设置该参数值,当省略该参数时则使用默认值 8。通过SET SESSION或SET GLOBAL命令调整compiler_max_var_hops参数可以自定义maxHops的取值范围,详情请参见 更改系统变量 章节。- 当未给定边界值时,表示
minHops和maxHops参数使用默认值,此时minHops和maxHops间的“..”可省略,例如[:like*],表示长度为 1~8 跳范围内的路径。 - 当只给定一个边界值并省略
minHops和maxHops间的“..”时,表示该路径长度固定。例如[:like*2],表示该路径长度固定为 2。 - 当两个点之间的路径长度为零时,即零度边,意味着它们实际上是同一个点,因此,即使在没有边数据的边类型上进行匹配,返回结果仍会包含该点本身。
示例 1
在当前图中查询路径长度为 0 跳且与“John”有“like”关联关系的所有点,命令如下:
MATCH (m:person {name: 'John'})-[*0]-(x)
RETURN x;
返回结果示例如下:
+-----------------------------------------------------------------------------------------+
| x |
+=========================================================================================+
| vid: [_oid: 36998642535497728, label: person], properties: [36998642535497728, 1, John] |
+-----------------------------------------------------------------------------------------+
示例 2
MATCH (m:person {name: 'John'})-[*0..1]-(x)
RETURN x;
返回结果示例如下:
+-----------------------------------------------------------------------------------------+
| x |
+=========================================================================================+
| vid: [_oid: 36998642535497728, label: person], properties: [36998642535497728, 1, John] |
+-----------------------------------------------------------------------------------------+
| vid: [_oid: 36998642535497729, label: person], properties: [36998642535497729, 2, Mary] |
+-----------------------------------------------------------------------------------------+
| vid: [_oid: 36998642535497729, label: person], properties: [36998642535497729, 2, Mary] |
+-----------------------------------------------------------------------------------------+
示例 3
在当前图中查询 1~3 跳范围内与“John”有“like”关联关系的所有点,命令如下:
MATCH (n:person {name:'John'})-[:like*1..3]->(m:person)
RETURN m.name;
返回结果示例如下:
+--------+
| m.name |
+========+
| Mary |
+--------+
| John |
+--------+
| Mary |
+--------+
示例 4
在当前图中查询 1~2 跳范围内与“John”有“like”关联关系的所有点,命令如下:
MATCH (n:person {name:'John'}) - [r:like * ..2] -> (m:person)
RETURN m.name;
返回结果示例如下:
+--------+
| m.name |
+========+
| Mary |
+--------+
| John |
+--------+
示例 5
默认情况下,在当前图中查询 1~8 跳范围内与“John”有“like”关联关系的所有点,命令如下:
MATCH (n:person {name:'John'}) - [r:like * ..] -> (m:person)
RETURN m.name;
返回结果示例如下:
+--------+
| m.name |
+========+
| Mary |
+--------+
| John |
+--------+
| Mary |
+--------+
| John |
+--------+
| Mary |
+--------+
| John |
+--------+
| Mary |
+--------+
| John |
+--------+
示例 6
在当前图中查询路径长度为 2 跳且与“John”有“like”关联关系的所有点,命令如下:
MATCH (n:person {name:'John'}) - [r:like *2] -> (m:person)
RETURN m.name;
返回结果示例如下:
+--------+
| m.name |
+========+
| John |
+--------+
查询路径
在 ArcGraph 图数据库中,通过路径查询可以查找和返回当前图中从一点到另一点的完整路径。路径的基本查询如下,更多操作请参考 路径函数 章节。
查询所有路径
在当前图中查询和返回长度大于等于 1 跳的所有路径。
示例
在当前图中查询长度大于等于 1 跳的所有路径。命令如下:
MATCH p = (n)-[*]->()
RETURN p;
返回结果示例如下:
+---------------------------------------------------------------------------------------------------------------------------------+
| p |
+=================================================================================================================================+
| Path: [ |
| Vertex _oid: 36998642535497728, label: person |
| -> Edge src: [_oid: 36998642535497728, label: person], dest: [_oid: 36998642535497729, label: person], label: like, _ts: 0 |
| -> Vertex _oid: 36998642535497729, label: person |
| ] |
+---------------------------------------------------------------------------------------------------------------------------------+
查询从指定点开始的所有路径
在 ArcGraph 图数据库中,查询从指定点开始的所有路径。
示例
在当前图中查询从“John”点开始的所有路径。命令如下:
MATCH p = (n:person {name:'John'})-[*]->()
RETURN p;
返回结果示例如下:
+---------------------------------------------------------------------------------------------------------------------------------+
| p |
+=================================================================================================================================+
| Path: [ |
| Vertex _oid: 36998642535497728, label: person |
| -> Edge src: [_oid: 36998642535497728, label: person], dest: [_oid: 36998642535497729, label: person], label: like, _ts: 0 |
| -> Vertex _oid: 36998642535497729, label: person |
| ] |
+---------------------------------------------------------------------------------------------------------------------------------+
查询指定长度范围内的所有路径
查询路径长度在指定范围内的所有路径。
示例
在当前图中查询通过“like”边连接的 id 为“1”和“3”的“person”点之间,路径长度在 1 到 3 范围内的所有路径。命令如下:
MATCH p=allPath((m: person {id: 1})-[e:like*1..3]->(n:person{id: 2}) )
RETURN p;
返回结果示例如下:
+---------------------------------------------------------------------------------------------------------------------------------+
| p |
+=================================================================================================================================+
| Path: [ |
| Vertex _oid: 36998015365414912, label: person |
| -> Edge src: [_oid: 36998015365414912, label: person], dest: [_oid: 36998015365414913, label: person], label: like, _ts: 0 |
| -> Vertex _oid: 36998015365414913, label: person |
| -> Edge src: [_oid: 36998015365414913, label: person], dest: [_oid: 36998015365414914, label: person], label: like, _ts: 0 |
| -> Vertex _oid: 36998015365414914, label: person |
| ] |
+---------------------------------------------------------------------------------------------------------------------------------+
| Path: [ |
| Vertex _oid: 36998015365414912, label: person |
| -> Edge src: [_oid: 36998015365414912, label: person], dest: [_oid: 36998015365414915, label: person], label: like, _ts: 0 |
| -> Vertex _oid: 36998015365414915, label: person |
| -> Edge src: [_oid: 36998015365414915, label: person], dest: [_oid: 36998015365414914, label: person], label: like, _ts: 0 |
| -> Vertex _oid: 36998015365414914, label: person |
| ] |
+---------------------------------------------------------------------------------------------------------------------------------+
查询最短路径
查询两点间存在的最短路径。当存在多条最短路径时,ShortestPath() 函数将随机选择一条最短路径返回。
示例
在当前图中查询通过“like”边连接的 id 为“1”和“3”的“person”点之间,路径长度不超过 3 跳的单个最短路径。命令如下:
MATCH p=ShortestPath((m: person {id: 1})-[e:like*..3]-(n:person{id: 3}) )
RETURN p;
返回结果示例如下:
+---------------------------------------------------------------------------------------------------------------------------------+
| p |
+=================================================================================================================================+
| Path: [ |
| Vertex _oid: 36998015365414912, label: person |
| -> Edge src: [_oid: 36998015365414912, label: person], dest: [_oid: 36998015365414913, label: person], label: like, _ts: 0 |
| -> Vertex _oid: 36998015365414913, label: person |
| -> Edge src: [_oid: 36998015365414913, label: person], dest: [_oid: 36998015365414914, label: person], label: like, _ts: 0 |
| -> Vertex _oid: 36998015365414914, label: person |
| ] |
+---------------------------------------------------------------------------------------------------------------------------------+
查询所有最短路径
查询两点之间存在的所有最短路径。
示例
在当前图中查询通过“like”边连接的 id 为“1”和“3”的“person”点之间,路径长度不超过 3 跳的所有最短路径。命令如下:
MATCH (m: person {id: 1}),(n:person{id: 3}) WITH m,n,
allShortestPaths((m)-[e:like*..3]->(n)) AS p
RETURN p;
返回结果示例如下:
+---------------------------------------------------------------------------------------------------------------------------------+
| p |
+=================================================================================================================================+
| Path: [ |
| Vertex _oid: 36998015365414912, label: person |
| -> Edge src: [_oid: 36998015365414912, label: person], dest: [_oid: 36998015365414913, label: person], label: like, _ts: 0 |
| -> Vertex _oid: 36998015365414913, label: person |
| -> Edge src: [_oid: 36998015365414913, label: person], dest: [_oid: 36998015365414914, label: person], label: like, _ts: 0 |
| -> Vertex _oid: 36998015365414914, label: person |
| ] |
+---------------------------------------------------------------------------------------------------------------------------------+
| Path: [ |
| Vertex _oid: 36998015365414912, label: person |
| -> Edge src: [_oid: 36998015365414912, label: person], dest: [_oid: 36998015365414915, label: person], label: like, _ts: 0 |
| -> Vertex _oid: 36998015365414915, label: person |
| -> Edge src: [_oid: 36998015365414915, label: person], dest: [_oid: 36998015365414914, label: person], label: like, _ts: 0 |
| -> Vertex _oid: 36998015365414914, label: person |
| ] |
+---------------------------------------------------------------------------------------------------------------------------------+
弱类型查询
在 ArcGraph 图数据库中,当查询的类型或属性不存在时系统默认会报错并提示该类型或属性不存在。但从 v2.1.3 版本开始,用户可以通过配置参数选择此类情况下返回空值或报错。
语法
SET SESSION|GLOBAL compiler_enable_type_check = {true|false};
详细说明
compiler_enable_type_check参数用于控制类型检查的启用状态。默认情况下,该参数设置为true,即启用类型检查,当查询的类型或属性不存在时,系统会报错并提示相应信息。若设置为false,则启用弱类型检查,此时若查询的类型或属性不存在,将返回空值。compiler_enable_type_check参数支持全局(Global)和会话(Session)两个级别的设置,以满足不同用户的需求。详情请参见 配置参数 章节。
应用示例
数据准备
DROP GRAPH IF EXISTS TEST_CHECK_TYPE;
CREATE GRAPH IF NOT EXISTS TEST_CHECK_TYPE;
USE TEST_CHECK_TYPE;
CREATE VERTEX person(PRIMARY KEY id INT64, name String NOT NULL, age INT64 NULL);
CREATE EDGE knows (creationDate string NULL, INDEX creation_date_index(creationDate), FROM person TO person) ;
INSERT (n:person{id:1, name:'aaa'}), (m:person{id:2, name:'bbb'});
INSERT (n:person {id: 1})-[e:knows {creationDate: '2023-05-12'}]->(m:person {id: 2});
查询类型不存在
当 compiler_enable_type_check=false 时开启弱类型检查模式。在此模式下,若查询的类型不存在,则返回结果为空。
-
示例 1
# 启用类型检查
SET SESSION compiler_enable_type_check=true;
# 查询类型不存在
MATCH (a:person3)
RETURN a;返回结果示例如下:
+--------------------------------------------------------------------------------------+
| error |
+======================================================================================+
| Code: 6004, VERTEX_TYPE_NOT_FOUND: Vertex type name is person3 and Graph Id is 2731. |
+--------------------------------------------------------------------------------------+ -
示例 2
# 启用弱类型检查
SET SESSION compiler_enable_type_check=false;
# 查询类型不存在
MATCH (a:person3)
RETURN a;返回结果示例如下:
+---+
| a |
+===+
+---+
查询属性不存在
当 compiler_enable_type_check=false 时开启弱类型检查模式。在此模式下,若查询的属性不存在,则返回结果为 null。
-
示例 1
# 启用类型检查
SET SESSION compiler_enable_type_check=true;
# 查询属性不存在
MATCH (a:person {id: 1})
RETURN a.xx;返回结果示例如下:
+--------------------------------------------------------------------------------------------------+
| error |
+==================================================================================================+
| Code: 3302, INVALID_PROPERTY_EXPR: Variable 'a' of schemas ["person"] do not have property 'xx'. |
+--------------------------------------------------------------------------------------------------+ -
示例 2
# 启用弱类型检查
SET SESSION compiler_enable_type_check=false;
# 查询属性不存在
MATCH (a:person {id: 1})
RETURN a.xx;返回结果示例如下:
+------+
| a.xx |
+======+
| null |
+------+
查询同时包含存在和不存在的类型或属性
当 compiler_enable_type_check=false 时开启弱类型检查模式。在此模式下,针对同时包含存在和不存在的类型或属性的查询,返回存在的结果。
-
示例 1
# 启用类型检查
SET SESSION compiler_enable_type_check=true;
# 查询同时包含存在和不存在的类型或属性
MATCH (a:person|person2 {id: 1}
RETURN a.id, a.xx;返回结果示例如下:
+--------------------------------------------------------------------------------------+
| error |
+======================================================================================+
| Code: 6004, VERTEX_TYPE_NOT_FOUND: Vertex type name is person2 and Graph Id is 2731. |
+--------------------------------------------------------------------------------------+ -
示例 2
# 启用弱类型检查
SET SESSION compiler_enable_type_check=false;
# 查询同时包含存在和不存在的类型或属性
MATCH (a:person|person2 {id: 1}
RETURN a.id, a.xx;返回结果示例如下:
+------+------+
| a.id | a.xx |
+======+======+
| 1 | null |
+------+------+
子句
RETURN
在 MATCH 查询语句中,可以使用 RETURN 子句对想要查询的内容加以界定并返回,界定的内容可以是点、边或属性。
如果只查询属性值,建议不要返回完整的点或边。这样做有助于提高查询性能,减少数据传输量和处理时间。
-
返回点
使用
RETURN子句返回所需的点。示例
查询名为“John”的点,命令如下:MATCH (n:person {name:'John'})
RETURN n;返回结果示例如下:
+---------------------------------------------------------------------------------------------+
| n |
+=============================================================================================+
| vid: [_oid: 36990974638948352, label: person], properties: [36990974638948352, 1, John, 30] |
+---------------------------------------------------------------------------------------------+ -
返回边
使用
RETURN子句返回所需的边。示例
返回“John”喜欢的人的边,命令如下:MATCH (n:person {name:'John'})-[r:like]->(:person)
RETURN r;返回结果示例如下:
+-----------------------------------------------------------------------------------------------------------------------------------------------------+
| r |
+=====================================================================================================================================================+
| eid: [src: [_oid: 36990974638948352, label: person], dest: [_oid: 36990974643142657, label: person], label: like, _ts: 0], properties: [喜欢, 2020] |
+-----------------------------------------------------------------------------------------------------------------------------------------------------+ -
返回属性
返回属性时,请使用点操作符来获取属性。若要返回属性值,则该点所属的点类型不能省略。
示例
返回“John”点的name属性,命令如下:MATCH (n:person {name:'John'})
RETURN n.name;返回结果示例如下:
+----------+
| n.name |
+==========+
| John |
+----------+ -
返回所有元素
如果要返回查询中的所有点、边和路径,使用“*”符号。
示例
返回查询“John”过程中,所有与之相关的点、边和路径。命令如下:MATCH p =(a:person {name:'John'})-[r]->(b)
RETURN *;返回结果示例如下:
+---------------------------------------------------------------------------------------------+---------------------------------------------------------------------------------------------+-------------------------------------------------------------------------------------------------------------------------------+-----------------------------------------------------------------------------------------------------------------------------------------------------+
| a | b | p | r |
+=============================================================================================+=============================================================================================+===============================================================================================================================+=====================================================================================================================================================+
| vid: [_oid: 36990974638948352, label: person], properties: [36990974638948352, 1, John, 30] | vid: [_oid: 36990974643142657, label: person], properties: [36990974643142657, 2, Mary, 25] | Path: [ | eid: [src: [_oid: 36990974638948352, label: person], dest: [_oid: 36990974643142657, label: person], label: like, _ts: 0], properties: [喜欢, 2020] |
| | | Vertex _oid: 36990974638948352, label: person | |
| | | -> Edge src: [_oid: 36990974638948352, label: person], dest: [_oid: 36990974643142657, label: person], label: like, _ts: 0 | |
| | | -> Vertex _oid: 36990974643142657, label: person | |
| | | ] | |
+---------------------------------------------------------------------------------------------+---------------------------------------------------------------------------------------------+-------------------------------------------------------------------------------------------------------------------------------+-----------------------------------------------------------------------------------------------------------------------------------------------------+ -
列别名
查询结果返回的列名可能是数据库中存储的原始列名或属性名。但有时这些列名可能过长、不易理解或与其他列冲突。为了解决��这个问题,可以使用列别名来为查询结果中的列或属性提供一个更简洁、易懂的名称。列别名可以在查询中使用“AS +新名称”来定义。
示例
返回“John”点的name属性,但重命名为“former_name”曾用名。命令如下:MATCH (n:person {name:'John'})
RETURN n.name AS former_name;返回结果示例如��下:
+-------------+
| former_name |
+=============+
| John |
+-------------+ -
结果去重
使用
DISTINCT子句,为返回结果去除重复项。示例
查询并返回与“John”点有关联关系的点,若数据重复,则只返回一个,命令如下:MATCH (a:person {name:'John'})-->(b:person)
RETURN DISTINCT b.name;返回结果示例如下:
+--------+
| b.name |
+========+
| Mary |
+--------+ -
其他表达式
查询中的
RETURN部分也可以用来返回常量,表达式,函数等。- 计算表达式支持”+“、”-“、”*“、”/“、”%“等二元操作符,和”+“、”-“、”^(幂次)“等一元操作。
- 函数目前只支持
id和type函数。
示例 1
使用RETURN返回计算表达式,命令如下:MATCH (m:person {name:'John'})-[r:like]->(n:person)
RETURN n.id, n.id%10+1, 1;返回结果示例如下:
+------+---------------+---+
| n.id | n.id % 10 + 1 | 1 |
+======+===============+===+
| 2 | 3 | 1 |
+------+---------------+---+示例 2
使用RETURN返回点的 ID 和点类型 ID。命令如下:MATCH (m:person) -[:like] -> (n:person)
WHERE id(m) = 1
RETURN id(n), type_id(n);返回结果示例如下:
+-------+------------+
| id(n) | type_id(n) |
+=======+============+
| 1 | 1 |
+-------+------------+
WITH
WITH 子句在图数据库查询中起到非常关键的作用,它能够将多个查询语句串联起来,并传递一部分查询结果作为下一查询的起始点。这使得查询过程更加灵活,并能显著减少重复计算和数据冗余。
说明:
WITH子句中的表达式必须具有别名,或自身可作为别名(如变量、点、边、路径)。例如,WITH m.id是错误的,可能会引发INVALID_EXPRESSION错误,而WITH m.id AS m_id是正确的,因为它为表达式m.id指定了别名m_id。WITH中变量的可见性约束如下。- 若
WITH/RETURN子句中包含DISTINCT或聚合函数,则子句仅传递WITH/RETURN中的变量/别名。 - 若
WITH/RETURN子句中不包含DISTINCT或聚合函数,则前一句的变量可被ORDER BY和WHERE子句使用。 - 若
WITH/RETURN子句中已指定别名,则只有别名可在ORDER BY和WHERE子句中使用,原始名称不可见。
- 若
计算中间结果
在 WITH 子句中可以定义计算表达式,以计算中间结果。
示例
查找所有通过“like”边连接的“person”点,计算每个人 10 年后的年龄,并返回这些人的名字以及他们喜欢的人 10 年后的平均年龄。命令如下:
MATCH (m:person)-[e:like]->(n:person)
WITH
m.age + 10 AS m_ten_years_later,
n.age + 10 AS n_ten_years_later,
m.name AS m_name,
n.name AS n_name
RETURN m_name, avg(n_ten_years_later);
返回结果示例如下:
+--------+------------------------+
| m_name | AVG(n_ten_years_later) |
+========+========================+
| Mary | 32 |
+--------+------------------------+
| Xiaoli | 32 |
+--------+------------------------+
| John1 | 37 |
+--------+------------------------+
聚合中间结果
在 WITH 子句中可以进行聚合计算,以获取中间结果。
示例
查找所有通过“like”边连接的“person”点,计算他们 10 年后的年龄以及他们喜欢的人 10 年后的平均年龄,并返回 2 个结果。命令如下:
MATCH (m:person)-[e:like]->(n:person)
WITH
m.name as m_name,
m.age + 10 as m_ten_years_later,
avg(n.age + 10) as avg_n_ten_years_later
RETURN m_name, m_ten_years_later, avg_n_ten_years_later
LIMIT 2;
返回结果示例如下:
+--------+-------------------+-----------------------+
| m_name | m_ten_years_later | avg_n_ten_years_later |
+========+===================+=======================+
| Xiaoli | 40 | 32 |
+--------+-------------------+-----------------------+
| John1 | 40 | 37 |
+--------+-------------------+-----------------------+
去重中间结果
在 WITH 子句中使用 DISTINCT 关键字来确保中间结果的唯一性,避免重复数据对后续查询结果造成干扰。
示例
查找所有通过“like”边连接的“person”点,并返回 2 个他们去重后的名字。命令如下:
MATCH (m:person)-[e:like]->(n:person)
WITH DISTINCT m.name AS m_name, n.name AS n_name
RETURN m_name, n_name
LIMIT 2;
返回结果示例如下:
+--------+--------+
| m_name | n_name |
+========+========+
| Mary | Jerry |
+--------+--------+
| John1 | Mary |
+--------+--------+
返回中间结果
使用 WITH 子句返回中间结果,以便在后续的查询中重复使用这些结果。
示例
查找所有通过“like”边连接的“person”点,并返回 2 个他们去重后的名字。命令如下:
MATCH (m:person)-[e:like]->(n:person)
WITH DISTINCT m.name AS m_name, n.name AS n_name
LIMIT 2
RETURN m_name, n_name;
返回结果示例如下:
+--------+--------+
| m_name | n_name |
+========+========+
| Xiaoli | Jerry |
+--------+--------+
| John1 | Mary |
+--------+--------+
中间结果排序
使用 WITH 子句可以对中间结果进行排序。通过指定排序条件,您可以按照特定的顺序获取中间结果。
示例
查找所有通过“like”边连接的“person”点,并按照他们的名字进行排序,返回前 2 个去重后的名字。命令如下:
MATCH (n:person)-[e:like]->(m:person)
WITH DISTINCT m.name AS name
ORDER BY name
LIMIT 2
RETURN name;
返回结果示例如下:
+-------+
| name |
+=======+
| John |
+-------+
| Mary |
+-------+
过滤聚合结果
在 WITH 子句中支持使用 WHERE 条件子句来过滤掉某些不符合条件的聚合结果。
示例
查找所有通过“like”边连接的“person”点,计算每个人喜欢的其他人的数量,返回喜欢人数超过 2 的人的名字和喜欢人数,并按照名字和喜欢人数进行排序。命令如下:
MATCH (m:person)-[e:like]->(n:person)
WITH m.name AS m_name, count(n) AS count_n
WHERE count_n > 2
RETURN m_name, count_n
ORDER BY m_name, count_n;
返回结果示例如下:
+--------+---------+
| m_name | count_n |
+========+=========+
| Mary | 3 |
+--------+---------+
WHERE
WHERE 是 MATCH 语句的子句,为 MATCH 语句添加约束或过滤查询结果。
基本用法
-
逻辑运算
可以在
WHERE子句中使用布尔运算符AND、OR、XOR和NOT等。示例
在当前图中找到所有名为“John”或者年龄小于 45 且名字既不是“Mary”,也不是“Zhangwu”而是名字为“Zhangsan”的点,并返回这些点的名称和年龄。命令如下:MATCH (n:person)
WHERE (n.name = 'John' OR (n.age < 45 AND n.name = 'Zhangsan')) AND NOT (n.name = 'Mary' OR n.name = 'Zhangwu')
RETURN n.name, n.age;返回结果示例如下:
+--------------+-------+
| n.name | n.age |
+==============+=======+
| John | 30 |
+--------------+-------+
| Zhangsan | 40 |
+--------------+-------+ -
过滤点属性
过滤点属性时,请在
WHERE关键字后添加过滤条件。示例
返回“person”点类型中所有“age> 18”的点数据的名称和年龄,命令如下:MATCH (n:person)
WHERE n.age > 18
RETURN n.name, n.age;返回结果示例如下:
+--------------+-------+
| n.name | n.age |
+==============+=======+
| Zhangsan | 40 |
+--------------+-------+
| Mary | 22 |
+--------------+-------+
| John | 30 |
+--------------+-------+
字符串匹配
STARTS WITH 和 ENDS WITH 可以匹配字符串的前缀和后缀。如要进行子字符串搜索,可以使用 CONTAINS 子句。
字符串匹配时,请注意区分字符串的大小写。
-
使用
STARTS WITH进行前缀字符串搜索在字符串的前缀部分执行区分大小写的匹配查询时,可以使用
STARTS WITH来优化查询。示例
在当前图中,返回 “person”点类型中,姓名是以 “J” 为首的人物的id。命令如下:MATCH (a:person)
WHERE a.name STARTS WITH 'J'
RETURN a.id;返回结果示例如下:
+------+
| a.id |
+======+
| 1 |
+------+ -
使用
ENDS WITH进行后缀字符串搜索在字符串的后缀部分执行区分大小写的匹配查询时,可以使用
ENDS WITH来优化查询。示例
在当前图中,返回 “person”点类型中,姓名是以 “y” 为结尾的人物的id。命令如下:MATCH (a:person)
WHERE a.name ENDS WITH 'y'
RETURN a.id;返回结果示例如下:
+------+
| a.id |
+======+
| 2 |
+------+ -
使用
CONTAINS进行子字符串搜索使用
CONTAINS匹配字符串中是否包含某个字符串。示例
在当前图中,返回 “person”点类型中,姓名中包含 “y” 的人物姓名。命令如下:MATCH (a:person)
WHERE a.name CONTAINS 'y'
RETURN a.name;返回结果示例如下:
+---------+
| a.name |
+=========+
| Mary |
+---------+
IN 表达式过滤
IN 运算符可用于检查列表中是否存在某个元素。
IN 左右两侧只能为同种数据类型,右边的列表也只能为同种数据类型的常量。
示例
在当前图中,查找“person”点类型中,名为“John”和“Mary”的点,并返回这些点的姓名和出生年份。命令如下:
MATCH (a:person)
WHERE a.name IN ['John','Mary']
RETURN a.name, a.age;
返回结果示例如下:
+----------+-------+
| a.name | a.age |
+==========+=======+
| John | 30 |
+----------+-------+
| Mary | 22 |
+----------+-------+
is [not] null 表达式过滤
一般用于判断属性中值是否为 null。
示例 1
在当前图中,查找“book”点类型中,name 属性值为空的点,并返回这些点的 id。命令如下:
MATCH (n:book)
WHERE n.name IS NULL
RETURN n.id;
返回结果示例如下:
+---------+
| n.id |
+=========+
| 2 |
+---------+
示例 2
在当前图中,查找“book”点类型中,name 属性值不为空的点,并返回这些点的 id。命令如下:
MATCH (n:book)
WHERE n.name IS NOT NULL
RETURN n.id;
返回结果示例如下:
+---------+
| n.id |
+=========+
| 1 |
+---------+
范围过滤(比较表达式)
-
简单范围过滤
在特定范围内查找一定元素时,可以使用不等操作符
“<”、“<=”、“>=”、“>”等。示例
在当前图中,返回年龄大于或等于 18 的点,命令如下:MATCH (n)
WHERE n.age >= 18
RETURN n;返回结果示例如下:
+----------------------------------------------------------------------------------------------+
| n |
+==============================================================================================+
| vid: [_oid: 36990974643142658, label: person], properties: [36990974643142658, 3, Jerry, 22] |
+----------------------------------------------------------------------------------------------+
| vid: [_oid: 36990974643142657, label: person], properties: [36990974643142657, 2, Mary, 25] |
+----------------------------------------------------------------------------------------------+
| vid: [_oid: 36990974638948352, label: person], properties: [36990974638948352, 1, John, 30] |
+----------------------------------------------------------------------------------------------+ -
复合范围过滤
使用多个不等式构建查询范围。
示例
在当前图中,返回年龄大于或等于 18 且小于 30 的点,命令如下:MATCH (n)
WHERE n.age >= 18 and n.age < 30
RETURN n;返回结果示例如下:
+----------------------------------------------------------------------------------------------+
| n |
+==============================================================================================+
| vid: [_oid: 36990974643142658, label: person], properties: [36990974643142658, 3, Jerry, 22] |
+----------------------------------------------------------------------------------------------+
| vid: [_oid: 36990974643142657, label: person], properties: [36990974643142657, 2, Mary, 25] |
+----------------------------------------------------------------------------------------------+ -
其他
在
WHERE子句中使用计算表达式和函数。示例 1
在当前图中,查找id为“1”且age为“30”的“person”点类型中的点,或是creation_date为“2019”的“movie”点类型中的点,并返回这些点的名�称和id属性。命令如下:MATCH (m:person|movie)
WHERE
type(m) = "person" and m.id = 1 and m.age =30
OR type(m) = "movie" and m.creation_date = 2019
RETURN m.name,m.id;返回结果示例如下:
+----------+------+
| m.name | m.id |
+==========+======+
| John | 1 |
+----------+------+
| 电影2 | 2 |
+----------+------+示例 2
在当前图的“person”点类型中查找所有id属性大于“1”的点,并返回这些点的名称和id属性。命令如下:MATCH (m:person)
WHERE id(m) > 1
RETURN m.name,m.id;返回结果示例如下:
+--------------+------+
| m.name | m.id |
+==============+======+
| Zhangwu | 4 |
+--------------+------+
| Zhangsan | 3 |
+--------------+------+
| Mary | 2 |
+--------------+------+
路径表达式过滤
路径表达式过滤用于检查给定路径是否在当前图中至少存在一次。
语法
WHERE [NOT] <path_pattern> [AND <expression>]...
详细说明
<path_pattern>:定义路径模式的表达式,通常采用(a)-[f]-(b)的格式。在WHERE子句中,只能存在一个路径模式表达式,且该表达式与其他WHERE子句的过滤表达式之间仅支持使用AND逻辑运算符。<expression>:除<path_pattern>外的其他WHERE子句的过滤表达式。
示例 1
在当前图中,查询名为“Jhon”的人喜欢的人员,命令如下:
MATCH (b:person)
WHERE (a:person{name:'John'})-[:like]->(b:person)
RETURN b;
返回结果示例如下:
+---------------------------------------------------------------------------------------------+
| b |
+=============================================================================================+
| vid: [_oid: 36990974643142657, label: person], properties: [36990974643142657, 2, Mary, 25] |
+---------------------------------------------------------------------------------------------+
示例 2
在当前图中,查询名为"John"的人喜欢的人员中不喜欢"Jerry"的人员,命令如下:
MATCH (r:person{name:'John'})-[:like]->(a:person)
WHERE NOT (a:person)-[:like]->(b:person {name: "Jerry"})
RETURN r.name, a.name;
返回结果示例如下:
+--------+--------+
| r.name | a.name |
+========+========+
| John | Mary |
+--------+--------+
ORDER BY
ORDER BY 是在 RETURN 或 WITH 后的子句,它可以对输出结果进行排序并指定相应的排序方式。
目前 ORDER BY 只能对属性进行排序,暂不支持对属性的别名进行排序。
-
根据属性排序
ORDER BY用于对输出结果进行排序,默认按照升序进行排序。示例
在当前图中返回“person”点类型中的所有点,并按其name属性排序,命令如下:MATCH (n:person)
RETURN n.name, n.age
ORDER BY n.name;返回结果示例如下:
+--------------+-------+
| n.name | n.age |
+==============+=======+
| John | 30 |
+--------------+-------+
| Mary | 22 |
+--------------+-------+
| Zhangsan | 40 |
+--------------+-------+
| Zhangwu | 18 |
+--------------+-------+ -
根据多个属性排序
如要按多个属性排序,需在
ORDER BY子句中声明多个变量。OpenCypher 按声明的变量进行升序排序,如果该变量值相等,再按照指定的下一个变量进行排序,依次类推。示例
在当前图中返回“person”点类型中的所有点,并先根据age属性排序,再按照name属性排序,命令如下:MATCH (n:person)
RETURN n.age ,n.name
ORDER BY n.age, n.name;返回结果示例如下:
+-------+--------------+
| n.age | n.name |
+=======+==============+
| 18 | Zhangwu |
+-------+--------------+
| 22 | Mary |
+-------+--------------+
| 30 | John |
+-------+--------------+
| 40 | Zhangsan |
+-------+--------------+ -
根据属性降序排序
在排序变量后加
DESC子句,ORDER BY会进行降序排序。示例
在当前图中返回“person”点类型中的所有点,并先根据name属性降序排序,命令如下:MATCH (n:person)
RETURN n.name, n.age
ORDER BY n.name DESC;返回结果示例如下:
+--------------+-------+
| n.name | n.age |
+==============+=======+
| Zhangwu | 18 |
+--------------+-------+
| Zhangsan | 40 |
+--------------+-------+
| Mary | 22 |
+--------------+-------+
| John | 30 |
+--------------+-------+
SKIP
SKIP 表示从哪一行开始返回结果,使用 SKIP 可以跳过查询结果的开始部分。如果查询没有指定 ORDER BY 语句,则查询结果的顺序是不确定的。SKIP 子句中可以使用 u32 类型的整数作为参数。
-
跳过前几行数据
示例
在当前图中,查询“person”点类型中的所有点,并从第四个查询结果开始的返回结果,命令如下:MATCH (n:person)
RETURN n.name
ORDER BY n.name
SKIP 3;返回结果示例如下:
+--------------+
| n.name |
+==============+
| Zhangwu |
+--------------+ -
返回中间行数据
跳过第一条数据,返回之后的数据。
示例
在当前图中,查询“person”点类型中的所有点,并跳过第一行数据,返回之后的两行数据,命令如下:MATCH (n:person)
RETURN n.name
ORDER BY n.name
SKIP 1 limit 2;返回结果示例如下:
+--------------+
| n.name |
+==============+
| Mary |
+--------------+
| Zhangsan |
+--------------+
LIMIT
LIMIT 子句用于限制输出的行数,主要用于从顶部开始返回部分結果。LIMIT 子句中可以使用 u32 类型的整数作为参数。
示例
在当前图中,查询“person”点类型中的所有点,并返回前三行数据,命令如下:
MATCH (n:person)
RETURN n
ORDER BY n.name
LIMIT 3;
返回结果示例如下:
+----------------------------------------------------------------------------------------------+
| n |
+==============================================================================================+
| vid: [_oid: 36990974643142658, label: person], properties: [36990974643142658, 3, Jerry, 22] |
+----------------------------------------------------------------------------------------------+
| vid: [_oid: 36990974638948352, label: person], properties: [36990974638948352, 1, John, 30] |
+----------------------------------------------------------------------------------------------+
| vid: [_oid: 36990974643142657, label: person], properties: [36990974643142657, 2, Mary, 25] |
+----------------------------------------------------------------------------------------------+
集合操作
UNION
UNION 子句用于将两个或多个查询的结果合并为一个结果集,该结果集中包含所有进行合并操作的行。使用 UNION 合并多个查询的结果时,确保结果集中列的数量和名称必须相同。
要保留所有结果行,请使用 UNION ALL。如果仅使用 UNION,将从结果集中删除重复项。
示例 1
使用 UNION All 子句合并两个查询结果并保留重复项,命令如下:
MATCH (n:person {name:'John'})
RETURN n.name
UNION All MATCH (n:person {name:'Zhangwu'})
RETURN n.name;
返回结果示例如下:
+-------------+
| n.name |
+=============+
| John |
+-------------+
| Zhangwu |
+-------------+
| Zhangwu |
+-------------+
示例 2
使用 UNION 子句合并两个查询并删除重复项,命令如下:
MATCH (n:person {name:'John'})
RETURN n.name
UNION MATCH (n:person {name:'Zhangwu'})
RETURN n.name;
返回结果示例如下:
+-------------+
| n.name |
+=============+
| John |
+-------------+
| Zhangwu |
+-------------+
INTERSECT
INTERSECT 子句按照从左到右的顺序计算两个或多个查询结果的交集,并返回各查询子句中共同的结果。在使用 INTERSECT 时,请确保各查询子句返回的列的数量和名称必须相同。
示例
使用 INTERSECT 子句对多个查询结果计算交集,并返回没有重复项的交集结果,命令如下:
MATCH (m: person {id: 1}) - [r:like] -> (n: person) RETURN n.id
INTERSECT
MATCH (m: person {id: 2}) - [r:like] -> (n: person) RETURN n.id
INTERSECT
MATCH (m: person {id: 3}) - [r:like] -> (n: person) RETURN n.id;
返回结果示例如下:
+------+
| n.id |
+======+
| 4 |
+------+
EXCEPT
EXCEPT 子句按照从左到右的顺序计算两个或多个查询结果的差集(即 A - B,返回只属于 A 集合且不属于 B 集合的结果)。在使用 EXCEPT 子句时,请确保各查询子句返回的列的数量和名称必须相同。
示例
使用 EXCEPT 子句对多个查询结果计算差集,并返回没有重复项的差集的结果,命令如下:
MATCH (m: person {id: 1}) - [r:like] -> (n: person) RETURN n.id
EXCEPT
MATCH (m: person {id: 2}) - [r:like] -> (n: person) RETURN n.id
EXCEPT
MATCH (m: person {id: 3}) - [r:like] -> (n: person) RETURN n.id;
返回结果示例如下:
+------+
| n.id |
+======+
| 2 |
+------+
UNWIND
UNWIND 用于将数组类型的值展开成单独的行。如果输入表达式不是数组类型,则不会进行展开操作,直接返回原值。
示例 1
将 [1,2,3] 列表中的每个元素转换成单独的行并返回每个元素。命令如下:
UNWIND [1,2,3] AS a
RETURN a;
返回结果示例如下:
+---+
| a |
+===+
| 1 |
+---+
| 2 |
+---+
| 3 |
+---+
示�例 2
查询与 id 为“1”、姓名为“Jhon”的人有关联关系的所有人,聚合去重后的关联人名字并计数。如果名字数量与关联人数一致,则返回“Jhon”的 id 和关联人去重后的名字。命令如下:
MATCH (a:person{id:1, name:'John'})-[f]->(b:person)
WITH a.id AS a_id, collect(DISTINCT b.name) AS b_names, count(b.name) AS cnt
WHERE size(b_names)=cnt
UNWIND b_names AS b_name
RETURN a_id, b_name;
返回结果示例如下:
+------+--------+
| a_id | b_name |
+======+========+
| 1 | Jerry1 |
+------+--------+
| 1 | Mary1 |
+------+--------+
表达式
在图数据库中,表达式通常是基于常量、变量、操作符运算和函数运算进行调用和组合的。
语法
<expression> ::= <variable>
| <const_value>
| <property>
| <arith_expression>
| <in_expression>
| <unary_expression>
| <compare_expression>
| <logical_expression>
| <string_operator>
| <function_call>
| <aggregate_function>
| <is_null>
<property> ::= <variable> . <property_name> ;
<arith_expression> ::= <expression> { + | - | * | / | % | ^ } <expression> ;
<in_expression> ::= <expression> IN '[' <expression> [, <expression> ]... ']';
<unary_expression> ::= { + | - | NOT } <expression>
<compare_expression> ::= <expression> { = | <> | < | > | >= | <= } <expression>
<logical_expression> ::= <expression> { AND | OR | XOR } <expression>
<string_operator> ::= <expression> {STARTS WITH | ENDS WITH | CONTAINS} <pattern>
<function_call> ::= <function_name>([<expression> [',' <expression>]...])
<aggregate_function> ::= COUNT(*)
| { COUNT | MIN | MAX | SUM | AVG | COLLECT } ([DISTCINT] <expression> )
<is_null> ::= <expression> IS [NOT] NULL
详细说明
| 参数 | 说明 |
|---|---|
<expression> | 表示一个表达式,可以由多种其他类型的表达式组成。 |
<variable> | 表示语句中点、边、路径的名字或者别名。 |
<const_value> | 表示常量值,支持多种数据类型,如字符串、整数、浮点数等。 |
<property> | 表示属性,由 <variable> 和 <property_name> 组成。- <variable>: 表示语句中点、边、路径的名字或者别名。 - <property_name>:表示点和边的属性名。 |
<arith_expression> | 算术计算表达式,表示两个表达式间进行算术运算,支持加(+)、减(-)、乘(*)、除(/)、取模(%)、幂(^)等算术运算。 |
<in_expression> | 判断表达式,判断左侧表达式是否存在于右侧表达式列表中,若存在则返回 true,否�则返回 false。 |
<unary_expression> | 一元运算表达式,由一个操作符和一个表达式组成。该表达式支持以下操作符。 - +:用于取正操作,对表达式的值取正值。- -:用于取反操作,对表达式的值取相反值。- NOT:用于逻辑非运算,对表达式的值执行逻辑非操作。 |
<compare_expression> | 比较表达式, 用于比较两个表达式的值,支持等于(=),不等于(<>), 小于(<),大于(>),大于等于(>=),小于等于(<=)等比较运算。 |
<logical_expression> | 逻辑表达式,用于两个表达式之间做逻辑运算,该表达式支持以下逻辑运算符。 - 逻辑与( AND):当两个表达式都为真时,结果为真。- 逻辑或( OR):当两个表达式中至少有一个为真时,结果为真。- 逻辑异或( XOR):当两个表达式取值不同时,结果为真。 |
<string_operator> | 字符串匹配表达式,用于对字符串与表达式间进行匹配和比较计算,并返回布尔类型的结果。由表达式、字符串操作符和子字符串值(pattern)组成。该表达式支持以下字符串操作符。 - STARTS WITH:判断左侧表达式是否以指定的右侧子字符串值(pattern)开始。 - ENDS WITH:判断左侧表达式是否以指定的右侧子字符串值(pattern)结束。- CONTAINS:判断左侧表达式是否包含右侧子字符串值(pattern)。 |
<function_call> | 函数调用表达式,用于调用一个函数并传递参数。该表达式由函数名和参数列表组成。 - <function_name>:表示要调用的函数的名称。- <expression>:表示函数的参数,可以有零个或多个参数。参数之间使用逗号“,”分隔。 |
<aggregate_function> | 聚合函数,用于对一组值进行计算并返回结果。由聚合函数和函数参数组成,当函数参数前如果有 DISTINCT,表示对重复的值只做一次聚合运算。该表达式支持以下聚合函数:- COUNT(*):表示对所有的列进行计数。- COUNT:表示对指定的列进行计数。- MIN:返回指定列的最小值。- MAX:返回指定列的最大值。- SUM:返回指定列的值的总和。- AVG:返回指定列的值的平均值。 |
<is_null> | 条件表达式,用于检查指定表达式的值是否为 NULL。- IS NULL:如果表达式的值是 NULL,则返回 true,否则返回 false。- IS NOT NULL:如果表达式的值不是 NULL,则返回 true,否则返回 false。 |
常量
常量,表示固定的数值或文本,如数字、字符串等。
- 十进制(整型或浮点型)的��字面值,例如:
13,-40000,3.14,6.022E23。 - 字符串字面值,例如:
'Hello',"World"。 - 布尔字面值,例如:
true,false,TRUE,FALSE。
示例
MATCH (n:person)
RETURN 1, true, "hello";
变量
在图数据库中,变量是一种用于指代图数据库中点、边及其属性值的标识符。可以通过变量来引用和操作数据库中的数据。
例如:n,x,rel,myFancyVariable。
MATCH (n:person)
RETURN n;
属性
属性是对象的一部分,用于描述对象的特性。属性表达式是对图中的点和边属性进行操作和计算的表达式。属性表达式可以用来筛选和变换图中的数据。
例如:n.prop,x.prop,rel.thisProperty。
MATCH (n:person)
RETURN n.id;
函数调用
例如:id(n),type(n)。详情请参见 Graph 函数 章节。
MATCH (n:person)
RETURN id(n), type(n);
聚合函数
例如:avg(x.prop),count(*)。详情请参见 聚合函数 章节。
MATCH (m: person {name:"Mahinda"}) - [e:like] -> (n:person)
RETURN avg(n.id);
计算表达式
在 ArcGraph 图数据库中,支持使用多种计算表达式来对数据进行操作,包括基本的数学运算、字符串运算和时间日期运算等。
基本数学运算
+:加法。-:减法。*:乘法。/:除法。%:取模。-:取反。
示例
MATCH (m:person {name:'Manuel' })-[e:like]->(n:person)
RETURN n.id, n.id % 100, n.id % 100 + 10, n.id % 100 - 10, n.id % 100 * 2, n.id % 100 / 2;
MATCH (m: person {name:"Mahinda"})
RETURN -m.id;
字符串运算
ArcGraph 图数据库支持对字符串类型的字段进行连接、搜索、匹配运算。请注意,进行字符串运算时需要区分大小写。
加法运算
支持使用加法(+)运算符连接两个或两个以上字符串。请注意,进行字符串运算时需要区分大小写。
示例
RETURN "Hello" + "World";
返回结果示例如下:
+-------------------+
| "Hello" + "World" |
+===================+
| HelloWorld |
+-------------------+
STARTS WITH
支持使用 STARTS WITH 运算符来匹配字符串是否以某个指定的值作为前缀开始。
示例
RETURN 'Hello' STARTS WITH 'H','Hello' STARTS WITH 'h','Hello' STARTS WITH 'Hel';
返回结果示例如下:
+-------------------------+-------------------------+---------------------------+
| "Hello" starts with "H" | "Hello" starts with "h" | "Hello" starts with "Hel" |
+=========================+=========================+===========================+
| true | false | true |
+-------------------------+-------------------------+---------------------------+
ENDS WITH
支持使用 ENDS WITH 运算符来匹配字符串是否以某个指定的值作为后缀结尾。
示例
RETURN 'Hello' ENDS WITH 'o','Hello' ENDS WITH 'O','Hello' ENDS WITH 'lo','Hello' ENDS WITH 'l';
返回结果示例如下:
+-----------------------+-----------------------+------------------------+-----------------------+
| "Hello" ends with "o" | "Hello" ends with "O" | "Hello" ends with "lo" | "Hello" ends with "l" |
+=======================+=======================+========================+=======================+
| true | false | true | false |
+-----------------------+-----------------------+------------------------+-----------------------+
CONTAINS
支持使用 CONTAINS 运算符来搜索字符串中是否包含某个指定的值。
示例
RETURN 'Hello' CONTAINS 'o','Hello' CONTAINS 'O','Hello' CONTAINS 'lo';
返回结果示例如下:
+----------------------+----------------------+-----------------------+
| "Hello" contains "o" | "Hello" contains "O" | "Hello" contains "lo" |
+======================+======================+=======================+
| true | false | true |
+----------------------+----------------------+-----------------------+
IN
支持使用 IN 运算符来检查列表中是否包含某个指定的值。
IN 运算符左右两侧只能为同种数据类型,右边的列表也只能为同种数据类型的常量。
示例
RETURN 1 IN [1,2,3],'Hello' IN ['Hello','World'],'A' IN ['Hello','World'];
返回结果示例如下:
+----------------------------------------------------------------------------------------------+-------------------------------------------------------------------------------------+---------------------------------------------------------------------------------+
| 1 IN [ConstExpr { val: Int64(1) }, ConstExpr { val: Int64(2) }, ConstExpr { val: Int64(3) }] | "Hello" IN [ConstExpr { val: String("Hello") }, ConstExpr { val: String("World") }] | "A" IN [ConstExpr { val: String("Hello") }, ConstExpr { val: String("World") }] |
+==============================================================================================+=====================================================================================+=================================================================================+
| true | true | false |
+----------------------------------------------------------------------------------------------+-------------------------------------------------------------------------------------+---------------------------------------------------------------------------------+
时间日期运算
ArcGraph 图数据库支持对时间日期类型的字段进行加减法操作,其中需要使用类型为 Int64 的数值来表示毫秒数,且减法运算时,Int64 只能作为减数,不允许作为被减数。
加法运算
示例
为点数据的日期字段增加一天,其中,24 * 3600 * 1000 表示一天的毫秒数。命令如下:
MATCH (n:date_test)
RETURN n.dd + 24 * 3600 * 1000;
返回结果示例如下:
+-------------------------+
| n.dd + 24 * 3600 * 1000 |
+=========================+
| 1989-05-21 |
+-------------------------+
减法运算
示例
为点数据的日期字段减少一天,其中,24 * 3600 * 1000 表示一天的毫秒数。命令如下:
MATCH (n:date_test)
RETURN n.dd - 24 * 3600 * 1000;
返回结果示例如下:
+-------------------------+
| n.dd - 24 * 3600 * 1000 |
+=========================+
| 1989-05-19 |
+-------------------------+
谓词表达式
详情请参见 WHERE 章节。
内置函数
ArcGraph 图数据库提供了丰富的内置函数,这些函数简化了图数据查询、处理和转换的复杂性。本章节将详细介绍 ArcGraph 图数据库支持的内置函数及其用法。
字符串函数
字符串函数用于对字符串进行各种操作。
在数据库中,null 表示一个属性其存储的值是空值。
left()
left() 函数将原始字符串从左侧起返回指定长度的子字符串。
语法
left(original, length)
参数说明
| 参数 | 说明 |
|---|---|
original | 返回字符串的表达式。 |
length | 返回正整数的表达式。 |
说明:
left(null, length)和left(null, null)会返回null,left(original, null)会产生错误。- 若
length为“0”,则将返回空字符串,若length为负值会产生错误。 - 若
length超过original的长度大小,则返回original。
示例
MATCH (n:person {id:1,name:'John'})
RETURN left('John', 3);
right()
right() 函数将原始字符串从右侧起返回指定长��度的子字符串。
语法
right(original, length)
参数说明
| 参数 | 说明 |
|---|---|
original | 返回字符串的表达式。 |
length | 返回正整数的表达式。 |
说明:
right(null, length)和right(null, null)会返回null,right(original, null)会产生错误。- 若
length为“0”,则将返回空字符串,若length为负值会产生错误。 - 若
length超过original的长度大小,则返回original。
示例
MATCH (n:person{id:1, name:'John'})
RETURN right('John', 3);
substring()
substring() 函数根据基于 0 起始索引的原则,返回原始字符串中指定长度的子字符串。
语法
substring(original, start [, length])
参数说明
| 参数 | 说明 |
|---|---|
original | 该表达式返回一个字符串,作为原始字符串。 |
start | 该表达式返回一个正整数,表示子字符串开始的位置。start 是基于从 0 开始的索引。 |
length | (可选)该表达式返回一个正整数,表示子字符串结束的位置。若省略 length,则函数将返回从 start 位置开始到原始字符串末尾的所有字符。 |
说明:
- 如果
original为null时,则返回结果为null。 - 如果
start为“0”,则从original的首位开始返回字符串。 - 如果
start位置超出字符串的长度返回空字符串。 - 如果
length为“0”,则将返回空字符串,如果length为负值会产生错误。 - 如果
start+length的值超出字符串的长度,则只返回起始位置start开始的字符串,而忽略超出长度范围的字符。 - 如果
start或length为负整数或null,则会产生错误。
示例 1
MATCH (n:person{id:1, name:'John'})
RETURN substring('John', 1, 3);
示例 2
MATCH (n:person{id:1, name:'John'})
RETURN substring('John', 1);
lTrim()
lTrim() 函数返回删除了左侧空格的字符串。
语法
lTrim(original)
参数说明
| 参数 | 说明 |
|---|---|
original | 返回字符串的表达式。lTrim(null) 将返回 null。 |
示例
MATCH (n:person {id:1,name:'John'})
RETURN lTrim(' John');
rTrim()
rTrim() 函数返回删除了右侧空格的字符串。
语法
rTrim(original)
参数说明
| 参数 | 说明 |
|---|---|
original | 返回字符串的表达式。rTrim(null) 将返回 null。 |
示例
MATCH (n:person{id:1, name:'John'})
RETURN rTrim('John ');
trim()
trim() 函数返回删除了左右侧空格的字符串。
语法
trim(original)
参数说明
| 参数 | 说明 |
|---|---|
original | 返回字符串的表达式。trim(null) 则返回 null。 |
示例
MATCH (n:person{id:1, name:'John'})
RETURN trim(' John ');
replace()
replace() 函数用于替换字符串中的子字符串,并返回替换后的新字符串。
语法
replace(original, search, replace)
参数说明
| 参数 | 说明 |
|---|---|
original | 返回字符串的表达式。 |
search | 该表达式指定要被替换的字符串。 |
replace | 替换指定字符串的表达式。 |
说明:
- 如果任何参数为
null,null将返回。 - 如果在
original中找不到search,将返回original。
示例
MATCH (n:person{id:1, name:'John'})
RETURN replace("John", "J", "H");
reverse()
reverse() 函数将返回转置后的字符串。
语法
reverse(original)
参数说明
| 参数 | 说明 |
|---|---|
original | 返回字符串的��表达式。reverse(null) 将返回 null。 |
示例
MATCH (n:person{id:1, name:'John'})
RETURN reverse('John') ;
toLower()
toLower() 函数将以小写形式返回指定字符串。
语法
toLower(original)
参数说明
| 参数 | 说明 |
|---|---|
original | 返回字符串的表达式。 toLower(null) 返回 null 。 |
示例
MATCH (n:person{id:1, name:'John'})
RETURN toLower('John');
toUpper()
toUpper() 函数将以大写形式返回指定字符串。
语法
toUpper(original)
参数说明
| 参数 | 说明 |
|---|---|
original | 返回字符串的表达式。toUpper(null) 则返回 null。 |
示例
MATCH (n:person{id:1, name:'John'})
RETURN toUpper('John');
toString()
toString() 函数将整数,浮点数或布尔值转换为字符串。
语法
toString(expression)
参数说明
| 参数 | 说明 |
|---|---|
expression | 返回数字、布尔值或字符串的表达式。 - toString(null) 则返回 null。- 若 expression 为字符串,则不执行操作,原样返回。 |
示例
MATCH (n:person{id:1, name:'John'})
RETURN toString(11.5),toString('already a string'),toString(true);
concat()
concat() 函数用于将两个或两个以上字符串连接成一个字符串。
语法
concat(<string1>,<string2>,...)
参数说明
| 参数 | 说明 |
|---|---|
<string1>,<string2>,... | 返回字符串的表达式。 说明: - 函数需要至少两个字符串参数,如果只有一个参数,则会报错。 - 如果任何一个字符串参数为 NULL,则 concat() 函数返回�值为 NULL。 |
返回值
返回值为一个字符串。
示例
RETURN concat("Hello", "World");
concat_ws()
concat_ws() 函数用于将两个或两个以上字符串使用指定的分隔符连接成一个字符串。
语法
concat_ws(<separator>,<string1>,<string2>,... )
参数说明
| 参数 | 说明 |
|---|---|
<separator> | 返回字符串分隔符的表达式,用于连接字符串。 说明: 如果分隔符为 NULL,则 concat_ws() 函数返回 NULL。 |
<string1>,<string2>,... | 返回字符串的表达式。 说明: - 函数需要至少两个字符串参数,如果只有一个字符串参数,则会报错。 - 如果字符串参数中存在 NULL 值,则 concat_ws() 函数将自动忽略该值,继续连接下一个参数。 |
返回值
返回值为一个字符串。
示例
RETURN concat_ws(" ","Hello","World");
数学函数
数值
abs()
abs() 返回指定数值的绝对值。
语法
abs(expression)
参数说明
| 参数 | 说明 |
|---|---|
expression | 返回数值的表达式。abs(null) 返回 null。 |
返回值
返回值决于 expression 返回值的类型。
示例
MATCH (m:person)-[e:like]->(n:person)
RETURN m.age, n.age, abs(m.age - n.age);
ceil()
ceil() 函数用于返回大于或等于指定数值的最小整数的浮点数。
语法
ceil(expression)
参数说明
| 参数 | 说明 |
|---|---|
expression | 返回数值的表达式。ceil(null) 返回 null。 |
返回值
返回值决于 expression 返回值的类型。
示例
MATCH (n:person{id:1, name:'John'})
RETURN ceil(0.1);
floor()
floor() 函数用于返回小于或等于指定数值的最大整数的浮点数。
语法
floor(expression)
参数说明
| 参数 | 说明 |
|---|---|
expression | 返回数值�的表达式。floor(null) 返回 null。 |
返回值
返回值决于 expression 返回值的类型。
示例
MATCH (n:person{id:1, name:'John'})
RETURN floor(0.9);
rand()
rand() 函数将返回[0,1)范围内的随机浮点数且数值遵循近似均匀分布。
语法
rand()
返回值
返回值为浮点数。
示例
MATCH (n:person{id:1, name:'John'})
RETURN rand();
round()
round() 函数返回指定数值经过四舍五入处理后最接近的整数。
语法
round(expression)
参数说明
| 参数 | 说明 |
|---|---|
expression | 返回数值的表达式。round(null) 返回 null。 |
返回值
返回值决于 expression 返回值的类型。
示例
MATCH (n:person{id:1, name:'John'})
RETURN round(3.141592);
sign()
sign() 函数用于返回指定数值的符号,即如果该数值为正数,则返回 1,负数返回 -1,“0”返回 0。
语法
sign(expression)
参数说明
| 参数 | 说明 |
|---|---|
expression | 返回数值的表达式。sign(null) 返回 null。 |
返回值
返回值为 INT32。
示例
MATCH (n:person{id:1, name:'John'})
RETURN sign(-17),sign(0.1);
三角函数
cos()
cos() 余弦函数,返回指定角度(以弧度为单位)的余弦值。
语法
cos(expression)
参数说明
| 参数 | 说明 |
|---|---|
expression | 任意浮点数。 |
返回值
返回值类型为浮点数。
示例
MATCH (n:person{id:1, name:'John'})
RETURN cos(30000.14159);
acos()
acos() 反余弦函数,返回指定数值的反余弦值。
语法
acos(expression)
参数说明
| 参数 | 说明 |
|---|---|
expression | expression 取值范围为:[-1, 1]。当 expression 参数设置不在合理区间时,则返回结果为 null。 |
返回值
返回值类型为浮点数。
示例
MATCH (n:person{id:1, name:'John'})
RETURN acos(0);
sin()
sin() 正弦函数,它返回指定角度(以弧度为单位)的正弦值。
语法
sin(expression)
参数说明
| 参数 | 说明 |
|---|---|
expression | 以弧度表示角度的数值表达式。sin(null) 返回 null。 |
返回值
返回值为浮点数。
示例
MATCH (n:person{id:1, name:'John'})
RETURN sin(0.5);
asin()
asin() 反正弦函数返回指定数值的反正弦值。
语法
asin(expression)
参数说明
| 参数 | 说明 |
|---|---|
expression | expression 取值范围为:[-1, 1]。当 expression 参数设置不在合理区间时,则返回结果为 null。 |
返回值
返回值类型为浮点数。
示例
MATCH (n:person{id:1, name:'John'})
RETURN asin(1);
tan()
tan() 正切函数,它返回指定角度(以弧度为单位)的正切值。需要注意的是,tan() 函数在角度为 90 度时返回的是无穷大,因为此时正切不存在。
语法
tan(expression)
参数说明
| 参数 | 说明 |
|---|---|
expression | 以弧度表示角度的数值表达式。 - tan(null) 返回 null。- 如果计算发生 overflow,则会显示 throw OverflowError 错误。 |
返回值
返回值为浮点数。
示例
MATCH (n:person{id:1, name:'John'})
RETURN tan(0.5);
atan()
atan() 反正切函数,返回指定数值的反正切值。与 atan2() 函数不同,atan() 函数只接受一个数值作为参数,而 atan2() 函数接受两个数值作为参数。
语法
atan(expression)
参数说明
| 参数 | 说明 |
|---|---|
expression | 任意浮点数。 |
返回值
返回值类型为浮点数。
示例
MATCH (n:person{id:1, name:'John'})
RETURN atan(99);
atan2()
atan2() 反正切函数,返回指定的两个数值的比值的反正切值。
语法
atan2(y, x)
参数说明
| 参数 | 说明 |
|---|---|
x | 任意浮点数。 |
y | 任意浮点数。 |
返回值
返回值类型为浮点数。
示例
MATCH (n:person{id:1, name:'John'})
RETURN atan2(1, 1);
cot()
cot() 三角余切函数,它返回指定角度(以弧度为单位)的三角余切值。需要注意的是,cot() 函数在角度为 90 度时返回的是无穷大,因为此时三角余切不存在。
语法
cot(expression)
参数说明
| 参数 | 说明 |
|---|---|
expression | 任意浮点数。 |
返回值
返回值类型为浮点数。
示例
MATCH (n:person{id:1, name:'John'})
RETURN cot(3.1415926/4);
degrees()
degrees() 角度转换函数,它将弧度转换为度。
语法
degrees(expression)
参数说明
| 参数 | 说明 |
|---|---|
expression | 以弧度表示角度的数值表达式。 - degrees(null) 返回 null。- 如果计算发生 overflow,则会显示 throw OverflowError 错误。 |
返回值
返回值类型为浮点数。
示例
MATCH (n:person{id:1, name:'John'})
RETURN degrees(3.14159);
radians()
radians() 弧度转换函数,它将度数转换为弧度。
语法
radians(expression)
参数说明
| 参数 | 说明 |
|---|---|
expression | 数值表达式,以度为单位表示角度。radians(null) 返回 null。 |
返回值
返回值为浮点数。
示例
MATCH (n:person{id:1, name:'John'})
RETURN radians(180);
haversin()
haversin() 半正矢函数,它返回指定角度(以弧度为单位)的正弦值的一半的平方。
语法
haversin(expression)
参数说明
| 参数 | 说明 |
|---|---|
expression | 以弧度表示角度的数值表达式。haversin(null) 返回 null。 |
返回值
返回值为浮点数。
示例
MATCH (n:person{id:1, name:'John'})
RETURN haversin(0.5);
pi()
pi() 返回数学常数 pi。
语法
pi()
返回值
返回值为浮点数。
示例
MATCH (n:person{id:1, name:'John'})
RETURN pi();
日期时间函数
本章节主要介绍 ArcGraph 支持的日期时间函数。
日��期时间格式符
日期格式化中的一些常用格式符如下:
-
日期格式化
格式说明符 含义 示例 %Y四位数的年份 2022 %C年份除以 100 的结果,用两位数表示 20 %y年份模 100 的结果,用两位数表示 01 %m月份,用两位数表示(范围为 01~12) 01 %b月份的缩写形式 Jul %B月份的完整名称 July %h与 %b相同Jul %d日期,用两位数表示(范围为 01~31) 01 %e日期,不带前导零(范围为 1~31) 1 %a星期几的缩写形式 Sun %A星期几的完整名称 Sunday %w星期几的数字表示(范围为 0~6,其中 0 表示星期日) 6 %u星期几的数字表示(范围为 1~7,其中 1 表示星期一) 7 %U以星期日为起始的周数(范围为 00~53),用两位数表示 53 %W以星期一为起始的周数(范围为 00~53),用两位数表示 53 %G与 %Y相同,但使用 ISO 8601 周日期中的年份2022 %g与 %y相同,但使用 ISO 8601 周日期中的年份01 %V与 %U相同,但使用 ISO 8601 周日期中的周数(范围为 01~53)53 %j一年中的第几天,用三位数表示(范围为 001~366) 001 %D月份/日期/年份格式 07/08/01 %x本地日期表示形式 12/31/99 %F年份-月份-日期格式(ISO 8601) 2001-07-08 %v日期-月份-年份格式 8-Jul-2001 -
时间格式化
格式说明符 含义 示例 %H小时,用两位数表示(范围为 00~23) 23 %k与 %H相同,但用空格填充23 %I12 小时制小时,用两位数表示(范围为 01~12) 12 %l与 %I相同,但用空格填充12 %P12 小时制的 am 或 pm am %p12 小时制的 AM 或 PM AM %M分钟,用两位数表示(范围为 00-59) 59 %S秒,用两位数表示(范围为 00~59) 00 %f自上一整秒以来的纳秒级别的小数秒(范围为 000000~999999) 999999 %.f与 %f类似,但左对齐000.000000 %.3f与 %.f类似,但长度固定为 3000.000 %.6f与 %.f类似,但长度固定为 6000.000000 %.9f与 %.f类似,但长度固定为 9000.000001234 %3f与 %.3f类似,但不包含前导点3f %6f与 %.6f类似,但不包含前导点6f %9f与 %.9f类似,但不包含前导点9f %R小时-分钟格式 00:34 %T小时-分钟-秒格式 00:34:60 %X本地时间表示形式 23:13:48 %r12 小时制的小时-分钟-秒格式 12:34:60 AM -
时区格式化
格式说明符 含义 示例 %Z本地时区名称 Asia/Shanghai %z本地时间与 UTC 的偏移量 +0930 %:z与 %z相同,但带有冒号+09:30 %::z与 %z相同,但带有秒+09:30:00 %:::z与 %z相同,但不带分钟+0900 %#z与 %z相同,但允许省略或包含+0930 or +09 or -01 or -0130
timestamp()
timestamp() 函数用于获取当前的时间戳,即 timestamp() 函数将返回从 UTC 1970 年 1 月 1 日午夜开始到现在并以毫秒为单位进行计算的时间差。
语法
timestamp()
返回值
返回值为整数。
示例
MATCH (n:date_test)
RETURN timestamp();
date()
date() 函数返回一个表示当前日期的 Date 值,该日期默认使用本地时区。
语法
date()
返回值
返回值为日期。
示例
MATCH (n:date_test)
RETURN date();
datetime()
datetime() 函数将返回默认时区当前日期和时间的 DateTime 值。它既支持无参数调用,也支持带参数调用,并按照指定格式输出日期时间,常用格式符请参见 日期时间格式符 章节。
语法
datetime([<expression>])
参数说明
| 参数 | 说明 |
|---|---|
<expression> | (可选)返回字符串的表达式。 |
返回值
返回值为日期时间。
示例 1
MATCH (n:date_test)
RETURN datetime();
示例 2
RETURN datetime("2018-01-01 12:00:00");
localdatetime()
localdatetime() 函数返回一个表示当前本地日期和时间的 DateTime 值,默认使用本地时区。
语法
localdatetime()
返回值
返回值为 LocalDateTime。
示例
MATCH (n:date_test)
RETURN localdatetime();
localtime()
localtime() 函数返回当前的 LocalTime 值,默认使用本地时区。
语法
localtime()
返回值
返回值为 LocalTime。
示例
MATCH (n:date_test)
RETURN localtime();
time()
time() 函数返回当前 Time 值,将使用默认时区。
语法
time()
返回值
返回值为 Time。
示例
MATCH (n:date_test)
RETURN time();
dateFormat()
dateFormat() 函数是用于将日期时间按照指定的格式进行输出的函数,常用格式符请参见 日期时间格式符 章节。
语法
dateFormat(date,format)
参数说明
| 参数 | 说明 |
|---|---|
date | 要格式化的有效日期值,其类型可以是 date、time、timestamp 或 datetime。 |
format | 由预定义的说明符组成的格式字符串,每个说明符前面都有一个百分比字符(%)。 当 format 字符串格式有问题时,则无法解析会产生错误。 |
示例
MATCH (n:date_test)
RETURN dateFormat(n.ts, "%F %r");
year()
year() 函数将返回日期中的年份值。
语法
year(<expression>)
参数说明
| 参数 | 说明 |
|---|---|
<expression> | 返回年份的表达式。表达式的结果必须为 Date, Datetime, Timestamp 中的一种。 |
返回值
返回值为 INT64。
示例
RETURN year(DATE()), year(DATETIME()), year(TIMESTAMP());
month()
month() 函数将返回日期中的月份值。
语法
month(<expression>)
参数说明
| 参数 | 说明 |
|---|---|
<expression> | 返回月份的表达式。表达式的结果必须为 Date, Datetime, Timestamp 中的一种。 |
返回值
返回值为 INT64。
示例
RETURN month(DATE()), month(DATETIME()), month(TIMESTAMP());
day()
day() 函数将返回日期中的日期值。
语法
day(<expression>)
参数说明
| 参数 | 说明 |
|---|---|
<expression> | 返回日期的表达式。表达式的结果必须为 Date, Datetime, Timestamp 中的一种。 |
返回值
返回值为 INT64。
示例
RETURN day(DATE()), month(DATETIME()), month(TIMESTAMP());
工具函数
randomUUID()
randomUUID() 函数返回一个 UUID(Universally Unique Identifier,通用唯一识别码)。
语法
randomUUID()
返回值
返回值为字符串。
示例
MATCH (n:person{id:1, name:'John'})
RETURN randomUUID();
聚合函数
聚合函数用于对一组值进行计算,并返回单个值作为结果。如果要对聚合函数的结果进行排序,那么 RETURN 语句中必须包含相应的聚合表达式,供 ORDER BY 子句使用。当聚合函数与 DISTINCT 结合使用时,聚合函数将在计算前对数据进行去重处理。
avg()
avg() 函数用于计算一组数值的平均值。
语法
avg([distinct] expression)
参数说明
| 参数 | 说明 |
|---|---|
[distinct] | (可选)distinct 表示会对返回结果进行去重处理。 |
expression | 该表达式返回数值。 |
返回值
返回值取决于 expression 返回的具体值。
示例 1
MATCH(m:person {id:1})-[e:like]->(n:person)
RETURN avg(distinct n.id);
示例 2
MATCH(m:person {id:1})-[e:like]->(n:person)
RETURN avg(n.id);
count()
count() 函数用于计算一组数值或行的数量。
count(*):返回所有行的数量。count(expr):返回非null表达式值的行数。
语法
count([distinct] expression)
参数说明
| 参数 | 说明 |
|---|---|
[distinct] | (可选)distinct 表示会对返回结果进行去重处理。 |
expression | 返回值的表达式。 |
示例 1
MATCH(m:person {id:1})-[e:like]->(n:person)
RETURN count(distinct n.age);
示例 2
MATCH(m:person {id:1})-[e:like]->(n:person)
RETURN count(n.age);
sum()
sum() 函数用于计算一组数值的和。
语法
sum([distinct] expression)
参数说明
| 参数 | 说明 |
|---|---|
[distinct] | (可选)distinct 表示会对返回结果进行去重处理。 |
expression | 返回数值的表达式。 |
返回值
返回值为整数或浮点数,取决于 expression 返回的值。
示例 1
MATCH(m:person {id:1})-[e:like]->(n:person)
RETURN sum(distinct n.id);
示例 2
MATCH(m:person {id:1})-[e:like]->(n:person)
RETURN sum(n.id);
max()
max() 函数用于返回一组数值中的最大值。
语法
max(expression)
参数说明
| 参数 | 说明 |
|---|---|
expression | 返回值的表达式。 |
返回值
返回值取决于 expression 返回的具体值。
示例
MATCH(m:person {id:1})-[e:like]->(n:person)
RETURN max(n.id);
min()
min() 函数用于返回一组数值中的最小值。
语法
min(expression)
参数说明
| 参数 | 说明 |
|---|---|
expression | 返回值的表达式。 |
返回值
返回值取决于 expression 返回的具体值。
示例
MATCH(m:person {id:1})-[e:like]->(n:person)
RETURN min(n.id);
collect()
collect() 函数用于将表达式的多个返回值聚合为一个列表。
语法
collect([distinct] expression)
参数说明
| 参数 | 说明 |
|---|---|
[distinct] | (可选)distinct 表示对返回结果进行去重处理。 |
expression | 返回值的表达式。当 collect(null) 时,返回空数组。 |
返回值
返回值为一个数组类型。
示例
MATCH(m:person {id:1})-[e:like]->(n:person)
RETURN collect(distinct n.id);
Graph 函数
id()
id() 函数返回点或边的 ID。
语法
id(expression)
参数说明
| 参数 | 说明 |
|---|---|
expression | 该表达式返回点或边。 |
返回值
返回值为整数。
示例
MATCH (n:person{id:1, name:'John'})
RETURN id(n);
pk()
pk(primary key,主键)是一个数据库表中的特殊列,其值唯一地标识表中的每一行或记录。主键的值必须是唯一的,并且不能为 NULL。在 ArcGraph 图数据库中,pk() 函数用于返回点、点 ID、点数组或点 ID 数组的主键值。
语法
pk(<node>|<node_id>|<array<node>>|<array<node_id>>)
参数说明
| 参数 | 说明 |
|---|---|
<node> | 表示一个点。 |
<node_id> | 表示一个点的 ID。 |
<array<node> | 表示一个包含多个点的数组。 |
<array<node_id>> | 表示一个包含多个点 ID 的数组。 |
返回值
- 若输入值为点或点 ID,则返回值为 String 类型。
- 若输入值为点或点 ID 数组,则返回值为 String 类型的数组。
说明:
暂不支持为不同的点类型设置不同的主键名称,即所有的点都需使用相同的主键字段来标识。
示例 1
查找单个点的主键值,命令如下:
MATCH (a:person{id:1, name:'John'})
RETURN pk(a);
示例 2
查找单个点 ID 的主键值,命令如下:
MATCH (a:person{id:1, name:'John'})
RETURN pk(id(a));
示例 3
查找点数组的主键值,命令如下:
MATCH p=(a:person{id:1, name:'John'})-[:like]->(b:person) WITH p
WITH [n in nodes(p) | n ] AS personInPath
RETURN pk(personInPath);
示例 4
查找点 ID 数组的主键值,命令如下:
MATCH p=(a:person{id:1, name:'John'})-[:like]->(b:person) WITH p
WITH [n in nodes(p) | id(n) ] AS personIdsInPath
RETURN pk(personIdsInPath);
type()
type() 函数返回点或边的类型。
语法
type(expression)
参数说明
| 参数 | 说明 |
|---|---|
expression | 该表达式返回点类型或边类型。 |
示例
MATCH (n:person{id:1, name:'John'})
RETURN type(n);
转换函数
toBoolean()
toBoolean() 函数将字符串、整数以及布尔值转换为一个布尔值。
- 字符串 "true"、非零整数值以及布尔值
true将被转换为布尔值true。 - 字符串 "false"、整数值“0”以及布尔值
false将被转换为布尔值false。
语法
toBoolean(expression)
参数说明
| 参数 | 说明 |
|---|---|
expression | 该表达式返回布尔值或字符串值。 |
返回值
返回值为布尔值。
示例
MATCH (n:person{id:1, name:'John'})
RETURN toBoolean('TRUE');
toFloat()
toFloat() 函数将字符串、整数以及布尔值转换为一个浮点值。如果无法转换为浮点值,将返回 null。
语法
toFloat(expression)
参数说明
| 参数 | 说明 |
|---|---|
expression | 该表达式返回字符串、整数或布尔值。 |
返回值
返回值为浮点值。
示例
MATCH (n:person{id:1, name:'John'})
RETURN toFloat('11.5');
toInteger()
toInteger() 函数将字符串、整数以及布尔值转换为一个整数值。如果无法转换为整数值,将返回 null。
语法
toInteger(expression)
参数说明
| 参数 | 说明 |
|---|---|
expression | 该表达式返回字符串、整数或布尔值。 |
返回值
返回值为整数值。
示例
MATCH(n:person{id:1, name:'John'})
RETURN toInteger('42.5');
toTimestamp()
toTimestamp() 函数将日期、时间、日期时间等表示时间的字符串转换为时间戳。
语法
toTimestamp(expression)
参数说明
| 参数 | 说明 |
|---|---|
expression | Date,DateTime,Time 等表示时间的字符串表达式。 |
返回值
返回值为时间戳。
示例
RETURN toTimestamp("1992-01-01");
对数函数
对数函数是一类与指数函数密切相关的数学函数,在数据库中用于各种计算和数学表达式。
e()
e() 函数返回自然常数 e,它是数学中的一个重要常数,约等于 2.71828。
语法
e()
返回值
返回值为浮点值,自然常数。
示例
MATCH (n:person{id:1, name:'John'})
RETURN e();
exp()
exp() 指数函数,当结果超出可表示的浮点数范围时,将返回字符串 inf。
语法
e(expression)
参数说明
| 参数 | 说明 |
|---|---|
expression | 返回数值的表达式。 |
返回值
返回值为浮点值。
示例
MATCH (n:person{id:1, name:'John'})
RETURN exp(2);
log()
log() 函数返回以自然常数为底的对数。
语法
log(expression)
参数说明
| 参数 | 说明 |
|---|---|
expression | 返回数值的表达式。 |
返回值
返��回值为浮点值。
示例
MATCH (n:person{id:1, name:'John'})
RETURN log(27);
log10()
log10() 函数返回数字以 10 为底的对数。
语法
log10(expression)
参数说明
| 参数 | 说明 |
|---|---|
expression | 返回数值的表达式。 |
返回值
返回值为浮点值。
示例
MATCH (n:person{id:1, name:'John'})
RETURN log10(27);
sqrt()
sqrt() 函数返回数值的平方根。
语法
sqrt(expression)
参数说明
| 参数 | 说明 |
|---|---|
expression | 返回数值的表达式。 |
返回值
返回值为浮点值。
示例
MATCH (n:person{id:1, name:'John'})
RETURN sqrt(256);
Partial 函数
Partial() 函数是一种用于数据脱敏的函数,ArcGraph 支持使用 Partial() 函数对点类型或边类型的属性进行部分脱敏来保护数据的隐私和安全。
语法
Partial(prefix, paddingString, suffix)
参数说明
| 参数 | 说明 |
|---|---|
prefix | 前缀参数,用于指定脱敏后的数据的前缀部分。 |
paddingString | 填充字符串参数,用于指定填充属性值的字符串。 |
suffix | 后缀参数,用于指定脱敏后的数据的后缀字符或字符串。 |
示例
CREATE VERTEX person(
primary key id int(64),
name string MASKED with (function=partial(2,"XXX",3))
);
路径函数
路径函数(Path Function)是一种在图数据库中用于查询和分析路径的函数,在图数据库中具有广泛的应用场景,例如,在社交网络中,可以使用路径函数计算两个用户之间的最短路径,以确定他们之间的社交关系距离;在物流领域中,可以查找两个城市之间的最短路径,以优化运输路线。本章节将介绍 ArcGraph 支持的路径函数。
startNode()
startNode() 函数将返回一条路径或者边的起点信息,包括点 ID 和点类型信息。其中,路径的起点是指路径上的第一个点;边的起点是指正向边的起点。
语法
startNode(<path | relationship>)
参数说明
| 参数 | 说明 |
|---|---|
<path|relationship> | 返回 path(路径)或者 relationship(边)的表达式。 |
返回值
返回点的信息。
说明:
startNode(null),则返回null。- 对于反向边,
startNode(relationship)返回正向起点,例如:a<-like-b, 则返回b的信息。 - 对于
startNode(path),始终返回第一个点的信息。
示例 1
查询正向边的起点信息,命令如下:
MATCH (n:person{id:1})-[e:like]->(m)
RETURN startNode(e);
返回结果示例如下:
+----------------------------------------+
| startnode(e) |
+========================================+
| _oid: 36990974638948352, label: person |
+----------------------------------------+
示例 2
查询反向边的起点信息,命令如下:
MATCH (n:person{id:1})<-[e:like]-(m)
RETURN startNode(e);
返回结果示例如下:
+----------------------------------------+
| startnode(e) |
+========================================+
| _oid: 36990974643142658, label: person |
+----------------------------------------+
示例 3
查询路径的起点信息,命令如下:
MATCH p=(n:person{id:1})-[e:like]->(m)
RETURN startNode(p);
返回结果示例如下:
+----------------------------------------+
| startnode(p) |
+========================================+
| _oid: 36990974638948352, label: person |
+----------------------------------------+
endNode()
endNode() 函数将返回一跳范围内路径或者边的终点信息,包括点 ID 和点类型信息。其中,路径的终点是指路径上的最后一个点;边的终点是指正向边的终点。
语法
endNode(<path | relationship>)
参数说明
| 参数 | 说明 |
|---|---|
<path|relationship> | 返回 path(路径)或者 relationship(边)的表达式。 |
返回值
返回点的信息。
说明:
endNode(null),则返回null。- 对于反向边,
endNode(relationship)返回正向终点,例如:a<-like-b, 则返回a的信息。 - 对于
endNode(path),始终返回最后一个点的信息。
示例 1
查询正向边的终点信息,命令如下:
MATCH (n:person{id:1})-[e:like]->(m)
RETURN endNode(e);
返回结果示例如下:
+----------------------------------------+
| endnode(e) |
+========================================+
| _oid: 36990974643142657, label: person |
+----------------------------------------+
示例 2
查询反向边的终点信息,命令如下:
MATCH (n:person{id:1})<-[e:like]-(m)
RETURN endNode(e);
返回结果示例如下:
+----------------------------------------+
| endnode(e) |
+========================================+
| _oid: 36990974638948352, label: person |
+----------------------------------------+
示例 3
查询路径的终点信息,命令如下:
MATCH p=(n:person{id:1})-[e:like]->(m)
RETURN endNode(p);
返回结果示例如下:
+----------------------------------------+
| endnode(p) |
+========================================+
| _oid: 36990974643142657, label: person |
+----------------------------------------+
nodes()
nodes() 函数将返回路径包含的所有点的信息列表,包括点 ID 和点类型信息。
语法
nodes(<path>)
参数说明
| 参数 | 说明 |
|---|---|
<path> | 返回 path(路径)的表达式。 |
返回值
返回点的信息列表。
说明:
nodes(null),则返回null。- 对于反向边,点在列表中顺序不做反转调整。
示例 1
查询路径中所有点的信息列表,命令如下:
MATCH p=(n:person{id:1})-[e:like]->(m)
RETURN nodes(p);
返回结果示例如下:
+----------------------------------------------------------------------------------+
| nodes(p) |
+==================================================================================+
| [_oid: 36333297816567808, label: person, _oid: 36333297820762113, label: person] |
+----------------------------------------------------------------------------------+
| [_oid: 36333297816567808, label: person, _oid: 36333297820762114, label: person] |
+----------------------------------------------------------------------------------+
示例 2
查询路径中所有点的信息列表,命令如下:
MATCH p=(n:person{id:1})<-[e:like]-(m)
RETURN nodes(p);
返回结果示例如下:
+----------------------------------------------------------------------------------+
| nodes(p) |
+==================================================================================+
| [_oid: 36333297816567808, label: person, _oid: 36333297820762114, label: person] |
+----------------------------------------------------------------------------------+
relationships()
relationships() 函数将返回路径包含的所有边列表。
语法
relationships(<path>)
参数说明
| 参数 | 说明 |
|---|---|
<path> | 返回 path(路径)的表达式。 |
返回值
返回边的信息列表。
说明:
relationships(null),则返回null。- 对于反向边,边在列表中顺序不做反转调整。
示例 1
查询路径中所有边的信息列表,命令如下:
MATCH p=(n:person{id:1})-[e:like]->(m)
RETURN relationships(p);
返回结果示例如下:
+----------------------------------------------------------------------------------------------------------------------+
| relationships(p) |
+======================================================================================================================+
| [src: [_oid: 36990974638948352, label: person], dest: [_oid: 36990974643142657, label: person], label: like, _ts: 0] |
+----------------------------------------------------------------------------------------------------------------------+
示例 2
查询路径中所有边的信息列表,命令如下:
MATCH p=(n:person{id:1})<-[e:like]-(m)
RETURN relationships(p);
返回结果示例如下:
+----------------------------------------------------------------------------------------------------------------------+
| relationships(p) |
+======================================================================================================================+
| [src: [_oid: 36990974643142658, label: person], dest: [_oid: 36990974638948352, label: person], label: like, _ts: 0] |
+----------------------------------------------------------------------------------------------------------------------+
length()
length() 函数将返回路径中边的个数。
语法
length(<path>)
参数说明
| 参数 | 说明 |
|---|---|
<path> | 返回 path(路径)的表达式。 |
返回值
返回路径中边的个数(即跳数),返回值类型为 Uint64。
说明:
length(null),则返回 0。
示例
查询路径中边的个数,命令如下:
MATCH p=(n:person{id:1})-[e:like]->(m)
RETURN length(p);
返回结果示例如下:
+-----------+
| length(p) |
+===========+
| 1 |
+-----------+
ShortestPath() 和 allShortestPaths()
ShortestPath() 和 allShortestPaths() 函数用于查找两点之间的最短路径。ShortestPath() 用于返回单个最短路径,当存在多条最短路径时,ShortestPath() 函数将随机选择一条最短路径返回,而 allShortestPaths() 函数则会返回所有最短路径,这在处理多个可能的路径或考虑路径不确定�性时非常有用。
语法
query_in_match_clause ::=
MATCH [<path_pattern>,]...
[<path_name> =] (SHORTESTPATH | ALLSHORTESTPATHS) (<shortest_path_pattern>)
query_in_wtih_clause ::=
WITH [<other_column>,]...
(SHORTESTPATH | ALLSHORTESTPATHS) (<shortest_path_pattern>) AS <path_name>
参数说明
| 参数 | 说明 |
|---|---|
<path_pattern> | (可选)定义路径模式的表达式,通常采用 (a)-[f]-(b) 的格式。 |
<path_name> | (可选)路径名称,表示为最短路径结果设置别名,以便在后续的查询中引用该路径。 |
<shortest_path_pattern> | 特定路径表达式,用于指定最短路径的模式。此模式中须包含非匿名的起始点和目标点,以及相关联的边。 |
<other_column> | 除最短路径之外的其他任意属性、表达式或常量等类型的字段。 |
返回值
返回两点间的单个最短路径或最短路径列表。
说明:
- 在使用
ShortestPath()和allShortestPaths()函数时,必须明确指定起始点和目标点,且这两点不能是同一个。 ShortestPath()和allShortestPaths()函数都有最大跳数限制。如果超过该限制仍未找到最短路径,将返回None。默认情况下最大跳数的设置范围为 1~8 的整数,若在调用函数时未明确指定最大跳数,则系统默认最大跳数为 8。根据实际情况,您可以通过SET SESSION或SET GLOBAL命令来调整compiler_max_var_hops参数以自定义最大跳数的取值范围,详情请参见 更改系统变量 章节。
示例 1
使用 query_in_match_clause 语法方式查询通过“like”边连接的 id 为“1”和“3”的“person”点之间,路径长度不超过 3 跳的单个最短路径。命令如下:
MATCH p=ShortestPath((m: person {id: 1})-[e:like*..3]-(n:person{id: 3}) )
RETURN p;
返回结果示例如下:
+---------------------------------------------------------------------------------------------------------------------------------+
| p |
+=================================================================================================================================+
| Path: [ |
| Vertex _oid: 36198255431778304, label: person |
| -> Edge src: [_oid: 36198255431778304, label: person], dest: [_oid: 36198255431778305, label: person], label: like, _ts: 0 |
| -> Vertex _oid: 36198255431778305, label: person |
| -> Edge src: [_oid: 36198255431778305, label: person], dest: [_oid: 36198255431778306, label: person], label: like, _ts: 0 |
| -> Vertex _oid: 36198255431778306, label: person |
| ] |
+---------------------------------------------------------------------------------------------------------------------------------+
示例 2
使用 query_in_wtih_clause 语法方式查询通过“like”边连接的 id 为“1”和“3”的“person”点之间,路径长度不超过 3 跳的单个最短路径。命令如下:
MATCH (m: person {id: 1}),(n:person{id: 3})
WITH m,n, ShortestPath((m)-[e:like*..3]-(n)) AS p
RETURN p;
返回结果示例如下:
+---------------------------------------------------------------------------------------------------------------------------------+
| p |
+=================================================================================================================================+
| Path: [ |
| Vertex _oid: 36198255431778304, label: person |
| -> Edge src: [_oid: 36198255431778304, label: person], dest: [_oid: 36198255431778305, label: person], label: like, _ts: 0 |
| -> Vertex _oid: 36198255431778305, label: person |
| -> Edge src: [_oid: 36198255431778305, label: person], dest: [_oid: 36198255431778306, label: person], label: like, _ts: 0 |
| -> Vertex _oid: 36198255431778306, label: person |
| ] |
+---------------------------------------------------------------------------------------------------------------------------------+
示例 3
使用 query_in_wtih_clause 语法方式查询通过“like”边连接的 id 为“1”和“3”的“person”点之间,路径长度不超过 3 跳的所有最短路径。命令如下:
MATCH (m: person {id: 1}),(n:person{id: 3}) WITH m,n,
allShortestPaths((m)-[e:like*..3]->(n)) AS p
RETURN p;
返回结果示例如下:
+---------------------------------------------------------------------------------------------------------------------------------+
| p |
+=================================================================================================================================+
| Path: [ |
| Vertex _oid: 36198255431778304, label: person |
| -> Edge src: [_oid: 36198255431778304, label: person], dest: [_oid: 36198255431778305, label: person], label: like, _ts: 0 |
| -> Vertex _oid: 36198255431778305, label: person |
| -> Edge src: [_oid: 36198255431778305, label: person], dest: [_oid: 36198255431778306, label: person], label: like, _ts: 0 |
| -> Vertex _oid: 36198255431778306, label: person |
| ] |
+---------------------------------------------------------------------------------------------------------------------------------+
| Path: [ |
| Vertex _oid: 36198255431778304, label: person |
| -> Edge src: [_oid: 36198255431778304, label: person], dest: [_oid: 36198255431778307, label: person], label: like, _ts: 0 |
| -> Vertex _oid: 36198255431778307, label: person |
| -> Edge src: [_oid: 36198255431778307, label: person], dest: [_oid: 36198255431778306, label: person], label: like, _ts: 0 |
| -> Vertex _oid: 36198255431778306, label: person |
| ] |
+---------------------------------------------------------------------------------------------------------------------------------+
allPath()
allPath() 函数用于查找两点之间的所有路径。
语法
query_in_match_clause ::=
MATCH [<path_pattern>,]...
[<path_name> =] ALLPATH (<all_path_pattern>)
query_in_wtih_clause ::=
WITH [<other_column>,]...
ALLPATH (<all_path_pattern>) AS <path_name>
参数说明
| 参数 | 说明 |
|---|---|
<path_pattern> | (可选)定义路径模式的表达式,通常采用 (a)-[f]-(b) 的格式。 |
<path_name> | (可选)路径名称,表示为查询出的所有路径结果设置别名,以便在后续的查询中引用该路径。 |
<all_path_pattern> | 特定路径表达式,用于指定路径的模式。此模式中须包含非匿名的起始点和目标点,以及相关联的边。 |
<other_column> | 除所有路径之外的其他任意属性、表达式或常量等类型的字段。 |
返回值
返回两点间的所有路径。
说明:
- 在使用
allPath()函数时,必须明确指定起始点和目标点,且这两点不能是同一个。 allPath()函数受最大跳数限制。如果超过该限制仍未找到路径,将返回None。默认情况下最大跳数的设置范围为 1~8 的整数,若在调用函数时未明确指定最大跳数,则系统默认最大跳数为 8。根据实际情况,您可以通过SET SESSION或SET GLOBAL命令来调整compiler_max_var_hops参数以自定义最大跳数的取值范围,详情请参见 更改系统变量 章节。
示例 1
使用 query_in_match_clause 语法方式查询通过“like”边连接的 id 为“1”和“3”的“person”点之间,路径长度不超过 3 跳的所有路径。命令如下:
MATCH p=allPath((m: person {id: 1})-[e:like*1..3]->(n:person{id: 3}) )
RETURN p;
返回结果示例如下:
+---------------------------------------------------------------------------------------------------------------------------------+
| p |
+=================================================================================================================================+
| Path: [ |
| Vertex _oid: 36198249205334016, label: person |
| -> Edge src: [_oid: 36198249205334016, label: person], dest: [_oid: 36198249232596994, label: person], label: like, _ts: 0 |
| -> Vertex _oid: 36198249232596994, label: person |
| ] |
+---------------------------------------------------------------------------------------------------------------------------------+
| Path: [ |
| Vertex _oid: 36198249205334016, label: person |
| -> Edge src: [_oid: 36198249205334016, label: person], dest: [_oid: 36198249215819777, label: person], label: like, _ts: 0 |
| -> Vertex _oid: 36198249215819777, label: person |
| -> Edge src: [_oid: 36198249215819777, label: person], dest: [_oid: 36198249232596994, label: person], label: like, _ts: 0 |
| -> Vertex _oid: 36198249232596994, label: person |
| ] |
+---------------------------------------------------------------------------------------------------------------------------------+
示例 2
使用 query_in_wtih_clause 语法方式查询通过“like”边连接的 id 为“1”和“3”的“person”点之间,路径长度不超过 3 跳的所有路径。命令如下:
MATCH (m: person {id: 1}),(n:person{id: 3})
WITH m,n, allPath((m)-[e:like*1..3]->(n)) AS p
RETURN p;
返回结果示例如下:
+---------------------------------------------------------------------------------------------------------------------------------+
| p |
+=================================================================================================================================+
| Path: [ |
| Vertex _oid: 36198249205334016, label: person |
| -> Edge src: [_oid: 36198249205334016, label: person], dest: [_oid: 36198249232596994, label: person], label: like, _ts: 0 |
| -> Vertex _oid: 36198249232596994, label: person |
| ] |
+---------------------------------------------------------------------------------------------------------------------------------+
| Path: [ |
| Vertex _oid: 36198249205334016, label: person |
| -> Edge src: [_oid: 36198249205334016, label: person], dest: [_oid: 36198249215819777, label: person], label: like, _ts: 0 |
| -> Vertex _oid: 36198249215819777, label: person |
| -> Edge src: [_oid: 36198249215819777, label: person], dest: [_oid: 36198249232596994, label: person], label: like, _ts: 0 |
| -> Vertex _oid: 36198249232596994, label: person |
| ] |
+---------------------------------------------------------------------------------------------------------------------------------+
is_trail_path()
is_trail_path() 函数用于判断路径是否满足 trail 特性。在图中,路径是指一个有限或无限的边序列,这些边连接着一系列点,其中点代表图中的顶点,而边则代表连接这些顶点的关系。trail 路径的特点是允许路径中的点重复出现,但边不能重复。所以,如果路径中的每条边都是唯一的,则该函数返回 true,表示这是一个 trail 路径;否则返回 false。
语法
is_trail_path(expression)
参数说明
| 参数 | 说明 |
|---|---|
expression | 返回路径的表达式。 |
返回值
返回值为布尔值,如果给定的路径是 trail 路径,则返回 true;否则返回 false。
说明:
仅 ArcGraph >= v2.1.1 版本支持此函数。
示例
查询满足 trail 路径特性且长度为 3 跳的路径 p,返回路径中所有点的 PK 值。命令如下:
MATCH p = (n)-[e*3]->(m)
WHERE is_trail_path(p) WITH p WITH nodes(p) AS rs
RETURN PK(rs);
返回结果示例如下:
+---------------+
| PK(rs) |
+===============+
| [1, 2, 1, 3] |
+---------------+
| [2, 1, 2, 3] |
+---------------+
列表/数组函数
本章节将介绍 ArcGraph 支持的列表与数组函数。这些函数可以帮助您操作和查询列表和数组中的元素。
size()
size() 函数将返回列表或数组中元素的数量。
语法
size(<list|array>)
参数说明
| 参数 | 说明 |
|---|---|
<list|array> | 返回列表或数组的表达式。 |
返回值
返回值为 int 类型。
示例 1
返回 [1,2,3,4] 列表中元素的数量,命令如下:
RETURN size([1,2,3,4]);
返回结果示例如下:
+-----------------+
| size([1,2,3,4]) |
+=================+
| 4 |
+-----------------+
示例 2
查询数组中元素的数量,命令如下:
MATCH (n:array_index{vid:2})
RETURN size(n.v1);
返回结果示例如下:
+------------+
| size(n.v1) |
+============+
| 3 |
+------------+
head()
head() 函数将返回列表或数组的第一个元素。
语法
head(<list|array>)
参数说明
| 参数 | 说明 |
|---|---|
<list|array> | 返回列表或数组的表达式。 |
返回值
返回值与原列表或数组内的元素类型相同。
示例 1
返回 [1,2,3,4] 列表的第一个元素,命令如下:
RETURN head([1,2,3,4]);
返回结果示例如下:
+-----------------+
| head([1,2,3,4]) |
+=================+
| 1 |
+-----------------+
示例 2
查询数组的第一个元素,命令如下:
MATCH (n:array_index{vid:2})
RETURN head(n.v1);
返回结果示例如下:
+------------+
| head(n.v1) |
+============+
| 2.1 |
+------------+
last()
last() 函数将返回列表或数组的最后一个元素。
语法
last(<list|array>)
参数说明
| 参数 | 说明 |
|---|---|
<list|array> | 返回列表或数组的表达式。 |
返回值
返回值与原列表或数组内的元素类型相同。
示例 1
返回 [1,2,3,4] 列表的最后一个元素,命令如下:
RETURN last([1,2,3,4]);
返回结果示例如下:
+-----------------+
| last([1,2,3,4]) |
+=================+
| 4 |
+-----------------+
示例 2
查询数组的最后一个元素,命令如下:
MATCH (n:array_index{vid:2})
RETURN last(n.v1);
返回结果示例如下:
+------------+
| last(n.v1) |
+============+
| 2.3 |
+------------+
tail()
tail() 函数将返回列表或数组中除第一个元素外的所有元素。
语法
tail(<list|array>)
参��数说明
| 参数 | 说明 |
|---|---|
<list|array> | 返回列表或数组的表达式。 |
返回值
返回值与原列表或数组内的元素类型相同。
示例 1
返回 [1,2,3,4] 列表中除第一个元素外的其他元素,命令如下:
RETURN tail([1,2,3,4]);
返回结果示例如下:
+-----------------+
| tail([1,2,3,4]) |
+=================+
| [2, 3, 4] |
+-----------------+
示例 2
查询数组中除第一个元素外的其他元素,命令如下:
MATCH (n:array_index{vid:2})
RETURN tail(n.v1);
返回结果示例如下:
+------------+
| tail(n.v1) |
+============+
| [2.2, 2.3] |
+------------+
列推导
列推导(List Comprehension)用于将列表或数组中的元素进行过滤和计算,从而生成新的数据列表。
语法
[<variable> IN <list|array> [WHERE <expression1>] | <expression2>]
参数说明
| 参数 | 说明 |
|---|---|
<variable> | 为列表或数组引入一个变量,通过这个变量,可以访问列表或数组中的每个元素。 |
<list|array> | 要遍历的列表或数组的表达式。 说明: - 列表中的元素只支持变量,不支持属性。 - 数组中的元素只支持常量。 |
<expression1> | (可选)一个条件表达式,当满足此条件表达式时,则执行 expression2 表达式,否则直接返回 accumulator。 |
<expression2> | 定义了将当前列表或数组中的元素依次加入到累加器的表达式,并更新累加器的值。 |
返回值
返回值为一个列表。
示例 1
在列表 [1,2,3] 中筛选出所有大于“1”的元素,并将筛选后的结果以列表的形式返回,列表命名为“rs”。命令如下:
RETURN [a IN [1,2,3] WHERE a > 1] AS rs;
返回结果示例如下:
+--------+
| rs |
+========+
| [2, 3] |
+--------+
示例 2
对列表 [1,2,3] 中的每个元素 a,计算 a + 1 的结果,并将结果以列表的形式返回,列表命名为“rs”。命令如下:
RETURN [a IN [1,2,3] | a + 1] AS rs;
返回结果示例如下:
+-----------+
| rs |
+===========+
| [2, 3, 4] |
+-----------+
示例 3
筛选“array_1”点类型中 v1 属性值大于“2”的数值,并对筛选后的数值进行加 1 操作,并将结果以列表的形式返回,列表命名为“rs”。命令如下:
MATCH (a:array_1)
WITH a.v1 AS prop
RETURN [v IN prop WHERE v > 2 | v + 1] AS rs;
返回结果示例如下:
+-----------+
| rs |
+===========+
| [4, 5, 6] |
+-----------+
| [4, 5] |
+-----------+
| [4] |
+-----------+
reduce()
reduce() 函数将列表或数组中的元素根据输入的表达式依次进行累积计算,并将计算结果与当前累加器中的结果进行累加,最后返回完整的计算结果。
语法
reduce(<accumulator> = <initial>, <variable> IN <list|array> [WHERE <expression1>] | <expression2>)
参数说明
| 参数 | 说明 |
|---|---|
<accumulator> | 累加器,用于存储遍历列�表或数组时的中间和最终结果。确保其在遍历过程中持续存在并更新。 |
<initial> | 为 accumulator 提供初始值的表达式或常量。 |
<variable> | 为列表或数组引入一个变量,通过这个变量,可以访问列表或数组中的每个元素。 |
<list|array> | 要遍历的列表或数组的表达式。 |
<expression1> | (可选)一个条件表达式,当满足此条件表达式时,则执行 expression2 表达式,否则直接返回 accumulator。 |
<expression2> | 定义了将当前列表或数组中的元素依次加入到累加器的表达式,并更新累加器的值。 |
返回值
返回值的类型取决于提供的参数以及 expression1、expression2 的语义。
示例 1
当累加器初始值为 totalNum = -20,列表为 [1,2],定义累加表达式为 totalNum + n * 2 则返回累加结果 r。命令如下:
RETURN reduce(totalNum = -20, n IN [1, 2] | totalNum + n * 2) AS r;
返回结果示例如下:
+-----+
| r |
+=====+
| -14 |
+-----+
示例 2
当累加器初始值为 totalNum = -1,列表为 n IN [a in [1,2,3] WHERE a > 2 ],过滤条件为 WHERE totalNum + n> 0 且定义累加表达式为 totalNum + n * 2 时,返回计算结果 r。命令如下:
RETURN reduce(totalNum = -1, n IN [a in [1,2,3] WHERE a > 2 ] WHERE totalNum + n> 0 | totalNum + n * 2) as r;
返回结果示例如下:
+---+
| r |
+===+
| 5 |
+---+
示例 3
当累加器初始值为 totalNum = -20,列表为 n IN [a in [1,2,3] WHERE a > 2 ],过滤条件为 WHERE totalNum + n> 0 且定义累加表达式为 totalNum + n * 2 时,返回计算结果 r。命令如下:
RETURN reduce(totalNum = -20, n IN [a in [1,2,3] WHERE a > 2 ] WHERE totalNum + n> 0 | totalNum + n * 2) as r;
返回结果示例如下:
+-----+
| r |
+=====+
| -20 |
+-----+
range()
range() 函数将返回指定整数范围内固定步长的整数列表。
语法
range(start, end [, step])
参数说明
| 参数 | 说明 |
|---|---|
start | 返回正整数的表达式。 |
end | 返回正整数的表达式。 |
step | (可选)返回正整数的表达式。定义任意相邻两个整数的间隔,若未设置此参数,则默认间隔为 1。 |
返回值
返回值为一个整数列表。
示例 1
返回 -1~5 间的整数,命令如下:
RETURN range(-1,5);
返回结果示例如下:
+------------------------+
| range(-1,5) |
+========================+
| [-1, 0, 1, 2, 3, 4, 5] |
+------------------------+
示例 2
返回 -1~5 间且相邻数字的间隔为 2 的整数,命令如下:
RETURN range(-1,5,2);
返回结果示例如下:
+---------------+
| range(-1,5,2) |
+===============+
| [-1, 1, 3, 5] |
+---------------+
reverse()
reverse() 函数将反转列表或数组中的元素顺序。
语法
reverse(<list|array>)
参数说明
| 参数 | 说明 |
|---|---|
<list|array> | 返回列表或数组的表达式。 |
返回值
返回值与原列表或数组内的元素类型相同。
示例 1
反转 [1,2,3,4] 列表中的元素,命令如下:
RETURN reverse([1,2,3,4]);
返回结果示例如下:
+--------------------+
| reverse([1,2,3,4]) |
+====================+
| [4, 3, 2, 1] |
+--------------------+
示例 2
反转数组中的元素,命令如下:
MATCH (n:array_index{vid:2})
RETURN reverse(n.v1);
返回结果示例如下:
+-----------------+
| reverse(n.v1) |
+=================+
| [2.3, 2.2, 2.1] |
+-----------------+
下标操作
下标操作是指 ArcGraph 图数据库通过指定列表或数组中某个元素的位置(下标)来访问或操作该元素。在 ArcGraph 中,下标支持从前往后查询,下标取值范围为 [0~ 数组/列表长度-1],其中,0 代表第一个元素。当提供的下标超出有效范围时,系统会产生错误处理。
表达式
下标表达式种类包括:
[M]: 表示下标为M的元素。[M..N]:表示M ≤ 下标 < N的元素。[M..]:表示M ≤ 下标的元素。[..N]:表示下标 < N的元素。[..]: 表示所有元素。
语法
#表示 list|array 中下标为 M 的元素
<list|array>[M]
#表示 list|array 中 M ≤ 下标 < N 的元素
<list|array>[M..N]
参数说明
| 参数 | 说明 |
|---|---|
[M] | 返回正整数的表达式。 |
[N] | 返回正整数的表达式。 |
返回值
返回值为 int 类型。
说明:
- 当
M大于列表/数组的长度时,ArcGraph 会报错,请根据错误提示修改语句。 - 当
M≥N时,则返回结果为空。
示例 1
返回 [1,2,3,4] 列表中下标为“1”的元素,命令如下:
RETURN [1,2,3,4,5][1];
返回结果示例如下:
+----------------+
| [1,2,3,4,5][1] |
+================+
| 2 |
+----------------+
示例 2
返回指定列表中下标为“1~5”的元素,命令如下:
RETURN range(-1,5)[1..5];
返回结果示例如下:
+-------------------+
| range(-1,5)[1..5] |
+===================+
| [0, 1, 2, 3] |
+-------------------+
示例 3
返回指定列表中下标大于“5”的元素,命令如下:
RETURN range(-1,5)[5..];
返回结果示例如下:
+------------------+
| range(-1,5)[5..] |
+==================+
| [4, 5] |
+------------------+
示例 4
返回指定列表中下标小于“2”的元素,命令如下:
RETURN range(-1,5)[..2];
返回结果示例如下:
+------------------+
| range(-1,5)[..2] |
+==================+
| [-1, 0] |
+------------------+
示例 5
返回指定列表中的所有元素,命令如下:
RETURN range(-1,5)[..];
返回结果示例如下:
+------------------------+
| range(-1,5)[..] |
+========================+
| [-1, 0, 1, 2, 3, 4, 5] |
+------------------------+
示例 6
返回指定列表中下标大于“5”的元素,命令如下:
RETURN range(-1,5)[6..5];
�返回结果示例如下:
+-------------------+
| range(-1,5)[6..5] |
+===================+
| [] |
+-------------------+
示例 7
返回指定数组中下标为“1~3”的元素,命令如下:
MATCH (n:array_index {vid:2})
RETURN n.v1[1..3];
返回结果示例如下:
+------------+
| n.v1[1..3] |
+============+
| [2.2, 2.3] |
+------------+
示例 8
当M、N为表达式时,返回指定数组中下标为 M~N 的元素,命令如下:
MATCH (n:array_index {vid:2})
RETURN n.v1[n.vid..3];
返回结果示例如下:
+----------------+
| n.v1[n.vid..3] |
+================+
| [2.2, 2.3] |
+----------------+
条件表达式函数
coalesce()
coalesce() 函数返回指定表达式列表中第一个非空表达式的值。
语法
coalesce(expression [, expression]*)
参数说明
| 参数 | 说明 |
|---|---|
expression | 可能返回 null 的表达式。如果所有参数均为 null,则返回 null。 |
返回值
返回值为非空表达式的值。
示例
MATCH (n:person{id:1, name:'John'})
RETURN coalesce(n.age, 2 * 6);
CASE
CASE 函数是图数据库中的一种条件表达式函数,主要用于根据条件判断返回不同的结果。它可以根据不同的条件来选择和返回值,使数据处理更加灵活和精确。
语法
(CASE expression WHEN expression) | (CASE WHEN bool_expression)
THEN expression
[WHEN expression THEN expression]...
[ELSE expression]
END
参数说明
| 参数 | 说明 |
|---|---|
expression | 通用计算表达式。 |
bool_expression | 返回值为 Boolean 类型的表达式。 |
返回值
返回值取决于表达式的结果。
示例 1
查找“person”点类型中 id 为“1”的人的名字,如果名字是“Tome”,结果返回为“1”;如果名字是“Jose”,结果返回为“2”;否则结果返回为“0”。命令如下:
MATCH (a:person {id:1})
RETURN CASE a.name WHEN "Tome" THEN 1 WHEN "Jose" THEN 2 ELSE 0 END AS tag;
返回结果示例如下:
+-----+
| tag |
+=====+
| 0 |
+-----+
示例 2
查找与名为“Jhon”的人有关联关系的其他人的数量,并返回该数量和“Jhon”的 id。如果数量超过 10 则只返回 10,如果不超过 10 则返回实际的数量。命令如下:
MATCH (a:person{name:"John"})-[f]->(b:person)
WITH a.id AS a_id, count(b.name) AS cnt
WITH a_id, CASE WHEN toInteger(cnt) > 10 THEN 10 ELSE toInteger(cnt) END AS cnt1
RETURN a_id, cnt1;
返回结果示例如下:
+------+------+
| a_id | cnt1 |
+======+======+
| 1 | 1 |
+------+------+
Geo 函数
自 ArcGraph v2.1.2 版本起,ArcGraph 图数据库内置了 Geo 函数,它是一组专门用于处理地理空间数据的函数,支持对地理空间数据进行查看、关系判断和距离计算等操作。
ST_Point()
ST_Point() 函数用于根据给定的 GeoJSON 格式的字符串表达式构建并返回一个 ST_GEOMETRY 类型的地理空间点(Point)对象。
语法
ST_Point(expression, [<srid>])
参数说明
| 参数 | 说明 |
|---|---|
expression | 返回 Point 类型的 GeoJSON 格式的字符串表达式。 说明: expression 的输入参数必须是包含类型与坐标等必要信息的有效 GeoJSON 地理空间数据。 |
[<srid>] | (可选)空间参考系统标识符(SRID),用于设置地理坐标系统的 WKID(Well-Known ID)值,表示构建地理空间点(Point)对象时所采用的地理坐标系统。支持的 <srid> 值包括“0”(如果未设置,则默认为 0,表示直角坐标系)、“4326”(WGS 84 坐标系)以及“4490”(CGCS2000 坐标系)。 |
返回值
返回值为 ST_GEOMETRY 类型。
示例 1
在当前图中返回一个坐标为 (1.5, 1.1) 的点,并使用直角坐标系构建其 ST_GEOMETRY 值。命令如下:
RETURN ST_Point('{"type":"Point","coordinates":[1.5,1.1]}');
返回结果示例如下:
+------------------------------------------------------------+
| st_point("{\"type\":\"Point\",\"coordinates\":[1.5,1.1]}") |
+============================================================+
| {"type":"Point","coordinates":[1.5,1.1]} |
+------------------------------------------------------------+
示例 2
在当前图中返回一个坐标为 (116.407526, 39.904030) 的点,并使用 WGS84 坐标系来构建其 ST_GEOMETRY 值。命令如下:
RETURN ST_Point('{"type":"Point","coordinates":[116.407526, 39.904030]}', 4326);
返回结果示例如下:
+-------------------------------------------------------------------------------+
| st_point("{\"type\":\"Point\",\"coordinates\":[116.407526, 39.904030]}",4326) |
+===============================================================================+
| {"type":"Point","coordinates":[116.407526,39.90403]} |
+-------------------------------------------------------------------------------+
ST_Line()
ST_Line() 函数用于根据给定的 GeoJSON 格式的字符串表达式构建并返回一个 ST_GEOMETRY 类型的地理空间线(LineString)对象。
语法
ST_Line(expression, [<srid>])
参数说明
| 参数 | 说明 |
|---|---|
expression | 返回 LineString 类型的 GeoJSON 格式的字符串表达式。 说明: expression 的输入参数必须是包含类型与坐标等必要信息的有效 GeoJSON 地理空间数据。 |
[<srid>] | (可选)空间参考系统标识符(SRID),用于设置地理坐标系统的 WKID(Well-Known ID)值,表示构建地理空间线(LineString)对象时所采用的地理坐标系统。支持的 <srid> 值包括“0”(如果未设置,则默认为 0,表示直角坐标系)、“4326”(WGS 84 坐标系)以及“4490”(CGCS2000 坐标系)。 |
返回值
返回值为 ST_GEOMETRY 类型。
示例 1
在当前图中返回一个由顶点 (-1,-1) 到顶点 (1,-1) 组成的直线,并使用直角坐标系构建其 ST_GEOMETRY 值,结果命名为 line 返回。命令如下:
RETURN ST_Line('{"type": "LineString", "coordinates": [[-1,-1],[1,-1]]}') AS line;
返回结果示例如下:
+--------------------------------------------------------------+
| line |
+==============================================================+
| {"type":"LineString","coordinates":[[-1.0,-1.0],[1.0,-1.0]]} |
+--------------------------------------------------------------+
示例 2
在当前图中返回一个由顶点 (116.407526, 39.904030) 到顶点 (116.407526, 39.904040) 组成的直线,并使用 WGS84 坐标系来构建其 ST_GEOMETRY 值,结果命名为 line 返回。命令如下:
RETURN ST_Line('{"type": "LineString", "coordinates": [[116.407526, 39.904030],[116.407526, 39.904040]]}', 4326) AS line;
返回结果示例如下:
+-----------------------------------------------------------------------------------+
| line |
+===================================================================================+
| {"type":"LineString","coordinates":[[116.407526,39.90403],[116.407526,39.90404]]} |
+-----------------------------------------------------------------------------------+
ST_Polygon()
ST_Polygon() 函数用于根据给定的 GeoJSON 格式的字符串表达式构建并返回一个 ST_GEOMETRY 类型的地理空间多边形(Polygon)对象。该多边形可以�包含多个环,其中首个环定义为外环,其余环则为内环(即洞)。
语法
ST_Polygon(expression, [<srid>])
参数说明
| 参数 | 说明 |
|---|---|
expression | 返回 Polygon 类型的 GeoJSON 格式的字符串表达式。 说明: expression 的输入参数必须是包含类型与坐标等必要信息的有效 GeoJSON 地理空间数据。 |
[<srid>] | (可选)空间参考系统标识符(SRID),用于设置地理坐标系统的 WKID(Well-Known ID)值,表示构建地理空间多边形(Polygon)对象时所采用的地理坐标系统。支持的 <srid> 值包括“0”(如果未设置,则默认为 0,表示直角坐标系)、“4326”(WGS 84 坐标系)以及“4490”(CGCS2000 坐标系)。 |
返回值
返回值为 ST_GEOMETRY 类型。
示例 1
在当前图中返回一个由顶点 (1.1,1.1)、(2.1,1.1)、(2.1,3.1)、(1.1,3.1) 组成的无洞多边形,并使用直角坐标系构建其 ST_GEOMETRY 值。命令如下:
RETURN ST_Polygon('{"type": "Polygon", "coordinates": [[[1.1,1.1],[2.1,1.1],[2.1,3.1],[1.1,3.1]]]}');
返回结果示例如下:
+-----------------------------------------------------------------------------------------------------+
| ST_Polygon("{\"type\": \"Polygon\", \"coordinates\": [[[1.1,1.1],[2.1,1.1],[2.1,3.1],[1.1,3.1]]]}") |
+=====================================================================================================+
| {"type":"Polygon","coordinates":[[[1.1,1.1],[2.1,1.1],[2.1,3.1],[1.1,3.1],[1.1,1.1]]]} |
+-----------------------------------------------------------------------------------------------------+
示例 2
在当前图中返回一个由顶点 (116.407526, 39.904030)、(118.407526, 39.904030)、(118.407526, 39.904040)、(116.407526, 39.904040) 组成的无洞多边形,并使用 WGS84 坐标系来构建其 ST_GEOMETRY 值。命令如下:
RETURN ST_Polygon('{"type": "Polygon", "coordinates": [[[116.407526, 39.904030],[118.407526, 39.904030],[118.407526, 39.904040],[116.407526, 39.904040]]]}', 4326);
返回结果示例如下:
+------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| ST_Polygon("{\"type\": \"Polygon\", \"coordinates\": [[[116.407526, 39.904030],[118.407526, 39.904030],[118.407526, 39.904040],[116.407526, 39.904040]]]}",4326) |
+==================================================================================================================================================================+
| {"type":"Polygon","coordinates":[[[116.407526,39.90403],[118.407526,39.90403],[118.407526,39.90404],[116.407526,39.90404],[116.407526,39.90403]]]} |
+------------------------------------------------------------------------------------------------------------------------------------------------------------------+
示例 3
在当前图中返回一个包含两个环(一个外环和一个内环)的多边形,并使用直角坐标系构建其 ST_GEOMETRY 值。外环的顶点依次为 (1.1,1.1)、(2.1,1.1)、(2.1,3.1)、(1.1,3.1),内环的顶点依次为 (1.2,1.2)、(1.6,1.2)、(1.6,1.6)、(1.2,1.6)。命令如下:
RETURN ST_Polygon('{"type": "Polygon", "coordinates": [[[1.1,1.1],[2.1,1.1],[2.1,3.1],[1.1,3.1]],[[1.2,1.2],[1.6,1.2],[1.6,1.6],[1.2,1.6]]]}');
返回结果示例如下:
+-----------------------------------------------------------------------------------------------------------------------------------------------+
| ST_Polygon("{\"type\": \"Polygon\", \"coordinates\": [[[1.1,1.1],[2.1,1.1],[2.1,3.1],[1.1,3.1]],[[1.2,1.2],[1.6,1.2],[1.6,1.6],[1.2,1.6]]]}") |
+===============================================================================================================================================+
| {"type":"Polygon","coordinates":[[[1.1,1.1],[2.1,1.1],[2.1,3.1],[1.1,3.1],[1.1,1.1]],[[1.2,1.2],[1.6,1.2],[1.6,1.6],[1.2,1.6],[1.2,1.2]]]} |
+-----------------------------------------------------------------------------------------------------------------------------------------------+
ST_GeomFromText()
ST_GeomFromText() 函数根据给定的 Well-Known Text (WKT) 格式的字符串表达式构建并返回地理空间对象的 ST_GEOMETRY 类型的值。
语法
ST_GeomFromText(expression, [<srid>])
参数说明
| 参数 | 说明 |
|---|---|
expression | 返回一个包含 WKT 表达式的字符串,用于定义地理空间对象。 |
[<srid>] | (可选)空间参考系统标识符(SRID),用于设置地理坐标系统的 WKID(Well-Known ID)值,表示构建地理空间对象时所采用的地理坐标系统。支持的 <srid> 值包括“0”(如果未设置,则默认为 0,表示直角坐标系)、“4326”(WGS 84 坐标系)以及“4490”(CGCS2000 坐标系)。 |
返回值
返回值为 ST_GEOMETRY 类型。
示例 1
在当前图中返回一个坐标为 (1.5, 1.1) 的地理空间点对象,并使用直角坐标系构建其 ST_GEOMETRY 值。命令如下:
RETURN ST_GeomFromText('Point(1.5 1.1)') AS point;
返回结果示例如下:
+------------------------------------------+
| point |
+==========================================+
| {"type":"Point","coordinates":[1.5,1.1]} |
+------------------------------------------+
示例 2
在当前图中返回一个坐标为 (116.407526, 39.904030) 的地理空间点对象,并使用 WGS84 坐标系来构建其 ST_GEOMETRY 值。命令如下:
RETURN ST_GeomFromText('Point(116.407526 39.904030)', 4326) AS point;
返回结果示例如下:
+------------------------------------------------------+
| point |
+======================================================+
| {"type":"Point","coordinates":[116.407526,39.90403]} |
+------------------------------------------------------+
ST_Contains()
ST_Contains() 函数用于判断同一坐标系统下,一个地理空间对象(outer)中是否完全包含另一个地理空间对象(inner)。与 ST_Within() 函数在逻辑上是互逆的,即如果 A 包含 B(ST_Contains(A, B) 为真),则 B 一定位于 A 内(ST_Within(B, A) 也为真)。
语法
ST_Contains (outer,inner)
参数说明
| 参数 | 说明 |
|---|---|
outer | 返回 ST_GEOMETRY 类型的表达式。 |
inner | 返回 ST_GEOMETRY 类型的表达式 |
返回值
返回值为 Boolean 类型,如果 outer 完全包含 inner,则返回 true;否则返回 false。
示例 1
在当前图中查找 area 点类型的点,并判断直角坐标系下指定多边形(由顶点 (1.1,1.2)、(2.1,1.2)、(2.1,3.2)、(1.1,3.2) 组成)是否包含其 range 属性值。命令如下:
MATCH (n:area)
RETURN ST_Contains(ST_Polygon('{"type": "Polygon", "coordinates": [[[1.1,1.2],[2.1,1.2],[2.1,3.2],[1.1,3.2]]]}'), n.range);
返回结果示例如下:
+--------------------------------------------------------------------------------------------------------------------------+
| st_contains(ST_Polygon("{\"type\": \"Polygon\", \"coordinates\": [[[1.1,1.2],[2.1,1.2],[2.1,3.2],[1.1,3.2]]]}"),n.range) |
+==========================================================================================================================+
| false |
+--------------------------------------------------------------------------------------------------------------------------+
示例 2
在当前图中查找 location 点类型的点,并判断 WGS84 坐标系下指定多边形(由顶点 (116.407526, 39.904030)、(118.407526, 39.904030)、(118.407526, 39.904040)、(116.407526, 39.904040) 组成)是否包含其 position 属性值。命令如下:
MATCH (n:location)
RETURN ST_Contains(ST_Polygon('{"type": "Polygon", "coordinates": [[[116.407526, 39.904030],[118.407526, 39.904030],[118.407526, 39.904040],[116.407526, 39.904040]]]}', 4326), n.position);
返回结果示例如下:
+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| st_contains(ST_Polygon("{\"type\": \"Polygon\", \"coordinates\": [[[116.407526, 39.904030],[118.407526, 39.904030],[118.407526, 39.904040],[116.407526, 39.904040]]]}",4326),n.position) |
+==========================================================================================================================================================================================+
| false |
+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| false |
+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| false |
+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| false |
+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| false |
+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| false |
+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
ST_Within()
ST_Within() 函数用于判断同一坐标系统下,一个地理空间对象(left)是否完全位于另一个地理空间对象(right)内。ST_Within() 与 ST_Contains() 函数在逻辑上是互逆的。
语法
ST_Within(left,right)
参数说明
| 参数 | 说明 |
|---|---|
left | 返�回 ST_GEOMETRY 类型的表达式。 |
right | 返回 ST_GEOMETRY 类型的表达式。 |
返回值
返回值为 Boolean 类型,如果 left 完全位于 right 内部,则返回 true;否则返回 false。
示例 1
在当前图中查找 area 点类型的点,并判断直角坐标系下其 range 属性值是否位于指定多边形(由顶点 (1.1,1.1)、(2.1,1.1)、(2.1,3.1)、(1.1,3.1) 组成)内。命令如下:
MATCH (n:area)
RETURN ST_Within(n.range, ST_Polygon('{"type": "Polygon", "coordinates": [[[1.1,1.1],[2.1,1.1],[2.1,3.1],[1.1,3.1]]]}'));
返回结果示例如下:
RETURN ST_Within(n.range, ST_Polygon('{"type": "Polygon", "coordinates": [[[1.1,1.1],[2.1,1.1],[2.1,3.1],[1.1,3.1]]]}'));
+------------------------------------------------------------------------------------------------------------------------+
| st_within(n.range,ST_Polygon("{\"type\": \"Polygon\", \"coordinates\": [[[1.1,1.1],[2.1,1.1],[2.1,3.1],[1.1,3.1]]]}")) |
+========================================================================================================================+
| false |
+------------------------------------------------------------------------------------------------------------------------+
示例 2
在当前图中查找 location 点类型的点,并判断 WGS84 坐标系下其 position 属性值是否位于指定多边形(由顶点 (116.407526, 39.904030)、(118.407526, 39.904030)、(118.407526, 39.904040)、(116.407526, 39.904040) 组成)内。命令如下:
MATCH (n:location)
RETURN ST_Within(n.position, ST_Polygon('{"type": "Polygon", "coordinates": [[[116.407526, 39.904030],[118.407526, 39.904030],[118.407526, 39.904040],[116.407526, 39.904040]]]}', 4326));
返回结果示例如下:
+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| st_within(n.position,ST_Polygon("{\"type\": \"Polygon\", \"coordinates\": [[[116.407526, 39.904030],[118.407526, 39.904030],[118.407526, 39.904040],[116.407526, 39.904040]]]}",4326)) |
+========================================================================================================================================================================================+
| false |
+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| false |
+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| false |
+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| false |
+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| false |
+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| false |
+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
ST_Equals()
ST_Equals() 函数用于判断同一坐标系统下的两个地理空间对象(left 和 right)是否完全相同。
语法
ST_Equals (left,right)
参数说明
| 参数 | 说明 |
|---|---|
left | 返回 ST_GEOMETRY 类型的表达式。 |
right | 返回 ST_GEOMETRY 类型的表达式。 |
返回值
返回值为 Boolean 类型,如果两个对象完全相同,则返回 true;否则返回 false。
示例 1
在当前图中查找 area 点类型的点,并判断直角坐标系下其 range 属性值是否与指定点(坐标为 (1.5, 1.1))相等。命令如下:
MATCH (n:area)
RETURN ST_Equals(n.range, ST_Point('{"type":"Point","coordinates":[1.5,1.1]}'));
返回结果示例如下:
+-------------------------------------------------------------------------------+
| st_equals(n.range,st_point("{\"type\":\"Point\",\"coordinates\":[1.5,1.1]}")) |
+===============================================================================+
| false |
+-------------------------------------------------------------------------------+
示例 2
在当前图中查找 location 点类型的点,并判断 WGS84 坐标系下其 position 属性值是否与指定点(坐标为 (116.407526, 39.904030))相等。命令如下:
MATCH (n:location)
RETURN ST_Equals(n.position, ST_Point('{"type":"Point","coordinates":[116.407526, 39.904030]}',4326));
返回结果示例如下:
+-----------------------------------------------------------------------------------------------------+
| st_equals(n.position,st_point("{\"type\":\"Point\",\"coordinates\":[116.407526, 39.904030]}",4326)) |
+=====================================================================================================+
| false |
+-----------------------------------------------------------------------------------------------------+
| false |
+-----------------------------------------------------------------------------------------------------+
| false |
+-----------------------------------------------------------------------------------------------------+
| false |
+-----------------------------------------------------------------------------------------------------+
| false |
+-----------------------------------------------------------------------------------------------------+
| false |
+-----------------------------------------------------------------------------------------------------+
ST_Intersects()
ST_Intersects() 函数用于判断同一坐标系统下的两个地理空间对象(left 和 right)是否相交。
语法
ST_Intersects (left,right)
参数说明
| 参数 | 说明 |
|---|---|
left | 返回 ST_GEOMETRY 类型的表达式。 |
right | 返回 ST_GEOMETRY 类型的表达式。 |
返回值
返回值为 Boolean 类型,如果两个对象相交,则返回 true;否则返回 false。
示例 1
在当前图中判断直角坐标系下两条线段([(0,0),(1,1)] 和 [(0,1),(1,0)])是否相交,并将结果命名为 is_intersects 返回。命令如下:
RETURN ST_Intersects(ST_Line('{"type": "LineString", "coordinates": [[0,0],[1,1]]}'), ST_Line('{"type": "LineString", "coordinates": [[0,1],[1,0]]}')) AS is_intersects;
返回结果示例如下:
+---------------+
| is_intersects |
+===============+
| true |
+---------------+
示例 2
在当前图中判断 WGS84 坐标系下两条线段([(116.407526, 39.904030),(116.407526, 39.904035)] 和 [(117.407526, 39.904030),(117.407526, 39.904040)])是否相交,并将结果命名为 is_intersects 返回。命令如下:
RETURN ST_Intersects(ST_Line('{"type": "LineString", "coordinates": [[116.407526, 39.904030],[116.407526, 39.904035]]}',4326), ST_Line('{"type": "LineString", "coordinates": [[117.407526, 39.904030],[117.407526, 39.904040]]}',4326)) AS is_intersects;
返回结果示例如下:
+---------------+
| is_intersects |
+===============+
| false |
+---------------+
ST_Distance()
ST_Distance() 函数用于计算同一坐标系统下的两个地理空间对象(left 和 right)之间的距离。
语法
ST_Distance (left, right)
参数说明
| 参数 | 说明 |
|---|---|
left | 返回 ST_GEOMETRY 类型的表达式。 |
right | 返回 ST_GEOMETRY 类型的表达式。 |
距离计算说明
-
直角坐标系:
- 当地理空间对象使用的是直角坐标系(
<SRID>=0)时,ST_Distance()函数将计算两个地理空间对象之间的欧几里得距离(即直线距离)。 - 返回值的单位与输入参数所使用的坐标系单位相同。
- 当地理空间对象使用的是直角坐标系(
-
地理坐标系:
- 当地理空间对象使用的是 WGS84(
<SRID>=4326)或 CGCS2000(<SRID>=4490)时,ST_Distance()函数计算的是两点间的球面距离。 - 使用 Vincenty 公式(基于椭球模型)进行计算,返回值的单位为米。
- 当地理空间对象使用的是 WGS84(
返回值
返回值为 Double 类型。
示例 1
在当前图中使用直角坐标系计算点 (1,1) 与线段 [(-1,-1),(1,-1)] 之间的直线距离,并将结果命名为 distance 返回。命令如下:
RETURN ST_Distance(ST_Point('{"type":"Point","coordinates":[1,1]}'), ST_Line('{"type": "LineString", "coordinates": [[-1,-1],[1,-1]]}')) AS distance;
返回结果示例如下:
+----------+
| distance |
+==========+
| 2 |
+----------+
示例 2
在当前图中使用直角坐标系返回两个点(坐标分别为 (1,1) 和 (2,1))之间的直线距离,并将结果命名为 distance 返回。命令如下:
RETURN ST_Distance(ST_Point('{"type":"Point","coordinates":[1,1]}'), ST_Point('{"type":"Point","coordinates":[2,1]}')) AS distance;
返回结果示例如下:
+----------+
| distance |
+==========+
| 1 |
+----------+
示例 3
在当前图中使用 WGS84 坐标系返回两个点(坐标分别为 (-74.006,40.7128) 和 (-0.1278,51.5074))之间的球面距离,并将结果命名为 distance 返回。命令如下:
RETURN ST_Distance(ST_Point('{"type":"Point","coordinates":[-74.006,40.7128]}',4326), ST_Point('{"type":"Point","coordinates":[-0.1278,51.5074]}',4326)) AS distance;
返回结果示例如下:
+------------------+
| distance |
+==================+
| 5585233.57894328 |
+------------------+
时态图
在 ArcGraph 图数据库中,有些应用场景是基于时间点或者时间范围来进行查询计算的。为此我们引入了时态图的概念,即在边的定义中添加一个独特的时间戳属性,精确记录了当前关系发生的时间。这一特性能够存储和追溯过去的关系状态,为用户提供了数据演变的清晰视图。例如,在处理转账场景时,用户可以查询时态边以获取特定时刻的转账详情。时态边的引入为用户提供了更丰富的数据分析和洞察能力,使他们能够更好地理解和管理图中动态变化的数据关系。
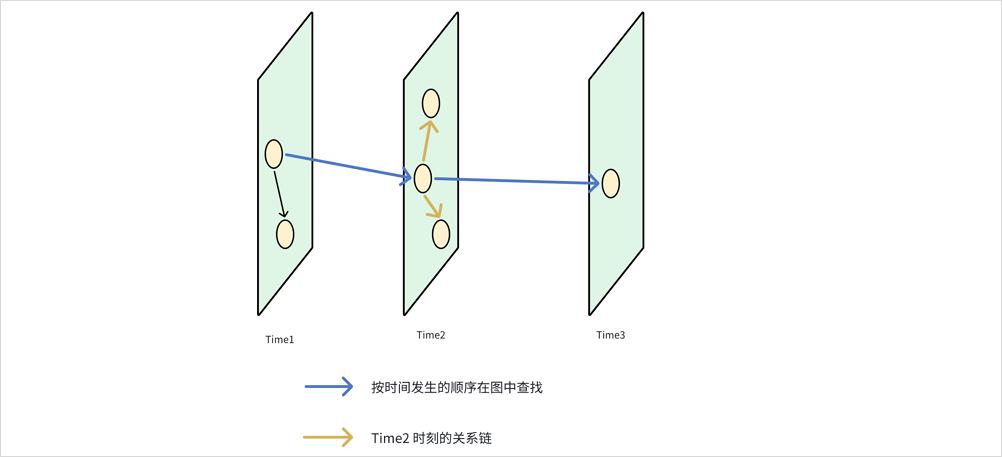
如上图所示,该图直观地展示了时态图的概念,通过从左至右的时间点(Time1、Time2、Time3)和连接点与边的关系链,强调了关系或事件随时间流动的变化。其中“Time2时刻的关系链”强调了在特定时间点(Time2)下关系或事件的状态。
以转账场景为例,时态图通过连接点(代表账户)和带有时间戳属性的边(代表转账操作),展示了转账链路的时序变化。用户可以通过查询时间戳来追溯转账链路的起始和结束时间,以及在此时间范围内发生的转账详情。此外,时态图还支持对转账金额进行聚合分析,如求和、最大值计算等,帮助用户更深入地理解转账链路的资金流动情况。
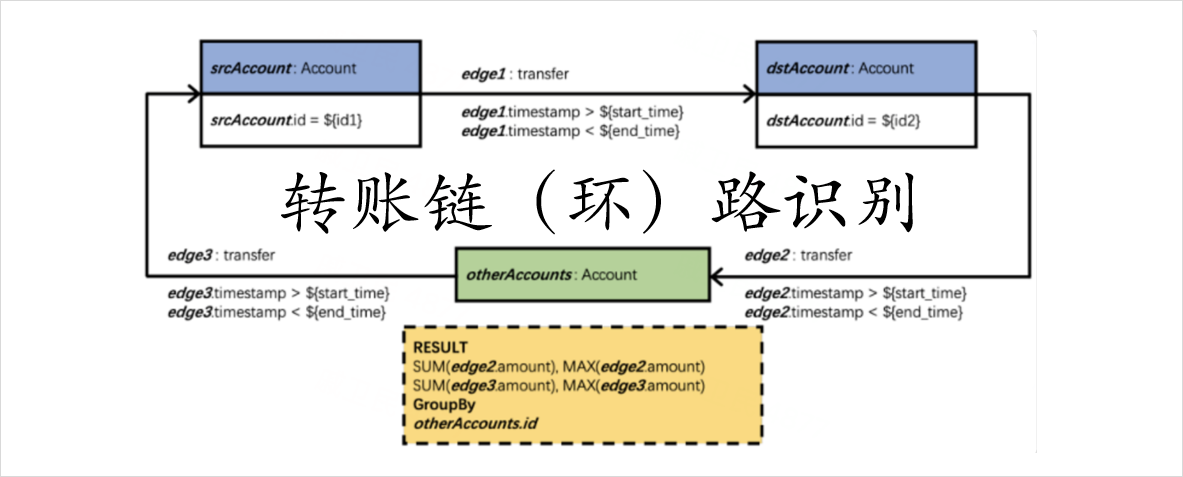
创建时态边类型
语法
create_edge ::=
CREATE TEMPORAL EDGE [IF NOT EXISTS] <edge_name>
( <edge_body> [, <edge_body>]... )
[ COMMENT = < string > ];
edge_body ::=
<edge_end_point>
| <normal_property>
| <embedded_index>;
edge_end_point ::= FROM vertex_name TO vertex_name;
详细说明
部分参数说明如下,其他参数说明请参考 创建边类型 章节。
| 参数 | 说明 |
|---|---|
[TEMPORAL] | 关键字,用于表示该边类型是时态边类型。 |
示例
在当前图中创建一个�名为“transfer”的时态边类型,命令如下:
CREATE TEMPORAL EDGE transfer(
serial_number INT(64) COMMENT '序号',
issue_time datetime COMMENT '转账时间',
FROM person TO person
)
COMMENT = '转账测试';
新增时态边数据
使用 INSERT 命令为时态边类型中插入时态边数据,语法及详细说明请参见 新增数据 章节。
在新增时态边数据时,必须为 _ts 属性指定一个精确到毫秒的时间戳值,支持使用 int(>0)、now() 函数或 toTimestamp() 函数进行设置。关于 localdatetime() 和 toTimestamp() 函数详情请参见 localdatetime() 章节和 toTimestamp() 章节。
详细说明
INSERT插入子句不可在MATCH查询子句之后。- 每一个
INSERT插入子句,至多允许一个边类型。 INSERT子句插入边数据时,连接的点必须包含具体点类型以及点数据的主键信息。_ts作为一个特殊属性放在边类型中,它作为保留字不允许被用作普通属性名称。
新增带有整数值属性的时态边数据
在新增时态边数据时,通过设置 _ts 属性为整数值,用户可以方便地查询特定整数值的时态边数据。
示例
在当前图中,向“transfer”时态边类型新增一条 _ts 属性值为“2”的时态边数据。命令如下:
INSERT (:person{id:1})-[:transfer{_ts: 2}]->(:person{id:2});
新增带有当前时间属性的时态边数据
在新增时态边数据时,通过将 _ts 属性设置为当前时间(now()),可以为时态边数据添加时间戳,以便跟踪边的创建时间。
示例
在当前图中,向“transfer”时态边类型新增一条带有当前时间的时态边数据。命令如下:
INSERT (:person{id:1})-[:transfer{_ts: now()}]->(:person{id:2});
新增带有具体时间属性的时态边数据
在新增时态边数据时,通过将 _ts 属性设置为特定的日期或时间,为时态边数据添加指定的时间戳,用户可以根据需要查询指定时间或时间范围内的时态边数据。
当 _ts 属性设置为日期或时间的格式如下:
| 属性 | 说明 | 示例 |
|---|---|---|
| 日期 | 使用四位数表示年份,两位数表示月份和日期,顺序为年月日。 | 20231201 |
| 时间 | 遵循 ISO 8601 标准,包括日期、时间及可能的时区信息。 | 2018-01-26T10:30:09+08:00 |
示例 1
在当前图中,向“transfer”时态边类型新增一条带有日期戳为“20231201”的时态边数据。命令如下:
INSERT (:person{id:1})-[:transfer{_ts: toTimestamp('20231201')}]->(:person{id:2});
示例 2
在当前图中,向“transfer”时态边类型新增一条带有时间戳为“2018-01-26T10:30:09+08:00”的时态边数据。命令如下:
INSERT (:person{id:1})-[:transfer{_ts: toTimestamp('2018-01-26T10:30:09+08:00')}]->(:person{id:2});
查看时态边数据
语法
<query> ::= <match> <return> [temporal_filter];
temporal_filter ::= TEMPORAL {<point_time> | <range_time> | ALL};
point_time ::= <int_value> | <string_representing_datetime> | NOW()
range_time ::= {'(' | '['} <from_time> , <to_time> {')' | ']'}
from_time ::= <int_value>| <string_representing_datetime>
to_time ::= <int_value>| <string_representing_datetime>| NOW()
详细说明
range_time中“(”表示不包含边界值,“[”表示包含边界值。若未设置range_time,则默认返回最新_ts的数据。from_time:起始时间,支持int和'yyyymmdd'数据类型。to_time:终止时间,支持int、'yyyymmdd'和now()数据类型。ALL:表示所有时间点,�自 ArcGraph v2.1.2 版本起,时态边查询新增了ALL关键字,支持查看指定边在所有时间点的数据。
示例 1
在当前的图中,查询与 person 点类型 id 为“1”的点相关联的 transfer 边类型中时间点小于等于“2”的边数据。命令如下:
MATCH (m:person{id:1})-[e:transfer]->(n)
RETURN e
TEMPORAL 2;
返回结果示例如下:
+---------------------------------------------------------------------------------------------------------------------------------------------------------+
| e |
+=========================================================================================================================================================+
| eid: [src: [_oid: 37131198408949760, label: person], dest: [_oid: 37131198419435521, label: person], label: transfer, _ts: 2], properties: [null, null] |
+---------------------------------------------------------------------------------------------------------------------------------------------------------+
示例 2
在当前的图中,查询与 person 点类型 id 为“1”的点相关联的 transfer 边类型中时间点为从1970 年 1 月 1 日至当前时间范围内的边数据。命令如下:
MATCH (m:person{name:'John'})-[e:transfer]->(n)
RETURN e
TEMPORAL (0, now());
返回结果示例如下:
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| e |
+=====================================================================================================================================================================+
| eid: [src: [_oid: 37131198408949760, label: person], dest: [_oid: 37131198419435521, label: person], label: transfer, _ts: 1723619450000], properties: [null, null] |
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| eid: [src: [_oid: 37131198408949760, label: person], dest: [_oid: 37131198419435521, label: person], label: transfer, _ts: 1701388800000], properties: [null, null] |
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| eid: [src: [_oid: 37131198408949760, label: person], dest: [_oid: 37131198419435521, label: person], label: transfer, _ts: 1516962609000], properties: [null, null] |
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| eid: [src: [_oid: 37131198408949760, label: person], dest: [_oid: 37131198419435521, label: person], label: transfer, _ts: 2], properties: [null, null] |
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------+
示例 3
在当前的图中,查询与 person 点类型 id 为“1”的点相关联的 transfer 边类型中在指定日期范围内的边数据。命令如下:
MATCH (m:person{id:1})-[e:transfer]->(n)
RETURN e
TEMPORAL ['20231201', '20231230'];
返回结果示例如下:
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| e |
+=====================================================================================================================================================================+
| eid: [src: [_oid: 37131198408949760, label: person], dest: [_oid: 37131198419435521, label: person], label: transfer, _ts: 1701388800000], properties: [null, null] |
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------+
示例 4
在当前的图中,查询与 person 点类型 id 为“1”的点相关联的 transfer 边类型中时间点小于等于“2023-12-01”的边数据。命令如下:
MATCH (m:person{id:1})-[e:transfer]->(n)
RETURN e
TEMPORAL '2023-12-01';
返回结果示例如下:
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| e |
+=====================================================================================================================================================================+
| eid: [src: [_oid: 37131198408949760, label: person], dest: [_oid: 37131198419435521, label: person], label: transfer, _ts: 1701388800000], properties: [null, null] |
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------+
示例 5
ArcGraph >= v2.1.2 时,在当前的图中查询并返回与 person 点类型 id 为“1”的点相关联的 transfer 边类型中所有时间点的边数据。命令如下:
MATCH (m:person{id:1})-[e:transfer]->(n)
RETURN e
TEMPORAL ALL;
返回结果示例如下:
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| e |
+=====================================================================================================================================================================+
| eid: [src: [_oid: 37131198408949760, label: person], dest: [_oid: 37131198419435521, label: person], label: transfer, _ts: 1723619450000], properties: [null, null] |
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| eid: [src: [_oid: 37131198408949760, label: person], dest: [_oid: 37131198419435521, label: person], label: transfer, _ts: 1701388800000], properties: [null, null] |
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| eid: [src: [_oid: 37131198408949760, label: person], dest: [_oid: 37131198419435521, label: person], label: transfer, _ts: 1516962609000], properties: [null, null] |
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| eid: [src: [_oid: 37131198408949760, label: person], dest: [_oid: 37131198419435521, label: person], label: transfer, _ts: 2], properties: [null, null] |
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------+
修改时态边数据
在修改时态边数据时,可以根据时态属性(即 _ts)来定位并修改指定边。不支持修改主键 id 和 _ts 值。
示例
在当前图中,查找与 person 点类型 id 为“1”的点相关联的 transfer 边类型中时间点为“2”的边数据,并修改其 issue_time 属性为“20231202”。命令如下:
MATCH (m:person {id: 1})-[r:transfer{_ts: 2}]->(n)
SET r.issue_time = '20231202';
删除时态边数据
在删除时态边数据时,可以根据时态属性(即 _ts)来定位并删除指定边。
示例 1
在当前图中,删除与 person 点类型中 id 为“1”的点相关联的 transfer 边类型中时间点为“2”的边数据。命令如下:
MATCH (m:person {id: 1})-[e:transfer{_ts: 2}]->(n)
DETACH DELETE e;
返回结果示例如下:
+--------+------+-------+
| Vertex | Edge | Error |
+========+======+=======+
| 0 | 1 | [] |
+--------+------+-------+
示例 2
在当前图中,删除与 person 点类型 id 为“1”的点相关联的 transfer 边类型中从1970 年 1 月 1 日至当前时间范围内的边数据。命令如下:
MATCH (m:person {id: 1})-[e:transfer{_ts: now()}]->(n)
DETACH DELETE e;
返回结果示例如下:
+--------+------+-------+
| Vertex | Edge | Error |
+========+======+=======+
| 0 | 1 | [] |
+--------+------+-------+
示例 3
在当前图中,删除与 person 点类型 id 为“1”的点相关联的一条带有日期戳为“20231201”的时态边数据。命令如下:
MATCH (m:person {id: 1})-[e:transfer{_ts: toTimestamp('20231201')}]->(n)
DETACH DELETE e;
返回结果示例如下:
+--------+------+-------+
| Vertex | Edge | Error |
+========+======+=======+
| 0 | 1 | [] |
+--------+------+-------+
示例 4
在当前图中,删除与 person 点类型 id 为“1”的点及其相关联的所有边。命令如下:
MATCH (p:person {id:1, name:'John'})
DETACH DELETE p;
返回结果示例如下:
+--------+------+-------+
| Vertex | Edge | Error |
+========+======+=======+
| 1 | 3 | [] |
+--------+------+-------+
相关操作
更多关于时态边的操作,详情请参考如下链接:
JSON 简介
JSON 是一种轻量级的数据交换格式,它采用完全独立于编程语言的文本格式来存储和表示数据。JSON 文件的文件类型是“.json”。
语法
JSON 部分语法如下所示,更多语法请参考:JSON 介绍。
-
JSON Object
JSON Object 在 JSON 中表示键值对的数据结构,它是由“”包围的键值对集合,键和值之间用冒号“:”分隔,不同的键值对之间用逗号“,”分隔。
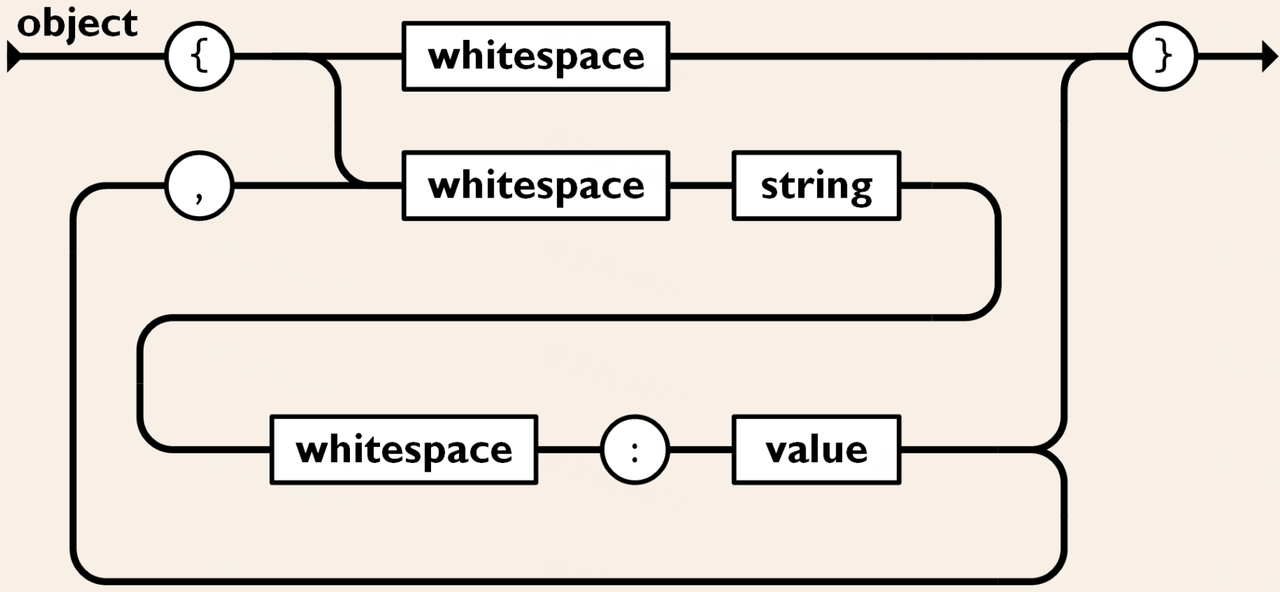
-
JSON Array
JSON Array 在 JSON 中是用于表示有序的值的集合的一种数据结构,它使用“[]”来包围元素,并且每个元素之间使用逗号“,”分隔。
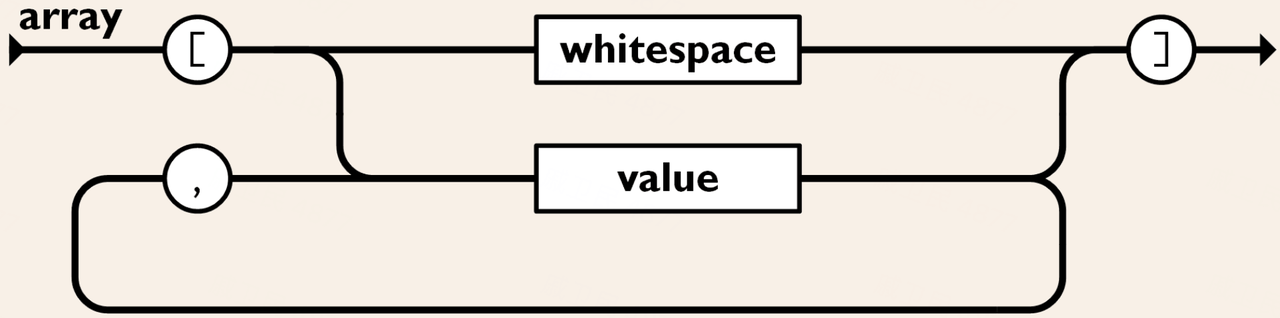
-
JSON Value
JSON Value 表示 JSON 数据的值。在 JSON 中,数据值可以是各种类型,包括数字、字符串、布尔值、数组、对象或者 null。
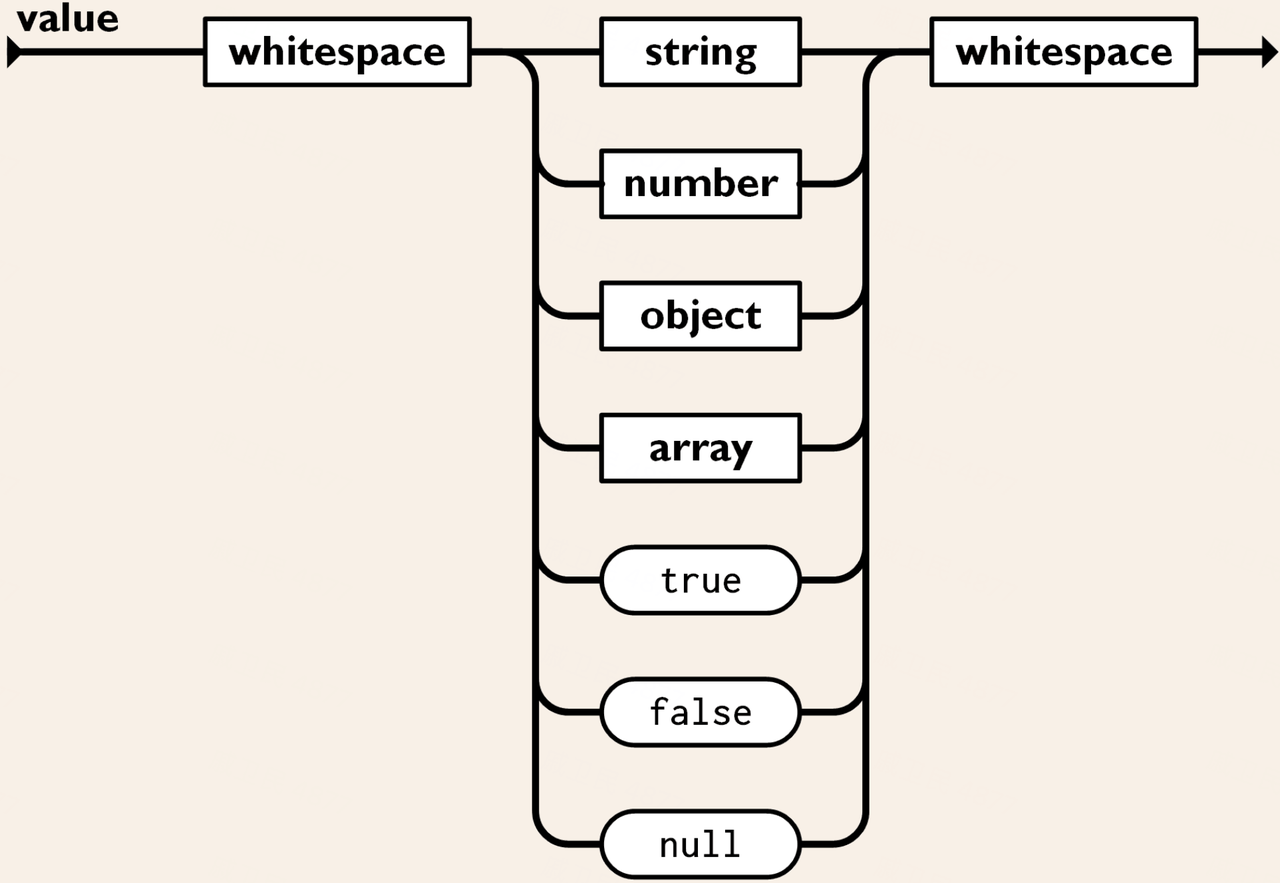
-
JSON Path
JSON Path 是一种在 JSON 对象结构中定位和提��取数据的查询语言。通过使用路径表达式,可以帮助我们轻松地在嵌套的 JSON 数据结构中定位和提取指定的数据。
符号 说明 $ 查询的根节点对象,用于表示一个 json 数据,可以是数组或对象。 .<name> 表示一个子节点。
JSON 数据类型
ArcGraph 图数据库在点和边的 Schema 设计中支持 JSON 数据类型,用于存储非结构化数据,同时扩展 JSON 字段特有的查询、存储、Index 和 JSON Function 等 JSON 特性功能。
创建 JSON 类型属性
JSON 属性可以存在于点和边之中,且可以设置 default 值,default 须为 '{}'。
创建点类型
创建包含 JSON 类型属性的点类型,语法详情请参见 创建点类型 章节。
示例
CREATE VERTEX IF NOT EXISTS person
(
PRIMARY KEY id INT(64),
name STRING COMMENT '姓名',
age INT(32) NOT NULL DEFAULT '16' COMMENT '年龄',
info JSON default '{}',
INDEX idx_info(info->>'$.name') UNIQUE,
INDEX name_index(name)
)
COMMENT = '测试Vertex';
创建边类型
创建包含 JSON 类型属性的边类型,语法详情请参见 创建边类型 章节。
示例
CREATE Edge knows
(
id INT64,
info JSON default '{}',
FROM person to person
);
管理 JSON 类型数据
使用 DML 语言管理 JSON 类型数据,执行语句时需确保 JSON 数据以字符串形式正确表达,并遵循合法的 JSON 格式规范。
新增点/边数据
新增包含 JSON 类型属性的点数据和边数据,语法详情请参见 新增数据 章节。
示例 1
新增 JSON 类型属性的点数据,命令如下:
INSERT (:person {id: 1, name: 'David', age: 43,
info:'{"name": "David", "age": 43}'});
示例 2
新增 JSON 类型属性的边数据,命令如下:
Insert (:person {id: 3})-[:knows {id: 1, info:'{"name": "David", "age": 43}'}]->(:person {id: 1});
修改点/边数据
修改点/边数据中 JSON 类型的属性,语法详情请参见 修改数据 章节。
示例 1
修改点数据中 JSON 类型的属性,命令如下:
MATCH (n: person{id: 1, name: 'David', age: 43})
SET n.info = '{"name": "Duke", "age": 42}';
示例 2
修改边数据中 JSON 类型的属性,命令如下:
MATCH (:person {id: 3})-[e:knows {id:1}]->()
SET e.info = '{"name": "David"}';
数据替换
支持对 JSON 数据中的部分 json object 进行替换,语法详情请参见 修改数据 章节。
示例 1
MATCH (n: person)
SET n.info = jsonReplace(n.info, "$.name", "Duke");
示例 2
MATCH (n: person {id: 3})-[e:knows]->(m: person)
SET e.info = jsonReplace(m.info, "$.name", "David");
JSON 函数
RETURN 子句
可以使用 RETURN 子句返回 JSON 内容的字段。
语法
语法详情请参见 RETURN 章节。
示例
MATCH (n: person)
RETURN n.info;
WHERE 子句
可以使用 WHERE 子句对 JSON 内容的字段进行条件过滤。
语法
语法详情请参见 WHERE 章节。
示例 1
MATCH (n:person)
WHERE jsonValue(n.info, "$.age") = 17
RETURN n;
示例 2
MATCH (n: person) - [e:knows] -> (x:person)
WHERE jsonValue(e.info, "$.date") = "2020-01-01"
RETURN e;
ORDER BY
可以使用 ORDER BY 子句基于 JSON 内容的字段进行排序。
语法
语法详情请参见 ORDER BY 章节。
示例
MATCH (n: person)
RETURN n.id ORDER BY jsonValue(n.info, "$.score.math");
聚合函数
��可以使用聚合函数对 JSON 数据进行统计和计算等操作。
语法
语法详情请参见 聚合函数 章节。
示例 1
MATCH (n: person)-[:knows]->(m:person)
RETURN n.id, AVG(jsonValue(m.info, "$.age")) AS avg_age;
示例 2
MATCH (n: person)-[e:knows]->(m:person)
RETURN sum(jsonValue(e.info, "$.score.math")) AS math_avg;
表达式
可以使用表达式来操作和处理 JSON 数据。
语法
语法详情请参见 计算表达式 章节。
示例
MATCH (n: person)
RETURN n.id, jsonValue(n.info, "$.score.math") + jsonValue(n.info, "$.score.english") + jsonValue(n.info, "$.score.chinese") AS total;
ST_GEOMETRY
自 ArcGraph v2.1.2 版本起,ArcGraph 图数据库新增了 ST_GEOMETRY 类型。该类型专门用于存储和处理地理空间数据,支持点(Point)、线(LineString)、多边形(Polygon)等三种地理空间对象,为构建高效、精确的地理信息系统提供了强大的支持。
坐标系统
在 ArcGraph 图数据库中,创建包含 ST_GEOMETRY 类型属性的点/边类型时,可以通过指定 SRID(Spatial Reference System Identifier,空间参考系统标识符),即地理坐标系统的 WKID(Well-Known ID)来指定地理坐标系统,以确保地理空间数据能够正确解析和展示。
ArcGraph 图数据库支持设置的坐标系统如下:
- 直角坐标系(WKID=0)
如果未指定<srid>,则默认为 0,表示使用直角坐标系,适用于无需地理坐标系统的简单应用场景。 - WGS84 (WKID=4326)
WGS84(World Geodetic System 1984)是美国 GPS 使用的一套全球地理坐标系统,应用于 OpenStreetMap (OSM) 地图、Google Maps 国际版、Landsat 卫星影像图等地理信息系统中。许多开发地图的 API 默认采用 WGS84 作为其坐标系统。 - CGCS2000 (WKID=4490)
CGCS2000(China Geodetic Coordinate System 2000)中国国家2000地理坐标系统是中国使用的一套地理坐标系统,主要应用于中国的北斗导航系统以及国家级地理信息服务平台“天地图”中。
创建点类型
创建包含 ST_GEOMETRY 类型属性的点类型,语法详情请参见 创建点类型 章节。
语法
create_vertex ::= CREATE VERTEX [IF NOT EXISTS] <vertex_name>
( <property_name> ST_GEOMETRY[(<srid>)][, <vertex_body>]... )
[ COMMENT = < string > ];
详细说明
[(<srid>)]:(可选)用于设置地理坐标系统的 WKID(Well-Known ID)值,表示构建地理空间对象时所采用的地理坐标系统。支持的 <srid> 值包括“0”(如果未设置,则默认为 0,表示直角坐标系)、“4326”(WGS 84 坐标系)以及“4490”(CGCS2000 坐标系)。
示例
在当前图中创建一个名为 location 的点类型,包含 id 和 ST_GEOMETRY 类型的 position 属性,并指定 <srid> 为 4326(WGS84)。命令如下:
CREATE VERTEX location (
PRIMARY KEY id INT(64),
position ST_GEOMETRY(4326)
)
COMMENT = '测试Vertex';
创建边类型
创建包含 ST_GEOMETRY 类型属性的边类型,语法详情请参见 创建边类型 章节。
语法
create_edge ::= CREATE [TEMPORAL] EDGE [IF NOT EXISTS] <edge_name>
( <property_name> ST_GEOMETRY[(<srid>)] [, <edge_body>]...)
[ COMMENT = < string > ];
详细说明
[(<srid>)]:(可选)用于设置地理坐标系统的 WKID(Well-Known ID)值,表示构建地理空间对象时所采用的地理坐标系统。支持的 <srid> 值包括“0”(如果未设置,则默认为 0,表示直角坐标系)、“4326”(WGS 84 坐标系)以及“4490”(CGCS2000 坐标系)。
边类型及其所连接的点类型应当采用相同的坐标系,以确保地理空间数据的一致性和准确性。
示例
在当前图中创建一个名为 Route 的边类型,包含 ST_GEOMETRY 类型的 path 属性,并指定 <srid> 为 4326(WGS84)。命令如下:
CREATE EDGE Route (
path ST_GEOMETRY(4326),
FROM location TO location
)
COMMENT = '表示两个地点之间的路线';
新增数据
在 ArcGraph 图数据库中,新增包含 ST_GEOMETRY 类型属性的��点/边数据,语法详情请参见 新增数据 章节,支持通过 GeoJSON 或 WKT(Well-Known Text)格式定义地理空间对象。
通过 GeoJSON 格式新增数据
GeoJSON 是一种基于 JSON 的格式,用于表示各种地理数据结构。新增数据时,需明确指定 type 和 coordinates 字段。
type:定义地理空间对象类型,支持设置Point(点)、LineString(线)或Polygon(多边形)三种类型。coordinates:定义地理空间对象的坐标信息,支持 Double、Integer 数据类型。
示例 1
在当前图中,通过 GeoJSON 格式新增 ST_GEOMETRY 类型属性的点数据。命令如下:
# 新增点(Point)
INSERT (:location {id: 1, position: '{"type": "Point", "coordinates": [7.428959, 1.513394]}'});
# 新增线(LineString)
INSERT (:location {id: 2, position: '{"type": "LineString", "coordinates": [[-1, -1], [1, -1]]}'});
# 新增多边形(Polygon)
INSERT (:location {id: 3, position: '{"type": "Polygon", "coordinates": [[[1.1, 1.1], [2.1, 1.1], [1.1, 3.1], [2.1, 3.1], [1.1, 1.1]]]}'});
示例 2
在当前图中,通过 GeoJSON 格式新增 ST_GEOMETRY 类型属性的边数据。命令如下:
INSERT (a:location {id:1})-[:Route {path:'{"type": "Point","coordinates":[1.0,1.0]}'}]->(b:location {id:2});
通过 WKT 格式新增数据
WKT(Well-Known Text)是一种用于描述地理空间几何对象的文本格式��。
示例 1
在当前图中,通过 WKT 格式新增 ST_GEOMETRY 类型属性的点数据。命令如下:
# 新增点(Point)
INSERT (:location {id: 5, position: 'Point(7.428959 1.513394)'});
# 新增线(LineString)
INSERT (:location {id: 6, position: 'LineString(116.407526 39.904030, 116.407526 39.904031)'});
# 新增多边形(Polygon)
INSERT (:location {id: 7, position: 'Polygon((116.4 39.9, 116.4 39.95, 116.5 39.95, 116.5 39.9, 116.4 39.9))'});
示例 2
在当前图中,通过 WKT 格式新增 ST_GEOMETRY 类型属性的边数据。命令如下:
INSERT (a:location {id:2})-[:Route {path:'LINESTRING(116.407526 39.904030, 116.407526 39.904031)'}]->(b:location {id:3});
相关操作
- 点类型管理:更多关于点类型的创建、修改和删除等操作,请参见 点类型 章节。
- 边类型管理:更多关于边类型的创建、修改和删除等操作,请参见 边类型 章节。
- 数据管理:更多关于点/边数据的增、删、改等操作,请参见 DML(增 | 删 | 改) 章节。
- Geo 函数:关于地理空间数据的关系判断、距离计算等操作,请参见 Geo 函数 章节。
事务
在图数据库中,事务是一组操作的逻辑单元,这些操作要么全部成功执行,要么全部回滚。事务确保了图数据库中数据的一致性和可靠性。
事务具有如下特性:
-
原子性(Atomicity):事务中的操作要么全部成功执行,要么全部回滚,不会出现部分操作成功部分操作失败的情况。
-
一致性(Consistency):事��务执行前后,数据库必须保持一致状态。事务的操作应该遵循定义的约束和规则,以确保数据的完整性。
-
隔离性(Isolation):事务应该是相互隔离的,即一个事务的操作不应该被其他事务所干扰。每个事务应该感知到其他事务对数据库所做的更改,隔离级别可以通过设置来控制。
-
持久性(Durability):一旦事务成功提交,对数据库的更改应该永久保存,即使在系统故障或重启之后也能恢复。
开启事务
开启事务可以确保一系列相关的操作要么都成功执行,要么都不执行,从而保证操作的一致性和完整性,确保数据库的正确性。
使用 START TRANSACTION 语句显式地开启一个事务。
示例
START TRANSACTION;
详细说明
- 开启事务时,如果当前会话已经有活跃的事务,则会返回“Transactions cannot be nested”信息,表示事务操作失败,不允许嵌套事务。
- 显式地开启事务后,DML 语句不会自动提交到数据库,而是需要客户端显式发送
Commit提交或Rollback回滚来结束事务。
提交事务
显式地提交当前已开启的活跃事务。
示例
COMMIT;
详细说明
- 如果当前会话中没有活跃事务,则返回“No active transaction to commit”信息,否则执行提交当前事务的操作。
- 显式提交当前事务后,清空当前会话中的的当前事务。
- 如果当前存在活跃事务,仍坚持提交 DDL 操作,则会直接提交当前事务。
回滚事务
显式地回滚事务。
示例
ROLLBACK;
详细说明
- 如果当前会话中没有活跃事务,则返回“No active transaction to rollback”信息,否则执行回滚当前事务的操作。
- 显式地回滚当前事务后,清空当前会话中的的当前事务。
隔离级别设置
设置当前会话范围内的隔离级别。
示例 1
将当前会话的隔离级别设置为“RR”级别。
SET ISOLATION LEVEL REPEATABLE READ;
示例2
将当前会话的隔离级别设置为“RC”级别。
SET ISOLATION LEVEL READ COMMITTED;
详细说明
- 如果当前会话中已经存在活跃的事务,则无法更改事务的隔离级别,并返回一个失败信息。
- 隔离级别目前只支持 RR(Repeatable Read,可重复读)和 RC(Read Committed,读取已提交),默认隔离级别为 RC ,作用范围为当前会话中。在无修改的情况下,所有该会话下开启的事务都采用相同的隔离级别。
Show 命令
SHOW CHARSETS
在 ArcGraph 图数据库中可使用 SHOW CHARSETS 语句查看目前系统支持的字符集,更多关于字符集的详细说明请参见 字符集和排序规则 章节。
语法
SHOW CHARSETS;
示例
查看当前系统支持的字符集,命令如下:
SHOW CHARSETS;
返回结果示例如下:
+----+--------------+---------------------------------+--------------------+
| id | charset_name | charset_desc | default_collation |
+====+==============+=================================+====================+
| 0 | gb18030 | China National Standard GB18030 | gb18030_chinese_ci |
+----+--------------+---------------------------------+--------------------+
| 1 | gbk | GBK Simplified Chinese | gbk_chinese_ci |
+----+--------------+---------------------------------+--------------------+
| 2 | utf8 | UTF-8 Unicode | utf8_bin |
+----+--------------+---------------------------------+--------------------+
SHOW COLLATIONS
在 ArcGraph 图数据库中可使用 SHOW COLLATIONS 语句查看字符集的排序规则及其对应的字符集,更多关于字符集排序规则的详细说��明请参见 字符集和排序规则 章节。
语法
SHOW COLLATIONS;
示例
查看当前系统支持的字符集排序规则及其对应的字符集,命令如下:
SHOW COLLATIONS;
返回结果示例如下:
+----+--------------------+---------+
| id | collation_name | charset |
+====+====================+=========+
| 0 | gb18030_bin | gb18030 |
+----+--------------------+---------+
| 1 | gb18030_chinese_ci | gb18030 |
+----+--------------------+---------+
| 2 | gbk_bin | gbk |
+----+--------------------+---------+
| 3 | gbk_chinese_ci | gbk |
+----+--------------------+---------+
| 4 | utf8_bin | utf8 |
+----+--------------------+---------+
| 5 | utf8_pinyin | utf8 |
+----+--------------------+---------+
SHOW CONFIGS
在 ArcGraph 图数据库中使用 SHOW CONFIGS 语句查看系统配置信息,并根据实际情况使用 ALTER CONFIG 语句修改系统配置,详情请参见 更改系统配置 章节。
语法
SHOW [FULL] CONFIGS [LIKE <"key">] [[WHERE] SERVER= <server_id>]
详细说明
| 参数 | 说明 |
|---|---|
[LIKE <"key">] | (可选)用于指定关键字并按关键字过滤查询结果。如果未指定关键字,则返回所有配置。 |
[[WHERE] SERVER= <server_id>] | (可选)指定要查询的服务器 ID。如果未指定,则返回集群中所有服务器的配置。 |
[FULL] | (可选)表示显示完整信息。如果省略,将只显示基本信息。 说明: 仅 ArcGraph >= v2.1.1 版本支持此参数。 |
结果说明
| 参数 | 说明 |
|---|---|
config_name | 配置的名称。 |
value | 当前配置的值。 |
modify_level | 配置的更改等级,包括 STATIC 和 DYNAMIC 两种类型。- STATIC:STATIC 等级的配置项仅支持通过编辑配置文件进行修改,不支持其他方式调整。- DYNAMIC:DYNAMIC 等级的配置项可以通过动态指令(如 ALTER)修改。 |
default_value | 配置的默认值。 |
max | 配置允许设置的最大值。 |
min | 配置允许设置的最小值。 |
save_flag | 用于设定是否保留配置的变更记录。 - true:若将此参数设置为 true,则 ArcGraph 会将该配置的变更持久化保存到系统配置文件(“system config file”)中,以确保配置信息在重启或系统恢复时得以保留。- false:若将此参数设置为 false,则不保存变更记录。说明: 仅 ArcGraph >= v2.1.1 版本支持此参数。 |
server_id | 配置所在的服务器 ID。 |
server_address | 配置所在的服务器 IP 地址。 |
describe | 配置的描述信息。 |
示例 1
查询集群下所有服务器系统配置的基本信息,命令如下:
SHOW CONFIGS;
示例 2
查询集群下服务器 ID 为“1”,且含有 %key% 关键字的系统配置的基本信息,命令如下:
SHOW CONFIGS LIKE "%key%" WHERE SERVER =1;
返回结果示例如下:
+-----------------------------+-------+--------------+-----------+--------------------------------+
| config_name | value | modify_level | server_id | description |
+=============================+=======+==============+===========+================================+
| security_magic_key | | STATIC | 1 | use to encrypt user's password |
+-----------------------------+-------+--------------+-----------+--------------------------------+
| store_delete_key_batch_size | 5000 | STATIC | 1 | store delete key batch size |
+-----------------------------+-------+--------------+-----------+--------------------------------+
示例 3
查询集群下服务器 ID 为“1”,且且含有 %key% 关键字的系统配置的详细信息,命令如下:
SHOW FULL CONFIGS LIKE "%key%" WHERE SERVER =1;
返回结果示例如下:
+-----------------------------+-------+--------------+---------------+---------------------+------+-----------+-----------+-----------------+--------------------------------+
| config_name | value | modify_level | default_value | max | min | save_flag | server_id | server_address | description |
+=============================+=======+==============+===============+=====================+======+===========+===========+=================+================================+
| security_magic_key | | STATIC | | None | None | false | 1 | 127.0.0.1:50051 | use to encrypt user's password |
+-----------------------------+-------+--------------+---------------+---------------------+------+-----------+-----------+-----------------+--------------------------------+
| store_delete_key_batch_size | 5000 | STATIC | 5000 | 9223372036854775807 | 0 | false | 1 | 127.0.0.1:50051 | store delete key batch size |
+-----------------------------+-------+--------------+---------------+---------------------+------+-----------+-----------+-----------------+--------------------------------+
SHOW CREATE
在 ArcGraph 图数据库中可使用 SHOW CREATE 语句查看图、点类型或边类型的创建语句,这有助于用户了解现有图、点类型和边类型的定义,或复制创建语句至其他环境。请注意,仅 ArcGraph >= v2.1.1 版本支持此功能。
前提条件
- 请确保指定的图、点类型或边类型必须在 ArcGraph 图数据库中已存在。如果对象不存在,系统将报错。
- 请在指定的图中查看点类型和边类型的创建语句,如果图 ID 为“0”,即未在图中查看,则系统将报错。
查看图的创建语句
语法
SHOW CREATE GRAPH <graphName>
详细说明
<graphName>:用于指定将要查看的图名称。
示例
查看图“new1”的创建语句,命令如下:
SHOW CREATE GRAPH new1;
返回结果示例如下:
+------------+-------------------------------------------------------------------------------------------------------------+
| graph_name | create_statement |
+============+=============================================================================================================+
| new1 | CREATE GRAPH IF NOT EXISTS new1 ( PARTITION_NUM = 1 ) CHARSET = utf8 COLLATION = utf8_bin COMMENT = '新图' |
+------------+-------------------------------------------------------------------------------------------------------------+
查看点类型的创建语句
语法
SHOW CREATE VERTEX <vertexName>
详细说明
<vertexName>:用于指定将要查看的点类型名称。
示例
在当前图中查看点类型“person”的创建语句,命令如下:
SHOW CREATE VERTEX person;
返回结果示例如下:
+------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------+
| graph_name | create_statement |
+============+=================================================================================================================================================================+
| new1 | CREATE VERTEX IF NOT EXISTS person(PRIMARY KEY id INT64,name STRING NULL COMMENT '姓名',age INT32 NOT NULL DEFAULT 16 COMMENT '年龄') PARTITION BY HASH (_TYPE) |
+------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------+
查看边类型的创建语句
语法
SHOW CREATE EDGE <edgeName>
详细说明
<edgeName>:用于指定将要查看的边类型名称。
示例
在当前图中查看边类型“knows”的创建语句,命令如下:
SHOW CREATE EDGE knows;
返回结果示例如下:
+------------+----------------------------------------------------------------------------------+
| graph_name | create_statement |
+============+==================================================================================+
| new1 | CREATE EDGE IF NOT EXISTS knows (creationDate STRING NULL,FROM person TO person) |
+------------+----------------------------------------------------------------------------------+
SHOW EDGES
本章节将详细介绍在 ArcGraph 图数据库中如何使用 SHOW EDGES 及相关语句查看边类型相关信息。
查看边类型
使用SHOW EDGES 命令查看当前图中所有的边类型。
语法
SHOW [FULL] EDGES;
详细说明
| 参数 | 说明 |
|---|---|
[FULL] | (可选)用于展示边类型的详细信息。如果省略,将只展示边类型名称。 说明: 仅 ArcGraph >= v2.1.1 版本支持此参数。 |
结果说明
| 参数 | 说明 |
|---|---|
edge_type_name | 边类型名称。 自 ArcGraph v2.1.2 版本起,执行 SHOW FULL EDGES; 命令时可以查看已删除但未回收的边类型。这些边类型的 ID 不变,但名字会被定义为 _{name}_{timestamp} 格式,如 _like_1724929319723310。 |
edge_type_id | 边类型的唯一标识符,用于区分不同的边类型。 |
vertex_pairs | 边类型连接的起点类型和终点类型的详细信息。 |
status | 边类型的状态,支持以下三种状态:
|
data_version | 边类型的数据版本号,用于记录边类型的数据变更历史。 |
schema_version | 边类型的 Schema 版本号,用于记录边类型的 Schema 变更历史。 |
示例 1
在当前图中查看所有边类型,命令如下:
SHOW EDGES;
返回结果示例如下:
+----------------+
| edge_type_name |
+================+
| like |
+----------------+
示例 2
在当前图中查看所有边类型的详细信息,命令如下:
SHOW FULL EDGES;
返回结果示例如下:
+----------------+--------------+----------------------+--------+--------------+----------------+
| edge_type_name | edge_type_id | vertex_pairs | status | data_version | schema_version |
+================+==============+======================+========+==============+================+
| like | 4 | [VertexTypePair { | Normal | 0 | 0 |
| | | from_id: 1, | | | |
| | | to_id: 1, | | | |
| | | status: Normal, | | | |
| | | from_name: Some( | | | |
| | | "person", | | | |
| | | ), | | | |
| | | to_name: Some( | | | |
| | | "person", | | | |
| | | ), | | | |
| | | }] | | | |
+----------------+--------------+----------------------+--------+--------------+----------------+
示例 3
当 ArcGraph >= v2.1.2 版本时,在当前图中查看所有边类型的详细信息,包括已删除但未回收的边类型。命令如下:
SHOW FULL EDGES;
返回结果示例如下:
+------------------------+--------------+----------------------+---------+--------------+----------------+
| edge_type_name | edge_type_id | vertex_pairs | status | data_version | schema_version |
+========================+==============+======================+=========+==============+================+
| _like_1724929319723310 | 4096 | [VertexTypePair { | Deleted | 0 | 1 |
| | | from_id: 1, | | | |
| | | to_id: 1, | | | |
| | | status: Deleted, | | | |
| | | from_name: Some( | | | |
| | | "person", | | | |
| | | ), | | | |
| | | to_name: Some( | | | |
| | | "person", | | | |
| | | ), | | | |
| | | }] | | | |
+------------------------+--------------+----------------------+---------+--------------+----------------+
| knows | 4097 | [VertexTypePair { | Normal | 0 | 0 |
| | | from_id: 1, | | | |
| | | to_id: 1, | | | |
| | | status: Normal, | | | |
| | | from_name: Some( | | | |
| | | "person", | | | |
| | | ), | | | |
| | | to_name: Some( | | | |
| | | "person", | | | |
| | | ), | | | |
| | | }] | | | |
+------------------------+--------------+----------------------+---------+--------------+----------------+
SHOW GRAPHS
本章节将详细介绍在 ArcGraph 图数据库中如何使用 SHOW GRAPHS 及相关语句查看图相关信息,以便更好地管理和分析图数据。
查看当前图
使用 SHOW CURRENT GRAPH 命令查看当前正在使用的图。如果当前没使用任何图则返回结果为:graph_id =0,graph_name =None。
语法
SHOW CURRENT GRAPH;
示例
查看用户当前使用的图,命令如下:
SHOW CURRENT GRAPH;
查看所有/指定图
使用 SHOW GRAPHS 命令查看系统中的图。
语法
SHOW [FULL] GRAPHS [LIKE '<graph_name>'];
详细说明
| 参数 | 说明 |
|---|---|
[FULL] | (可选)用于展示图的详细信息,包括名称、ID、状态以及创建时间等。如果省略,将只展示图名称。 说明: 仅 ArcGraph >= v2.1.1 版本支持此参数。 |
[LIKE '<graph_name>'] | (可选)用于指定关键字('<graph_name>')并按关键字过滤查询结果。如果省略,将展示所有图。说明: 仅 ArcGraph >= v2.1.1 版本支持此参数。 |
'<graph_name>' | 图名称,用于指定将要操作的图的名称。 |
结果说明
| 参数 | 说明 |
|---|---|
graph_name | 图名称。 自 ArcGraph v2.1.2 版本起,通过执行 SHOW FULL GRAPHS; 命令可查看已删除但未回收的图。这些图的 ID 不变,但名字会被定义为 _{name}_{timestamp} 格式,如 _new1_1724929262231783。 |
graph_id | 图的唯一标识符,用于区分不同的图。 |
status | 图的状态,支持以下三种状态:
|
create_time | 图的创建时间(默认使用 UTC 时间)。 |
示例 1
查看系统中所有的图,命令如下:
SHOW GRAPHS;
返回结果示例如下:
+---------------------+
| graph_name |
+=====================+
| _SYSTEM |
+---------------------+
| _SYSTEM_INFORMATION |
+---------------------+
| new1 |
+---------------------+
示例 2
查看系统中“new1”图。命令如下:
SHOW GRAPHS LIKE 'new1';
返回结果示例如下:
+------------+
| graph_name |
+============+
| new1 |
+------------+
示例 3
查看系统中“new1”图的详细信息。命令如下:
SHOW FULL GRAPHS LIKE 'new1';
返回结果示例如下:
+------------+----------+--------+-------------------------+
| graph_name | graph_id | status | create_time |
+============+==========+========+=========================+
| new1 | 1025 | Normal | 2024-03-26 06:47:20.675 |
+------------+----------+--------+-------------------------+
示例 4
当 ArcGraph >= v2.1.2 版本时,在当前系统中查看所有图的详细信息,包括已删除但未回收的图。命令如下:
SHOW FULL EDGES;
返回结果示例如下:
+------------------------+----------+---------+-------------------------+
| graph_name | graph_id | status | create_time |
+========================+==========+=========+=========================+
| _SYSTEM | 1 | Normal | 2024-08-28 11:15:11.776 |
+------------------------+----------+---------+-------------------------+
| _SYSTEM_INFORMATION | 3 | Normal | 2024-08-28 11:15:11.776 |
+------------------------+----------+---------+-------------------------+
| _LOCAL_STORE | 4 | Normal | 2024-08-28 11:15:11.776 |
+------------------------+----------+---------+-------------------------+
| _new1_1724929262231783 | 1026 | Deleted | 2024-08-29 03:12:11.494 |
+------------------------+----------+---------+-------------------------+
| new1 | 1027 | Normal | 2024-08-29 11:01:11.084 |
+------------------------+----------+---------+-------------------------+
查看图缓存状态
自 ArcGraph v2.1.2 版本起,ArcGraph 图数据库支持使用 SHOW GRAPHS LOAD STATUS 语句查看系统中图的缓存状态。
语法
SHOW GRAPHS LOAD STATUS [LIKE '<graph_name>'];
详细说明
| 参数 | 说明 |
|---|---|
[LIKE '<graph_name>'] | (可选)用于指定关键字('<graph_name>')并按关键字过滤查询结果。如果省略,将展示所有图。 |
'<graph_name>' | 图名称,用于指定将要操作的图的名称。 |
结果说明
| 参数 | 说明 |
|---|---|
graph_name | 图名称。 |
graph_id | 图的唯一标识符,用于区分不同的图。 |
load_status | 图的加载状态,包括: - Loaded:表示拓扑数据已经全部加载到内存中。- Unloaded:表示拓扑数据未加载到内存中。- Loading:表示正在加载拓扑数据到内存中。 |
topology_enabled | 表示当前图的拓扑缓存是否处于启用状态。如果启用,则图的拓扑结构信息将被缓存,可以提高查询性能。 |
property_enabled | 表示当前图的属性缓存是否处于启用状态。如果启用,则图的属性信息将被缓存,可以加快查询速度。 |
示例 1
查看系统中所有图的缓存状态。命令如下:
SHOW GRAPHS LOAD STATUS;
返回结果示例如下:
+---------------------+----------+-------------+------------------+------------------+
| graph_name | graph_id | load_status | topology_enabled | property_enabled |
+=====================+==========+=============+==================+==================+
| ARC_GRAPH_TEST | 1026 | Loaded | true | true |
+---------------------+----------+-------------+------------------+------------------+
| _SYSTEM | 1 | Loaded | true | true |
+---------------------+----------+-------------+------------------+------------------+
| _SYSTEM_INFORMATION | 3 | Loaded | true | true |
+---------------------+----------+-------------+------------------+------------------+
| new1 | 1025 | Loaded | true | true |
+---------------------+----------+-------------+------------------+------------------+
示例 2
查看系统中“ARC_GRAPH_TEST”图的缓存状态。命令如下:
SHOW GRAPHS LOAD STATUS LIKE 'ARC_GRAPH_TEST';
返回结果示例如下:
+----------------+----------+-------------+------------------+------------------+
| graph_name | graph_id | load_status | topology_enabled | property_enabled |
+================+==========+=============+==================+==================+
| ARC_GRAPH_TEST | 1026 | Loaded | true | true |
+----------------+----------+-------------+------------------+------------------+
查看图统计信息
自 ArcGraph v2.1.2 版本起,ArcGraph 图数据库支持使用 SHOW GRAPHS STATISTICS 语句查看系统中图的统计信息。这一语句在保持与 SHOW GRAPHS STAT 语句相同的功能和显示格式的同时,为用户提供了语法上的多样性选择,本章节仅介绍 SHOW GRAPHS STATISTICS 语句的基本操作,更多操作详情请参考 SHOW STATS 章节。
语法
SHOW GRAPHS STATISTICS;
示例
查看系统中所有图的统计信息。命令如下:
SHOW GRAPHS STATISTICS;
返回结果示例如下:
+----------------+-------------------+----------------+--------------+-----------+-------------------------+
| graph_name | vertexes_type_num | edges_type_num | vertexes_num | edges_num | update_time |
+================+===================+================+==============+===========+=========================+
| ARC_GRAPH_TEST | 6 | 8 | 326 | 491 | 2024-05-31 07:34:39.034 |
+----------------+-------------------+----------------+--------------+-----------+-------------------------+
| new1 | 0 | 0 | 0 | 0 | 2024-05-31 07:51:20.366 |
+----------------+-------------------+----------------+--------------+-----------+-------------------------+
查看图缓存信息
自 ArcGraph v2.1.2 版本起,ArcGraph 图数据库支持使用 SHOW GRAPHS CACHE 语句查看系统内存中缓存的图(包括点和边等)的内存信息。
语法
SHOW GRAPHS CACHE [LIKE '<graph_name>'];
详细说明
| 参数 | 说明 |
|---|---|
[LIKE <'graph_name'>] | (可选)用于指定关键字('<graph_name>')并按关键字过滤查询结果。如果省略,将展示所有图。 |
'<graph_name>' | 图名称,用于指定将要操作的图的名称。 |
结果说明
| 参数 | 说明 |
|---|---|
server_id | 服务器节点的唯一标识符。 |
graph_name | 图名称。 |
vertexes_num | 当前图缓存的点的总数。 |
edges_num | 当前图缓存的边的总数(包含正向边和反向边)。 |
dirty_vertexes_num | 当前图缓存中被标记为修改(dirty)的点的总数。这些点可能在内存中已被修改但尚未持久化到磁盘。 |
dirty_edges_num | 当前图缓存中被标记为修改(dirty)的边的总数。这些边可能在内存中已被修改但尚未持久化到磁盘。 |
示例 1
查询系统中所有图的缓存信息,包括点、边等的内存信息。命令如下:
SHOW GRAPHS CACHE;
返回结果示例如下:
+-----------+---------------------+--------------+-----------+--------------------+-----------------+
| server_id | graph_name | vertexes_num | edges_num | dirty_vertexes_num | dirty_edges_num |
+===========+=====================+==============+===========+====================+=================+
| 1 | ARC_GRAPH_TEST | 326 | 982 | 0 | 210 |
+-----------+---------------------+--------------+-----------+--------------------+-----------------+
| 1 | _SYSTEM | 46 | 0 | 7 | 0 |
+-----------+---------------------+--------------+-----------+--------------------+-----------------+
| 1 | _SYSTEM_INFORMATION | 0 | 0 | 0 | 0 |
+-----------+---------------------+--------------+-----------+--------------------+-----------------+
| 1 | new1 | 0 | 0 | 0 | 0 |
+-----------+---------------------+--------------+-----------+--------------------+-----------------+
示例 2
查询系统中“ARC_GRAPH_TEST”图的缓存信息,包括点、边等的内存信息。命令如下:
SHOW GRAPHS CACHE LIKE 'ARC_GRAPH_TEST';
返回结果示例如下:
+-----------+----------------+--------------+-----------+--------------------+-----------------+
| server_id | graph_name | vertexes_num | edges_num | dirty_vertexes_num | dirty_edges_num |
+===========+================+==============+===========+====================+=================+
| 1 | ARC_GRAPH_TEST | 326 | 982 | 0 | 210 |
+-----------+----------------+--------------+-----------+--------------------+-----------------+
查看点度数分布情况
自 ArcGraph v2.1.2 版本起,ArcGraph 图数据库支持使用 SHOW GRAPH <graph_name> DEGREES 语句查看指定图中点的度数分布情况。此操作将统计图中所有点的度数,并按照度数分组,统计每个度数对应的点数量。结果将以表格形式展示,其中每一行代表一个不同的度数和对应的点数量。
语法
SHOW GRAPH <graph_name> DEGREES;
详细说明
| 参数 | 说明 |
|---|---|
<graph_name> | 图名称,用于指定将要操作的图的名称。 |
结果说明
| 参数 | 说明 |
|---|---|
degree | 点的度数(包含出度和入度)。 |
count | 度数为 degree 的点的数量。 |
示例
查询“ARC_GRAPH_TEST”图中点的度数分布情况。命令如下:
SHOW GRAPH ARC_GRAPH_TEST DEGREES;
返回结果示例如下:
+--------+-------+
| degree | count |
+========+=======+
| 1 | 47 |
+--------+-------+
| 2 | 212 |
+--------+-------+
| 3 | 15 |
+--------+-------+
| 4 | 10 |
+--------+-------+
| 5 | 6 |
+--------+-------+
| 6 | 11 |
+--------+-------+
| 7 | 4 |
+--------+-------+
| 8 | 3 |
+--------+-------+
| 9 | 5 |
+--------+-------+
| 10 | 1 |
+--------+-------+
| 11 | 4 |
+--------+-------+
| 12 | 1 |
+--------+-------+
| 14 | 1 |
+--------+-------+
| 16 | 1 |
+--------+-------+
| 18 | 1 |
+--------+-------+
| 23 | 1 |
+--------+-------+
| 26 | 1 |
+--------+-------+
| 30 | 1 |
+--------+-------+
| 40 | 1 |
+--------+-------+
SHOW INDEXES
本章节将详细介绍在 ArcGraph 图数据库中如何使用 SHOW INDEXES 及相关语句查看索引相关信息。
查看索引
查看当前图中点类型或边类型的索引。
语法
show_indexes ::= SHOW [FULL] {VERTEX|EDGE} INDEXES;
详细说明
| 参数 | 说明 |
|---|---|
[FULL] | (可选)用于展示索引的详细信息。若省略,则只展示该索引的基本信息。 说明: 仅 ArcGraph >= v2.1.1 版本支持此参数。 |
结果说明
| 参数 | 说明 |
|---|---|
index_name | 索引名称。 自 ArcGraph v2.1.2 版本起,通过执行 SHOW FULL {VERTEX|EDGE} INDEXES; 命令可以查看已删除但未回收的索引。这些索引的 ID 不变,但名字会被定义为 _{name}_{timestamp} 格式,如 _idx_person_1724931030554177。 |
index_id | 索引的唯一标识符,用于区分不同的索引。 |
based_type_name | 索引构建所依据的点或边类型名称。 |
based_type_id | 索引构建所依据的点或边类型的 ID。 |
status | 索引的状态,支持以下三种状态:
|
unique | 表示索引是否唯一,支持以下两种情况:
|
primary | 表示索引是否为主键索引。支持以下两种情况:
|
job_id | 与索引操作相关的作业 ID。执行 Create index 命令后, ArcGraph 图数据库服务器的后台会生成一个异步创建索引的任务(通常称为 Job)如果 job_id 为空,则表示已完成索引创建工作。说明: 仅 ArcGraph >= v2.1.2 版本支持此参数。 |
示例 1
在当前图中查看所有点类型的索引,命令如下:
SHOW VERTEX INDEXES;
返回结果示例如下:
+-----------------+-----------------+
| index_name | based_type_name |
+=================+=================+
| name_index | person |
+-----------------+-----------------+
| person_pk_index | person |
+-----------------+-----------------+
示例 2
在当前图中查看所有点类型索引的详细信息,命令如下:
SHOW FULL VERTEX INDEXES;
返回结果示例如下:
+-----------------+----------+-----------------+---------------+--------+--------+---------+
| index_name | index_id | based_type_name | based_type_id | status | unique | primary |
+=================+==========+=================+===============+========+========+=========+
| name_index | 3 | person | 1 | Ready | true | false |
+-----------------+----------+-----------------+---------------+--------+--------+---------+
| person_pk_index | 2 | person | 1 | Ready | true | true |
+-----------------+----------+-----------------+---------------+--------+--------+---------+
示例 3
在当前图中查看所有边类型的索引,命令如下:
SHOW EDGE INDEXES;
返回结果示例如下:
+------------+-----------------+
| index_name | based_type_name |
+============+=================+
| index_a | like |
+------------+-----------------+
示例 4
当 ArcGraph >= v2.1.2 版本时,在当前图中查看所有索引的详细信息,包括已删除但未回收的索引。命令如下:
SHOW FULL VERTEX INDEXES;
返回结果示例如下:
+------------------------------+----------+-----------------+---------------+---------+--------+---------+--------+
| index_name | index_id | based_type_name | based_type_id | status | unique | primary | job_id |
+==============================+==========+=================+===============+=========+========+=========+========+
| _idx_person_1724931030554177 | 4 | person | 1 | Deleted | false | false | |
+------------------------------+----------+-----------------+---------------+---------+--------+---------+--------+
| name_index | 2 | person | 1 | Ready | true | false | |
+------------------------------+----------+-----------------+---------------+---------+--------+---------+--------+
| person_pk_index | 1 | person | 1 | Ready | true | true | |
+------------------------------+----------+-----------------+---------------+---------+--------+---------+--------+
查看索引状态
查看当前图中索引的状态。
语法
show_index_status ::= SHOW {VERTEX|EDGE} {INDEXES | INDEX <index_name>} STATUS;
详细说明
| 参数 | 说明 |
|---|---|
<index_name> | 索引名称,用于指定将要操作的索引的名称。 |
示例 1
在当前图中查看点类型中“name_index”索引的状态,命令如下:
SHOW VERTEX INDEX name_index STATUS;
返回结果示例如下:
+------------+--------+
| index_name | status |
+============+========+
| name_index | Ready |
+------------+--------+
示例 2
在当前图中查看边类型中“index_a”索引的状态,命令如下:
SHOW EDGE INDEX index_a STATUS;
返回结果示例如下:
+------------+--------+
| index_name | status |
+============+========+
| index_a | Ready |
+------------+--------+
示例 3
在当前图中查看边类型中所有索引的状态,命令如下:
SHOW EDGE INDEXES STATUS;
返回结果示例如下:
+------------+--------+
| index_name | status |
+============+========+
| index_a | Ready |
+------------+--------+
SHOW JOBS
在图数据库中,后台作业(Background Jobs)是指系统自动执行、无需用户直接交互的关键任务,这些任务通常与数据库的管理、维护、优化或数据处理等操作相关。
从 ArcGraph v2.1.2 版本开始,ArcGraph 图数据库增强了管理功能,允许用户通过 SHOW JOBS 语句获取后台作业的状态和详尽信息。请注意,SHOW JOBS 语句仅支持在 Leader 服务器节点上执行,用户可通过执行 SHOW SERVERS 命令来快速查看各服务器的角色分配情况,详情请参考 SHOW SERVERS 章节。
语法
SHOW JOBS [<job_id>];
详细说明
| 参数 | 说明 |
|---|---|
[<job_id>] | (可选)用于指定要查询的后台作业 ID。如果未指定,则返回整个集群的所有后台作业的信息。 |
结果说明
| 参数 | 说明 |
|---|---|
job_id | 后台作业的唯一标识符,用于区分不同的后台作业。 |
graph_id | 图的唯一标识符,表示该后台作业正在对该图进行操作。 |
job_type | 后台作业的类型,包括: - DropEdgeType:删除边类型。- DropVertexType:删除点类型。- DropPairs:删除关联点类型。- DropGraph:删除图。- TruncateGraph:清空图。 |
status | 后台作业的状态,包括: - New:新建状态,表示该后台作业尚未开始执行。- Run:运行状态,表示该后台作业正在执行中。- PostRun:后处理状态,表示该后台作业执行完成后正在进行一些清理或后续准备操作。- Done:完成状态,表示该后台作业已成功执行并结束。- Exit:退出状态,表示该后台作业因某种原因异常退出。 |
information | 后台作业的说明描述。 |
示例 1
在 Leader 服务器节点上查询整个集群的所有后台作业的详细信息。命令如下:
SHOW JOBS;
返回结果示例如下:
+----------------------+----------+----------------+--------+--------------------------+
| job_id | graph_id | job_type | status | information |
+======================+==========+================+========+==========================+
| 333238970940924351 | 1025 | DropVertexType | New | person |
+----------------------+----------+----------------+--------+--------------------------+
| 13384229470587599607 | 1025 | DropPairs | New | person related pair |
+----------------------+----------+----------------+--------+--------------------------+
示例 2
在 Leader 服务器节点上查询 ID 为“333238970940924351”的后台作业的详细信息。命令如下:
SHOW JOBS 333238970940924351;
返回结果示例如下:
+----------------------+----------+----------------+--------+--------------------------+
| job_id | graph_id | job_type | status | information |
+======================+==========+================+========+==========================+
| 333238970940924351 | 1025 | DropVertexType | New | person |
+----------------------+----------+----------------+--------+--------------------------+
SHOW KEYWORDS
在 ArcGraph 图数据库中可使用 SHOW KEYWORDS 语句查看目前系统的保留关键字。保留关键字不建议作为对象名称使用,更多关于关键字的详细说明请参见 保留关键字 章节。
语法
SHOW KEYWORDS;
示例
查看当前系统的保留关键字,命令如下:
SHOW KEYWORDS;
SHOW MALLOC STATS
在 ArcGraph 图数据库中可使用 SHOW MALLOC STATS 语句查看系统目前收集的内存使用统计信息。这些统计信息对于 ArcGraph 图数据库的性能调优、资源规划等至关重要。请注意,仅 ArcGraph >= v2.1.1 版本支持此功能。
语法
SHOW MALLOC STATS [LIKE <"key">] [WHERE SERVER= <server_id>]
详细说明
| 参数 | 说明 |
|---|---|
[LIKE <"key">] | (可选)用于根据指定的关键字(key)过滤内存使用统计指标。如果省略,将返回所有内存使用统计指标。 |
[WHERE SERVER= <server_id>] | (可选)用于指定要查询的服务器节点 ID。如果省略,将返回集群中所有服务器下的内存使用统计信息。 |
结果说明
| 参数 | 说明 |
|---|---|
owner | 内存使用统计指标的所有者标识。 |
measurement | 内存使用统计的具体指标名称。 |
value | 内存使用统计指标的值。 |
server_id | 服务器的 ID。 |
server_address | 服务器提供服务的地址和端口号。 |
示例 1
查询系统目前收集的所有内存统计信息,命令如下:
SHOW MALLOC STATS;
返回结果示例如下:
+----------------+-------------+----------+-----------+-----------------+
| owner | measurement | value | server_id | server_address |
+================+=============+==========+===========+=================+
| background | current | 5.2 MB | 1 | 127.0.0.1:50051 |
+----------------+-------------+----------+-----------+-----------------+
| background | peak | 5.5 MB | 1 | 127.0.0.1:50051 |
+----------------+-------------+----------+-----------+-----------------+
| checkpoint | current | 50.4 KB | 1 | 127.0.0.1:50051 |
+----------------+-------------+----------+-----------+-----------------+
| checkpoint | peak | 86.1 KB | 1 | 127.0.0.1:50051 |
+----------------+-------------+----------+-----------+-----------------+
| global | current | 63.8 MB | 1 | 127.0.0.1:50051 |
+----------------+-------------+----------+-----------+-----------------+
| global | peak | 64.0 MB | 1 | 127.0.0.1:50051 |
+----------------+-------------+----------+-----------+-----------------+
| meta_service | current | 0 B | 1 | 127.0.0.1:50051 |
+----------------+-------------+----------+-----------+-----------------+
| meta_service | peak | 0 B | 1 | 127.0.0.1:50051 |
+----------------+-------------+----------+-----------+-----------------+
| partition_raft | current | 6.4 KB | 1 | 127.0.0.1:50051 |
+----------------+-------------+----------+-----------+-----------------+
| partition_raft | peak | 107.4 KB | 1 | 127.0.0.1:50051 |
+----------------+-------------+----------+-----------+-----------------+
| query_service | current | 210.0 KB | 1 | 127.0.0.1:50051 |
+----------------+-------------+----------+-----------+-----------------+
| query_service | peak | 346.3 KB | 1 | 127.0.0.1:50051 |
+----------------+-------------+----------+-----------+-----------------+
| raft | current | 987.6 KB | 1 | 127.0.0.1:50051 |
+----------------+-------------+----------+-----------+-----------------+
| raft | peak | 1.1 MB | 1 | 127.0.0.1:50051 |
+----------------+-------------+----------+-----------+-----------------+
| snap | current | 0 B | 1 | 127.0.0.1:50051 |
+----------------+-------------+----------+-----------+-----------------+
| snap | peak | 0 B | 1 | 127.0.0.1:50051 |
+----------------+-------------+----------+-----------+-----------------+
示例 2
查询服务器 ID 为“1”的机器上所有包含 query 关键字的内存使用统计信息。命令如下:
SHOW MALLOC STATS LIKE "query%" WHERE SERVER =1;
返回结果示例如下:
+---------------+-------------+----------+-----------+-----------------+
| owner | measurement | value | server_id | server_address |
+===============+=============+==========+===========+=================+
| query_service | current | 211.9 KB | 1 | 127.0.0.1:50051 |
+---------------+-------------+----------+-----------+-----------------+
| query_service | peak | 405.4 KB | 1 | 127.0.0.1:50051 |
+---------------+-------------+----------+-----------+-----------------+
SHOW METRICS
在 ArcGraph 图数据库中可使用 SHOW METRICS 语句查看当前系统收集的计数器指标信息,更多关于计数器指标的介绍请参见 计数器指标介绍 章节。
语法
SHOW [FULL] METRICS [LIKE <"key">] [[WHERE] SERVER= <server_id>]
详细说明
| 参数 | 说明 |
|---|---|
[FULL] | (可选)表示显示完整信息。如果省略,将只显示基本信息。 |
[LIKE <"key">] | (可选)用于根据指定的关键字(key)过滤计数器指标。如果省略,将返回所有计数器指标。 |
[[WHERE] SERVER= <server_id>] | (可选)用于指定要查询的服务器节点 ID。如果省略,将返回集群中所有服务器下的计数器指标。 |
示例 1
查询当前系统下所有计数器指标的基本信息,命令如下:
SHOW METRICS;
返回结果示例如下:
+-----------------------------------+-------+-----------+
| metric_name | value | server_id |
+===================================+=======+===========+
| tp_ddl.drop_index_success | 0 | 1 |
+-----------------------------------+-------+-----------+
| db_transaction.trans_commit | 0 | 1 |
+-----------------------------------+-------+-----------+
| tp_ddl.rename_graph_success | 0 | 1 |
+-----------------------------------+-------+-----------+
| tp_dml.update_edge_time | 0 | 1 |
+-----------------------------------+-------+-----------+
| db_grpc.meta_error_request | 1 | 1 |
+-----------------------------------+-------+-----------+
| tp_ddl.truncate_graph_success | 0 | 1 |
+-----------------------------------+-------+-----------+
| tp_ddl.drop_edge_type_success | 0 | 1 |
+-----------------------------------+-------+-----------+
| db_session.remove | 0 | 1 |
+-----------------------------------+-------+-----------+
| db_session.create_query | 2 | 1 |
+-----------------------------------+-------+-----------+
| tp_dml.delete_edges | 0 | 1 |
+-----------------------------------+-------+-----------+
| db_query.error | 0 | 1 |
+-----------------------------------+-------+-----------+
| db_grpc.meta_request | 4079 | 1 |
+-----------------------------------+-------+-----------+
| db_session.create | 1 | 1 |
+-----------------------------------+-------+-----------+
| tp_dml.insert_edge_time | 0 | 1 |
+-----------------------------------+-------+-----------+
| tp_dml.delete_vertex_time | 0 | 1 |
+-----------------------------------+-------+-----------+
| tp_dml.delete_edge_time | 0 | 1 |
+-----------------------------------+-------+-----------+
| tp_ddl.create_edge_type_success | 0 | 1 |
+-----------------------------------+-------+-----------+
| tp_dml.insert_vertex_time | 0 | 1 |
+-----------------------------------+-------+-----------+
| tp_dml.update_vertex_time | 0 | 1 |
+-----------------------------------+-------+-----------+
| db_session.close_query | 1 | 1 |
+-----------------------------------+-------+-----------+
| tp_dml.insert_edges | 0 | 1 |
+-----------------------------------+-------+-----------+
| db_session.kill_query | 0 | 1 |
+-----------------------------------+-------+-----------+
| tp_ddl.rename_schema_success | 0 | 1 |
+-----------------------------------+-------+-----------+
| tp_ddl.rename_property_success | 0 | 1 |
+-----------------------------------+-------+-----------+
| tp_ddl.drop_vertex_type_success | 0 | 1 |
+-----------------------------------+-------+-----------+
| tp_dml.update_vertexes | 0 | 1 |
+-----------------------------------+-------+-----------+
| tp_ddl.create_graph_success | 0 | 1 |
+-----------------------------------+-------+-----------+
| db_transaction.trans_rollback | 0 | 1 |
+-----------------------------------+-------+-----------+
| tp_dml.update_edges | 0 | 1 |
+-----------------------------------+-------+-----------+
| tp_ddl.drop_graph_success | 0 | 1 |
+-----------------------------------+-------+-----------+
| tp_dml.insert_vertexes | 0 | 1 |
+-----------------------------------+-------+-----------+
| db_session.kill | 0 | 1 |
+-----------------------------------+-------+-----------+
| tp_ddl.create_vertex_type_success | 0 | 1 |
+-----------------------------------+-------+-----------+
| tp_dml.delete_vertexes | 0 | 1 |
+-----------------------------------+-------+-----------+
| tp_dml.insert_vertex_time | 0 | 3 |
+-----------------------------------+-------+-----------+
| tp_dml.insert_edge_time | 0 | 3 |
+-----------------------------------+-------+-----------+
| tp_dml.update_edges | 0 | 3 |
+-----------------------------------+-------+-----------+
| tp_dml.delete_edge_time | 0 | 3 |
+-----------------------------------+-------+-----------+
| tp_ddl.rename_graph_success | 0 | 3 |
+-----------------------------------+-------+-----------+
| tp_ddl.drop_edge_type_success | 0 | 3 |
+-----------------------------------+-------+-----------+
| tp_ddl.drop_graph_success | 0 | 3 |
+-----------------------------------+-------+-----------+
| db_session.create | 0 | 3 |
+-----------------------------------+-------+-----------+
| tp_ddl.drop_index_success | 0 | 3 |
+-----------------------------------+-------+-----------+
| db_session.kill | 0 | 3 |
+-----------------------------------+-------+-----------+
| tp_ddl.rename_property_success | 0 | 3 |
+-----------------------------------+-------+-----------+
| db_session.kill_query | 0 | 3 |
+-----------------------------------+-------+-----------+
| db_transaction.trans_commit | 0 | 3 |
+-----------------------------------+-------+-----------+
| db_session.close_query | 0 | 3 |
+-----------------------------------+-------+-----------+
| tp_dml.insert_edges | 0 | 3 |
+-----------------------------------+-------+-----------+
| db_grpc.meta_request | 3801 | 3 |
+-----------------------------------+-------+-----------+
| tp_ddl.truncate_graph_success | 0 | 3 |
+-----------------------------------+-------+-----------+
| tp_ddl.create_vertex_type_success | 0 | 3 |
+-----------------------------------+-------+-----------+
| db_session.create_query | 0 | 3 |
+-----------------------------------+-------+-----------+
| tp_dml.delete_edges | 0 | 3 |
+-----------------------------------+-------+-----------+
| db_query.error | 0 | 3 |
+-----------------------------------+-------+-----------+
| db_grpc.meta_error_request | 20 | 3 |
+-----------------------------------+-------+-----------+
| tp_ddl.rename_schema_success | 0 | 3 |
+-----------------------------------+-------+-----------+
| db_transaction.trans_rollback | 0 | 3 |
+-----------------------------------+-------+-----------+
| tp_dml.update_vertex_time | 0 | 3 |
+-----------------------------------+-------+-----------+
| tp_dml.update_edge_time | 0 | 3 |
+-----------------------------------+-------+-----------+
| tp_dml.delete_vertexes | 0 | 3 |
+-----------------------------------+-------+-----------+
| tp_dml.update_vertexes | 0 | 3 |
+-----------------------------------+-------+-----------+
| tp_ddl.create_edge_type_success | 0 | 3 |
+-----------------------------------+-------+-----------+
| tp_ddl.drop_vertex_type_success | 0 | 3 |
+-----------------------------------+-------+-----------+
| db_session.remove | 0 | 3 |
+-----------------------------------+-------+-----------+
| tp_dml.insert_vertexes | 0 | 3 |
+-----------------------------------+-------+-----------+
| tp_ddl.create_graph_success | 0 | 3 |
+-----------------------------------+-------+-----------+
| tp_dml.delete_vertex_time | 0 | 3 |
+-----------------------------------+-------+-----------+
| db_grpc.meta_request | 4113 | 2 |
+-----------------------------------+-------+-----------+
| tp_dml.delete_edge_time | 0 | 2 |
+-----------------------------------+-------+-----------+
| db_transaction.trans_rollback | 0 | 2 |
+-----------------------------------+-------+-----------+
| tp_ddl.rename_property_success | 0 | 2 |
+-----------------------------------+-------+-----------+
| db_session.kill_query | 0 | 2 |
+-----------------------------------+-------+-----------+
| db_session.create_query | 0 | 2 |
+-----------------------------------+-------+-----------+
| tp_dml.insert_vertexes | 0 | 2 |
+-----------------------------------+-------+-----------+
| tp_ddl.rename_schema_success | 0 | 2 |
+-----------------------------------+-------+-----------+
| tp_dml.update_vertexes | 0 | 2 |
+-----------------------------------+-------+-----------+
| tp_dml.update_vertex_time | 0 | 2 |
+-----------------------------------+-------+-----------+
| tp_dml.update_edge_time | 0 | 2 |
+-----------------------------------+-------+-----------+
| tp_ddl.truncate_graph_success | 0 | 2 |
+-----------------------------------+-------+-----------+
| tp_ddl.drop_vertex_type_success | 0 | 2 |
+-----------------------------------+-------+-----------+
| db_query.error | 0 | 2 |
+-----------------------------------+-------+-----------+
| tp_dml.insert_vertex_time | 0 | 2 |
+-----------------------------------+-------+-----------+
| tp_ddl.create_graph_success | 0 | 2 |
+-----------------------------------+-------+-----------+
| tp_ddl.create_vertex_type_success | 0 | 2 |
+-----------------------------------+-------+-----------+
| tp_ddl.drop_edge_type_success | 0 | 2 |
+-----------------------------------+-------+-----------+
| tp_ddl.rename_graph_success | 0 | 2 |
+-----------------------------------+-------+-----------+
| db_session.close_query | 0 | 2 |
+-----------------------------------+-------+-----------+
| db_transaction.trans_commit | 0 | 2 |
+-----------------------------------+-------+-----------+
| tp_ddl.drop_graph_success | 0 | 2 |
+-----------------------------------+-------+-----------+
| db_grpc.meta_error_request | 20 | 2 |
+-----------------------------------+-------+-----------+
| db_session.kill | 0 | 2 |
+-----------------------------------+-------+-----------+
| tp_ddl.drop_index_success | 0 | 2 |
+-----------------------------------+-------+-----------+
| tp_dml.insert_edge_time | 0 | 2 |
+-----------------------------------+-------+-----------+
| tp_dml.delete_vertexes | 0 | 2 |
+-----------------------------------+-------+-----------+
| tp_dml.delete_vertex_time | 0 | 2 |
+-----------------------------------+-------+-----------+
| db_session.remove | 0 | 2 |
+-----------------------------------+-------+-----------+
| tp_ddl.create_edge_type_success | 0 | 2 |
+-----------------------------------+-------+-----------+
| tp_dml.update_edges | 0 | 2 |
+-----------------------------------+-------+-----------+
| tp_dml.delete_edges | 0 | 2 |
+-----------------------------------+-------+-----------+
| db_session.create | 0 | 2 |
+-----------------------------------+-------+-----------+
| tp_dml.insert_edges | 0 | 2 |
+-----------------------------------+-------+-----------+
结果说明:
| 参数 | 说明 |
|---|---|
metric_name | 计数器指标名称。 |
value | 计数器指标的值。 |
server_id | 计数器指标所在服务器的 ID。 |
示例 2
查询服务器 ID 为“1”的机器上所有包含 db_session 关键字的计数器指标。命令如下:
SHOW METRICS LIKE "%db_session%" WHERE SERVER =1;
返回结果示例如下:
+-------------------------+-------+-----------+
| metric_name | value | server_id |
+=========================+=======+===========+
| db_session.kill | 0 | 1 |
+-------------------------+-------+-----------+
| db_session.create_query | 8 | 1 |
+-------------------------+-------+-----------+
| db_session.kill_query | 0 | 1 |
+-------------------------+-------+-----------+
| db_session.close_query | 7 | 1 |
+-------------------------+-------+-----------+
| db_session.create | 2 | 1 |
+-------------------------+-------+-----------+
| db_session.remove | 1 | 1 |
+-------------------------+-------+-----------+
结果说明:
| 参数 | 说明 |
|---|---|
metric_name | 计数器指标名称。 |
value | 计数器指标的值。 |
server_id | 计数器指标所在服务器的 ID。 |
示例 3
查询服务器 ID 为“1”的机器上所有包含 db_session 关键字的计数器指标的全部信息。命令如下:
SHOW FULL METRICS LIKE "%db_session%" WHERE SERVER =1;
返回结果示例如下:
+-------------------------+-------+-----------+-----------------+----------------------------------------------------+
| metric_name | value | server_id | server_address | describe |
+=========================+=======+===========+=================+====================================================+
| db_session.kill | 0 | 1 | 127.0.0.1:50051 | Number of sessions killed |
+-------------------------+-------+-----------+-----------------+----------------------------------------------------+
| db_session.create_query | 9 | 1 | 127.0.0.1:50051 | Total number of queries created |
+-------------------------+-------+-----------+-----------------+----------------------------------------------------+
| db_session.kill_query | 0 | 1 | 127.0.0.1:50051 | Total number of queries killed |
+-------------------------+-------+-----------+-----------------+----------------------------------------------------+
| db_session.close_query | 8 | 1 | 127.0.0.1:50051 | Total number of closed queries (including kills) |
+-------------------------+-------+-----------+-----------------+----------------------------------------------------+
| db_session.create | 2 | 1 | 127.0.0.1:50051 | Total number of sessions created |
+-------------------------+-------+-----------+-----------------+----------------------------------------------------+
| db_session.remove | 1 | 1 | 127.0.0.1:50051 | Total number of removed sessions (including kills) |
+-------------------------+-------+-----------+-----------------+----------------------------------------------------+
结果说明:
| 参数 | 说明 |
|---|---|
metric_name | 计数器指标名称。 |
value | 计数器指标的值。 |
server_id | 计数器指标所在服务器的 ID。 |
server_address | 计数器指标所在服务器的 IP 地址及端口号。 |
describe | 计数器指标的描述。 |
SHOW PRIVILEGES
本章节将详细介绍在 ArcGraph 图数据库中如何使用 SHOW ROLE PRIVILEGES 及相关语句查看权限相关信息。
查看权限
查看所有角色或指定角色所拥有的全部权限。
语法
SHOW ROLE PRIVILEGES [LIKE '<role_name>'];
详细说明
| 参数 | 说明 |
|---|---|
[LIKE '<role_name>'] | (可选)用于指定关键字('<role_name>')并按关键字过滤查询结果。如果省略,将返回所有角色的权限。 |
'<role_name>' | 用户名称,用于指定将要操作的角色的名称。 说明: 命名大小写不敏感,小写字母将自动转换为大写显示,例如“user1”和“USER1”代表同一用户。 |
示例 1
SHOW ROLE PRIVILEGES;
返回结果示例如下:
+------------------------+----------------+-----------------+------------+-------------+-----------+---------------+
| role_name | privilege_type | privilege Level | graph_name | vertex_name | edge_name | property_name |
+========================+================+=================+============+=============+===========+===============+
| ADMIN | All | ALL | * | * | * | * |
+------------------------+----------------+-----------------+------------+-------------+-----------+---------------+
| _DEFAULT_ROLE_ARCGRAPH | All | Graph | new1_wd | * | * | * |
+------------------------+----------------+-----------------+------------+-------------+-----------+---------------+
| _DEFAULT_ROLE_ARCGRAPH | All | Graph | new1 | * | * | * |
+------------------------+----------------+-----------------+------------+-------------+-----------+---------------+
示例 2
SHOW ROLE PRIVILEGES LIKE 'admin';
返回结果示例如下:
+-----------+----------------+-----------------+------------+-------------+-----------+---------------+
| role_name | privilege_type | privilege Level | graph_name | vertex_name | edge_name | property_name |
+===========+================+=================+============+=============+===========+===============+
| ADMIN | All | ALL | * | * | * | * |
+-----------+----------------+-----------------+------------+-------------+-----------+---------------+
SHOW ROLES
本章节将详细介绍在 ArcGraph 图数据库中如何使用 SHOW ROLES 及相关语句查看角色相关信息。
查看角色
查看系统中所有的角色。
语法
SHOW ROLES;
示例
SHOW ROLES;
返回结果示例如下:
+------------------------+
| role_name |
+========================+
| ADMIN |
+------------------------+
| _DEFAULT_ROLE_ARCGRAPH |
+------------------------+
查看用户角色
查看所有用户或指定用户所拥有的全部角色。
语法
SHOW USER ROLES [LIKE '<user_name>']
详细说明
| 参数 | 说明 |
|---|---|
[LIKE '<user_name>'] | (可选)用于指定关键字('<user_name>')并按关键字过滤查询结果。如果省略,将返回所有用户的角色。 |
'<user_name>' | 用户名称,用于指定将要操作的用户的名称。 说明: 命名大小写不敏感,小写字母将自动转换为大写显示,例如“user1”和“USER1”代表同一用户。 |
示例 1
SHOW USER ROLES;
返回结果示例如下:
+-----------+------------------------+
| user_name | role_name |
+===========+========================+
| ARCGRAPH | _DEFAULT_ROLE_ARCGRAPH |
+-----------+------------------------+
| ARCGRAPH | ADMIN |
+-----------+------------------------+
示例 2
SHOW USER ROLES LIKE 'ARCGRAPH';
返回结果示例如下:
+-----------+------------------------+
| user_name | role_name |
+===========+========================+
| ARCGRAPH | _DEFAULT_ROLE_ARCGRAPH |
+-----------+------------------------+
| ARCGRAPH | ADMIN |
+-----------+------------------------+
SHOW SERVERS
在 ArcGraph 图数据库中使用 SHOW SERVERS 语句查看当前 ArcGraph 的服务器信息,包括服务器 ID、名称、IP 地址、服务器状态等关键信息。
语法
SHOW SERVERS;
示例
查询当前 ArcGraph 服务器信息,命令如下:
SHOW SERVERS;
返回结果示例如下:
+-----------+--------------+-----------+-----------------+------------------+----------------+----------------+--------+--------+
| server_id | name | ip | service_address | internal_address | raft_address | http_address | role | status |
+===========+==============+===========+=================+==================+================+================+========+========+
| 1 | computing-01 | 127.0.0.1 | 127.0.0.1:8182 | 127.0.0.1:50051 | 127.0.0.1:6001 | 127.0.0.1:7001 | leader | Online |
+-----------+--------------+-----------+-----------------+------------------+----------------+----------------+--------+--------+
结果说明:
| 参数 | 说明 |
|---|---|
server_id | 服务器的 ID。 |
name | 服务器的名称。 |
ip | 服务器的 IP 地址。 |
service_address | 服务器提供服务的地址和端口号。 |
internal_address | 服务器内部通信的地址和端口号。 |
raft_address | Raft 协议使用的地址和端口号。 |
http_address | HTTP 服务的地址和端口号,用于对外提供 RESTful API。 |
role | 服务器的角色,包括 leader 和 follower 两种角色。 - leader 服务器:ArcGraph 的主服务器,每个集群中仅有一台 leader 服务器,主要负责处理事务请求。 - follower 服务器:从属服务器,仅敏捷版 ArcGraph 支持,根据 ArcGraph 实际部署情况,每个集群中可以有多台 follower 服务器。它主要负责遵循 leader 服务器的指令和数据复制与备份。 |
status | 服务器的状态,包括 Online、Offline 和 Unavailable 三种状态。 - Online:表示服务器在线。 - Offline:表示服务器离线。 - Unavailable:表示服务器不可用。 |
SHOW SESSIONS
在图数据库中,Session(会话) 是指用户与数据库之间建立的通讯句柄(Handle)。每次用户连接到数据库时,都会启动一个新的会话,该会话将持续到用户断开连接或会话超时为止。Session 是用户执行一系列数据库操作的上下文,包括但不限于查询、插入、更新和删除等。
在 ArcGraph 图数据库中使用 SHOW SESSIONS 语句查看会话信息,使用 KILL <session_id> 终止会话,KILL <session_id> 详情请参见 终止会话 章节。
SHOW (PROCESSLIST | SESSIONS)
在 ArcGraph 图数据库中使用 SHOW (PROCESSLIST | SESSIONS) 语句查看整个集群上所有节点当前正在进行的会话信息。
语法
SHOW (PROCESSLIST | SESSIONS);
详细说明
SHOW PROCESSLIST 与 SHOW SESSIONS 功能相同,均用于查看整个集群所有节点当前正在进行的会话信息。
示例
查看整个集群所有节点当前正在进行的会话信息,命令如下:
SHOW SESSIONS;
返回结果示例如下:
+---------------------+----------+--------------------+--------------------------+--------------+----------+----------------+---------+---------------------+
| session_id | user_id | client_address | server_id|server_address | server_name | graph_id | command | state | create_time |
+=====================+==========+====================+==========================+==============+==========+================+=========+=====================+
| 7144883977613090808 | arcgraph | 127.0.0.1:54864 | 1|127.0.0.1:50051 | computing-01 | 0 | SHOW SESSIONS; | RUNNING | 2023-12-25 03:21:52 |
+---------------------+----------+--------------------+--------------------------+--------------+----------+----------------+---------+---------------------+
结果说明:
| 参数 | 说明 |
|---|---|
session_id | 会话 ID,唯一标识一个会话。 |
user_id | 会话的登录用户名称。 |
client_address | 会话对应的客户端 IP 地址和端口号。 |
server_id|server_address | 会话所在的服务器 ID 、IP 地址和端口号。 |
server_name | 会话所在的服务器名称。 |
graph_id | 会话正在使用的图 ID。 |
command | 会话当前正在执行的语句,空闲状态为 #。 |
state | 会话当前正在执行语句的状态,目前有如下 6 种状态。 - ERROR:表示会话在执行过程中遇到了错误,导致无法正常进行。 - PENDING: 表示会话处于等待状态,等待资源或其他条件满足后开始执行。 - RUNNING:表示会话正在执行中。 - FINISH:表示会话已成功完成执行。 - UNKNOWN:表示会话状态无法确定,可能是因为系统故障、通信中断或其他未知原因导致。 - SLEEP:表示会话处于休眠状态,没有操作正在进行,但会话仍然保持连接。如果会话长时间处于 SLEEP 状态可考虑终止会话,以释放资源,详情请参见详情请参见 终止会话 章节。 |
create_time | 会话创建时间。 |
SHOW CURRENT SESSION
在 ArcGraph 图数据库中可使用 SHOW CURRENT SESSION 语句查看当前会话的详细信息。
语法
SHOW CURRENT SESSION;
示例
查看当前会话的详细信息,命令如下:
SHOW CURRENT SESSION;
返回结果示例如下:
+---------------------+-----------+------------+-----------+-----------------+
| session_id | user_name | graph_name | server_id | server_address |
+=====================+===========+============+===========+=================+
| 7144883977613090808 | arcgraph | None | 1 | 127.0.0.1:50051 |
+---------------------+-----------+------------+-----------+-----------------+
结果说明:
| 参数 | 说明 |
|---|---|
session_id | 会话 ID,唯一标识一个会话。 |
user_name | 会话的登录用户名称。 |
graph_name | 会话正在使用的图名称。如果当前没使用任何图则 graph_name =None。 |
server_id | 会话所在的服务器 ID。 |
server_address | 会话所在的服务器 IP 地址和端口号。 |
SHOW STATS
自 ArcGraph v2.1.1 版本起, ArcGraph 图数据库中可使用 SHOW STATS 语句查看目前系统中图及图中点/边类型的统计信息。请注意,该统计信息并非实时更新,而是按照预设的更新频率进行更新,目前,统计信息的更新频率默认为每 60 分钟一次,可根据实际情况修改。
配置统计信息
通过 SHOW FULL CONFIGS 语句可以查看数据统计信息的当前配置情况,如更新频率、更新频率的更改等级、当前值、默认值、允许设置的最小值、允许设置的最大值以及其他相关信息等,详情请参见 SHOW CONFIGS 章节。
修改统计信息的配置有以下两种方式:
-
方式一:通过命令修改
使用ALTER CONFIG命令动态地修改统计信息的更新频率,单位为分钟。请注意,在修改更新频率后,新的设置并不会立即生效,而是需要等待当前已设定的更新周期完成后才会启动新的更新频率。更多操作请参考 更改系统配置项 章节。
示例ALTER CONFIG statistic_update_duration = 80; -
方式二:通过配置文件修改
server_config.toml配置文件中的[statistic]部分用于管理数据统计信息相关的配置,具体内容示例如下,用户可以在此处修改统计信息配置。操作前请确认已获取server_config.toml配置文件并拥有修改权限。[statistic]
stats_path = "./stats"
vertex_stats_name = "vertex_stat.json"
edge_stats_name = "edge_stat.json"
update_duration = 60 # minutes参数说明
参数 说明 stats_path用于指定统计信息保存的路径,默认值为“./stat ”。 vertex_stats_name用于指定点类型统计信息的文件名,默认值为“vertex_stat.json”。 edge_stats_name用于指定边类型统计信息的文件名,默认值为“edge_stat.json”。 update_duration统计信息的更新频率,单位为分钟,默认值为“60”,参数值设置范围为 1 到 1440 之间的整数。请注意,修改更新频率后,新设置将在当前周期结束后生效。
查看统计信息
查看 ArcGraph 图数据库所有图或某个图的统计信息,包括图名称、点/边类型名称、数量、点/边数据的数量及更新时间等。
语法
SHOW GRAPH [<graph_name> (VERTEX|EDGE [FULL])] STATS [WITH PARTITION];
详细说明
<graph_name>:(可选)指定需要查询的图名称。若未设置,则默认查询当前数据库下的所有图的统计信息。(VERTEX|EDGE [FULL]):(可选)指定查看图中点类型或边类型的统计信息。请注意,自 ArcGraph 图数据库 v2.1.2 版本起支持在查看边类型统计信息时增加FULL关键字,以查看更详细的边类型统计信息,包括边类型的关联点类�型等。[WITH PARTITION]:(可选)指定是否查看分区信息。
查看图的统计信息
查看 ArcGraph 图数据库所有图的统计信息,包括图名称、点/边类型数量、点/边数据的数量及更新时间等。
示例
查看 ArcGraph 图数据库所有图的统计信息。命令如下:
SHOW GRAPH STATS;
返回结果示例如下:
+--------------+-------------------+----------------+--------------+-----------+-------------------------+
| graph_name | vertexes_type_num | edges_type_num | vertexes_num | edges_num | update_time |
+==============+===================+================+==============+===========+=========================+
| SYSTEM | 11 | 2 | 16 | 0 | 2023-12-12 09:32:55.248 |
+--------------+-------------------+----------------+--------------+-----------+-------------------------+
| new2 | 1 | 1 | 4 | 2 | 2023-12-12 09:32:55.248 |
+--------------+-------------------+----------------+--------------+-----------+-------------------------+
查看点类型的统计信息
查看指定图中点类型的统计信息,包括点类型的名称、点数据的数量、更新时间等。如果点类型中没有数据,则不会显示在返回结果中。
示例
查看图“new2”中点类型的统计信息。命令如下:
SHOW GRAPH new2 VERTEX STATS;
返回结果示例如下:
+-------------+--------------+-------------------------+
| vertex_type | vertexes_num | update_time |
+=============+==============+=========================+
| person | 4 | 2023-12-12 09:32:55.248 |
+-------------+--------------+-------------------------+
查看边类型的统计信息
查看指定图中边类型的统计信息,包括边�类型的名称、边数据的数量、更新时间等。如果边类型中没有数据,则不会显示在返回结果中。
示例 1
查看图“new2”中边类型的统计信息。命令如下:
SHOW GRAPH new2 EDGE STATS;
返回结果示例如下:
+-----------+-----------+-------------------------+
| edge_type | edges_num | update_time |
+===========+===========+=========================+
| like | 2 | 2023-12-12 09:32:55.248 |
+-----------+-----------+-------------------------+
示例 2
当 ArcGraph >= v2.1.2 版本时,可以通过添加 FULL 关键字,查看图“new2”中边类型的详细统计信息,如包含关联点类型 from_vertex 和 to_vertex 的边统计信息。命令如下:
SHOW GRAPH new2 EDGE FULL STATS ;
返回结果示例如下:
+-----------+-------------+-----------+-----------+-------------------------+
| edge_type | from_vertex | to_vertex | edges_num | update_time |
+===========+=============+===========+===========+=========================+
| like | person | person | 1 | 2024-09-13 08:40:16.419 |
+-----------+-------------+-----------+-----------+-------------------------+
SHOW USERS
本章节将详细介绍在 ArcGraph 图数据库中如何使用 SHOW USERS 及相关语句查看用户相关信息。
查看用户
查看当前系统中的所有用户或指定用户。
语法
SHOW USERS [LIKE '<user_name>'];
详细说明
| 参数 | 说明 |
|---|---|
[LIKE '<user_name>'] | (可选)用于指定关键字('<user_name>')并按关键字过滤查询结果。如果省略,将返回所有用户。说明: 仅 ArcGraph >= v2.1.1 版本支持此参数。 |
'<user_name>' | 用户名称,用于指定将要操作的用户的名称。 说明: 命名大小写不敏感,小写字母将自动转换为大写显示,例如“user1”和“USER1”代表同一用户。 |
示例 1
查看当前系统中的所有用户,命令如下:
SHOW USERS;
返回结果示例如下:
+-----------+-------------------------+
| user_name | create_time |
+===========+=========================+
| ARCGRAPH | 2024-03-22 07:10:02.751 |
+-----------+-------------------------+
| USER1 | 2024-03-25 09:42:21.389 |
+-----------+-------------------------+
示例 2
查看指定用户,命令如下:
SHOW USERS LIKE 'user1';
返回结果示例如下:
+-----------+-------------------------+
| user_name | create_time |
+===========+=========================+
| USER1 | 2024-03-25 09:42:21.389 |
+-----------+-------------------------+
查看当前用户
查看当前登录用户。
语法
SHOW CURRENT USER;
示例
SHOW CURRENT USER;
返回结果示例如下:
+-----------+
| user_name |
+===========+
| ARCGRAPH |
+-----------+
SHOW VARIABLES
在 ArcGraph 图数据库中使用 SHOW VARIABLES 语句查看系统变量信息,并根据实际情况使用 SET SESSION|GLOBAL 语句修改系统变量值,详情请参见 更改系统变量 章节。
语法
SHOW VARIABLES;
示例
查询当前系统变量,命令如下:
SHOW VARIABLES;
返回结果示例如下:
+--------------------------------+-------+--------------+---------------+--------------------------------+---------------------+------+
| variable_name | value | modify_level | default_value | describe | max | min |
+================================+=======+==============+===============+================================+=====================+======+
| compiler_opt_enable_index_scan | true | DYNAMIC | true | compiler op enable index scan | None | None |
+--------------------------------+-------+--------------+---------------+--------------------------------+---------------------+------+
| computing_enable_property | false | DYNAMIC | false | computing enable property | None | None |
+--------------------------------+-------+--------------+---------------+--------------------------------+---------------------+------+
| compiler_max_var_hops | 20 | DYNAMIC | 8 | compiler neighbor task number | 2147483647 | 0 |
+--------------------------------+-------+--------------+---------------+--------------------------------+---------------------+------+
| computing_batch_scan_size | 20000 | DYNAMIC | 20000 | computing batch scan size | 4294967295 | 0 |
+--------------------------------+-------+--------------+---------------+--------------------------------+---------------------+------+
| computing_neighbor_task_num | 10 | DYNAMIC | 10 | computing neighbor task number | 9223372036854775807 | 0 |
+--------------------------------+-------+--------------+---------------+--------------------------------+---------------------+------+
| computing_batch_send_size | 1000 | DYNAMIC | 1000 | computing batch send size | 9223372036854775807 | 0 |
+--------------------------------+-------+--------------+---------------+--------------------------------+---------------------+------+
| computing_batch_neighbor_size | 20000 | DYNAMIC | 20000 | computing batch neighbor size | 9223372036854775807 | 0 |
+--------------------------------+-------+--------------+---------------+--------------------------------+---------------------+------+
| request_timeout | 30000 | DYNAMIC | 30000 | request timeout(ms) | 9223372036854775807 | 0 |
+--------------------------------+-------+--------------+---------------+--------------------------------+---------------------+------+
结果说明:
| 参数 | 说明 |
|---|---|
variable_name | 系统变量的名称。 |
value | 系统变量的值。 |
modify_level | 系统变量的更改等级,包括 STATIC 和 DYNAMIC 两种。- STATIC:配置不可以通过动态指令修改。- DYNAMIC:配置可以通过动态指令(如 ALTER)进行修改。 |
default_value | 系统变量的默认值。 |
describe | 系统变量的描述信息。 |
max | 系统变量允许设置的最大值。 |
min | 系统变量允许设置的最小值。 |
SHOW VERSION
在 ArcGraph 图数据库中使用 SHOW VERSION 语句查看当前 ArcGraph 版本。
语法
SHOW VERSION;
示例
查询当前 ArcGraph 版本,命令如下:
SHOW VERSION;
返回结果示例如下:
+-------------------------+
| version |
+=========================+
| 2.1.0-feature-46c246308 |
+-------------------------+
SHOW VERTEXES
本章节将详细介绍在 ArcGraph 图数据库中如何使用 SHOW VERTEXES 及相关语句查看点类型相关信息。
查看点类型
使用 SHOW VERTEXES 命令查看当前图中所有的点类型。
语法
SHOW [FULL] VERTEXES;
详细说明
| 参数 | 说明 |
|---|---|
[FULL] | (可选)用于展示点类型的详细信息。如果省略,将只展示点类型名称。 说明: 仅 ArcGraph >= v2.1.1 版本支持此参数。 |
结果说明
| 参数 | 说明 |
|---|---|
vertex_type_name | 点类型名称。 自 ArcGraph v2.1.2 版本起,执行 SHOW FULL VERTEXES; 命令时可以查看已删除但未回收的点类型。这些点类型的 ID 不变,但名字会被定义为 _{name}_{timestamp} 格式,如 _person_1724922449757360。 |
vertex_type_id | 点类型的唯一标识符,用于区分不同的点类型。 |
location | 点类型在 ArcGraph 图数据库中的存储位置。 |
status | 点类型的状态,支持以下三种状态:
|
data_version | 点类型的数据版本号,用于记录点类型的数据变更历史。 |
schema_version | 点类型的 Schema 版本号,用于记录点类型的 Schema 变更历史。 |
示例 1
在当前图中查看所有点类型,命令如下:
SHOW VERTEXES;
返回结果示例如下:
+------------------+
| vertex_type_name |
+==================+
| person |
+------------------+
示例 2
在当前图中查看所有点类型的详细信息,命令如下:
SHOW FULL VERTEXES;
返回结果示例如下:
+------------------+----------------+------------------------+--------+--------------+----------------+
| vertex_type_name | vertex_type_id | location | status | data_version | schema_version |
+==================+================+========================+========+==============+================+
| person | 1 | [127.0.0.1:50051([0])] | Normal | 0 | 0 |
+------------------+----------------+------------------------+--------+--------------+----------------+
示例 3
当 ArcGraph >= v2.1.2 版本时,在当前图中查看包括已删除点类型在内的所有点类型的详细信息,命令如下:
SHOW FULL VERTEXES;
返回结果示例如下:
+--------------------------+----------------+------------------------+---------+--------------+----------------+
| vertex_type_name | vertex_type_id | location | status | data_version | schema_version |
+==========================+================+========================+=========+==============+================+
| _person_1724922449757360 | 1 | [127.0.0.1:50051([0])] | Deleted | 8 | 15 |
+--------------------------+----------------+------------------------+---------+--------------+----------------+
| person_test | 2 | [127.0.0.1:50051([0])] | Normal | 0 | 0 |
+--------------------------+----------------+------------------------+---------+--------------+----------------+